

一个实习生亲历的Manus外迁与裁员
一个实习生亲历的Manus外迁与裁员“Manus跑路”的新闻席卷社交媒体时,我正在旅行途中。“败落”“润了”等词汇,刺得我本能地关掉了页面。 多数媒体用“突然”“惊爆”等词形容Manus的搬迁,作为内部人员,其实在6月就隐约感知到这一动向。
来自主题: AI资讯
8164 点击 2025-08-06 13:46
“Manus跑路”的新闻席卷社交媒体时,我正在旅行途中。“败落”“润了”等词汇,刺得我本能地关掉了页面。 多数媒体用“突然”“惊爆”等词形容Manus的搬迁,作为内部人员,其实在6月就隐约感知到这一动向。
忘掉繁琐交互流程,也不用再蹲Veo 3了! 现在分钟级高质量的AI创意大片,能够一键生成了。 比如一张人物图+提示词脚本,就能生成记者第一视角下采访西游记的视频特辑。

AI 作图,不止卖家在用,买家也在用。最近,不少网友晒出了一个令人啼笑皆非的操作:为了从卖家那里占到一点便宜,一些买家会故意声称商品有瑕疵,并要求退款。但其实,瑕疵图是他们自己用 AI 做的,比如把好的榴莲做成腐烂掉的榴莲。
Huxe 是您的个人音频伴侣,旨在将您关心的一切,转化为精心生成的交互式体验。

SkinVision 是一家于 2011 年在荷兰阿姆斯特丹成立的数字健康公司,致力于通过人工智能(AI)驱动的移动解决方案,实现皮肤癌的早期检测与个性化皮肤健康管理。
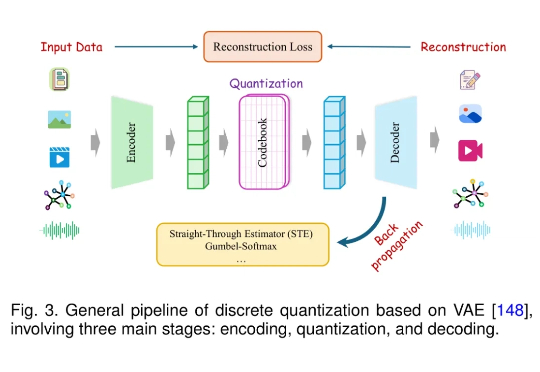
近年来,大语言模型(LLM)在语言理解、生成和泛化方面取得了突破性进展,并广泛应用于各种文本任务。随着研究的深入,人们开始关注将 LLM 的能力扩展至非文本模态,例如图像、音频、视频、图结构、推荐系统等。
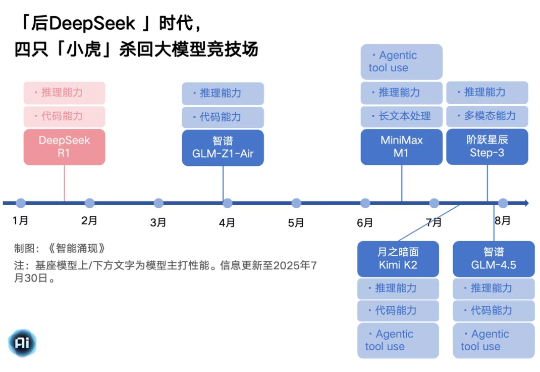
沉寂了长达半年之后,“AI六小虎”中有4家,用接连发布的新模型,又杀回了模型竞技场。就在半年前,六小虎的命题,还是“失败”。
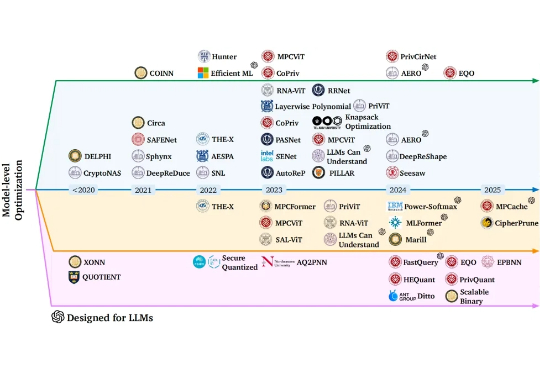
在数据隐私日益重要的 AI 时代,如何在保护用户数据的同时高效运行机器学习模型,成为了学术界和工业界共同关注的难题。

Science重磅揭露科研圈两大乱象:一是「论文工厂」已形成庞大产业链,部分编辑、作者、中介相互勾结;二是ChatGPT悄然渗入科研写作,22%计算机论文含AI痕迹。系统性造假与技术滥用,正重塑学术界根基。

在 2025 年第二季度财报中,Palantir 交出了一份几乎所有 SaaS 从业者都梦寐以求的成绩单:美国商业业务收入同比增长 93%、总收入突破 10 亿美元、调整后经营利润率 46%、自由现金流利润率 57%、Rule of 40 指数高达 94%。