
今天,美图造了一支AI影像团队!
今天,美图造了一支AI影像团队!一口气发布了八款产品。
来自主题: AI资讯
8470 点击 2026-06-18 12:00
 搜索
搜索
一口气发布了八款产品。

大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。
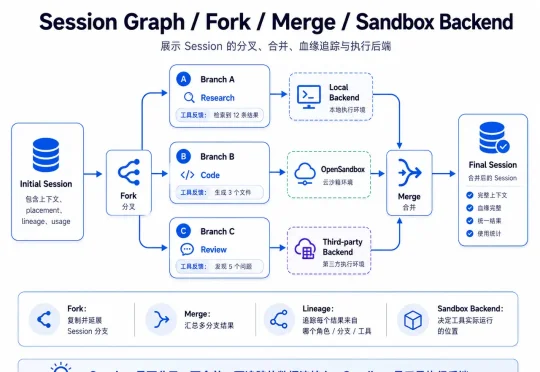
最近,一个来自清华大学与中山大学的团队(Rath Team)把他们的解法开源了,叫OpenRath:这是一个像PyTorch的多智能体、多会话运行时。它的主张是:别再围着Agent转了。真正该被当成一等公民的,是Session。

Salesforce 公司已同意以约 36 亿美元收购 Fin——一家开发人工智能驱动型顾客服务代理的公司,这家软件企业正致力于为企业级 AI 赢得新业务。Fin 的旗舰产品 AI Agent 可通过聊天、电子邮件、WhatsApp、短信、短信、电话和 Slack 处理顾客查询。

2026年,飞书新增客户中有九成同时采购飞书AI产品。
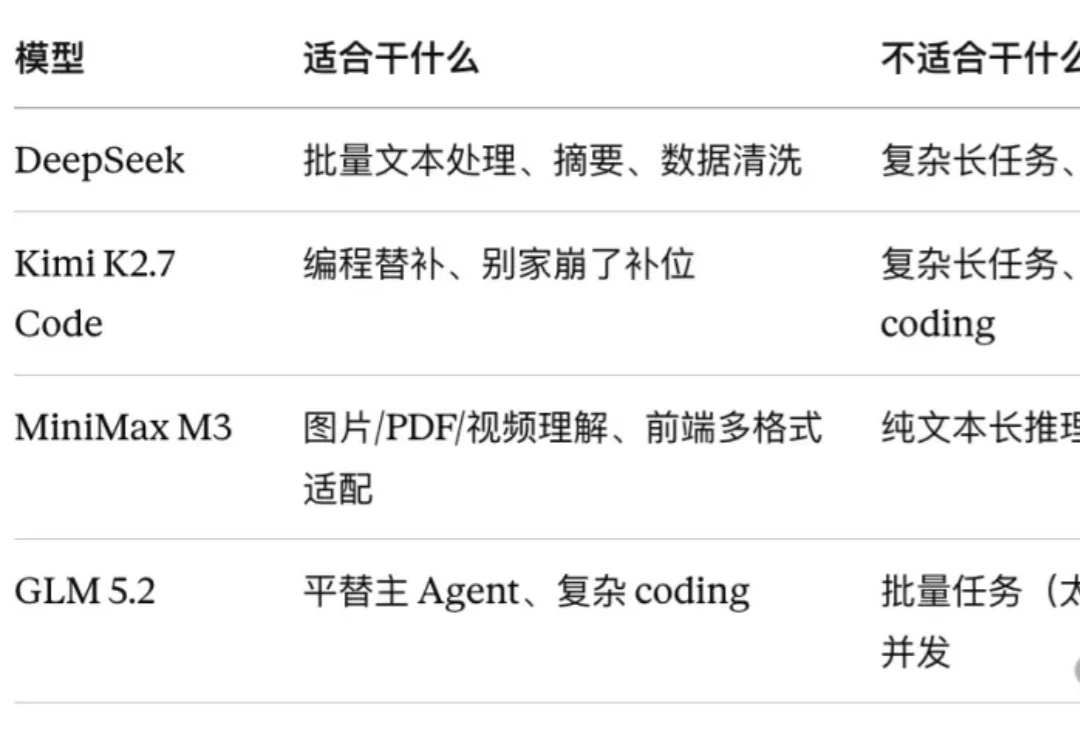
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。

究竟谁将率先点燃AI游戏这把火?
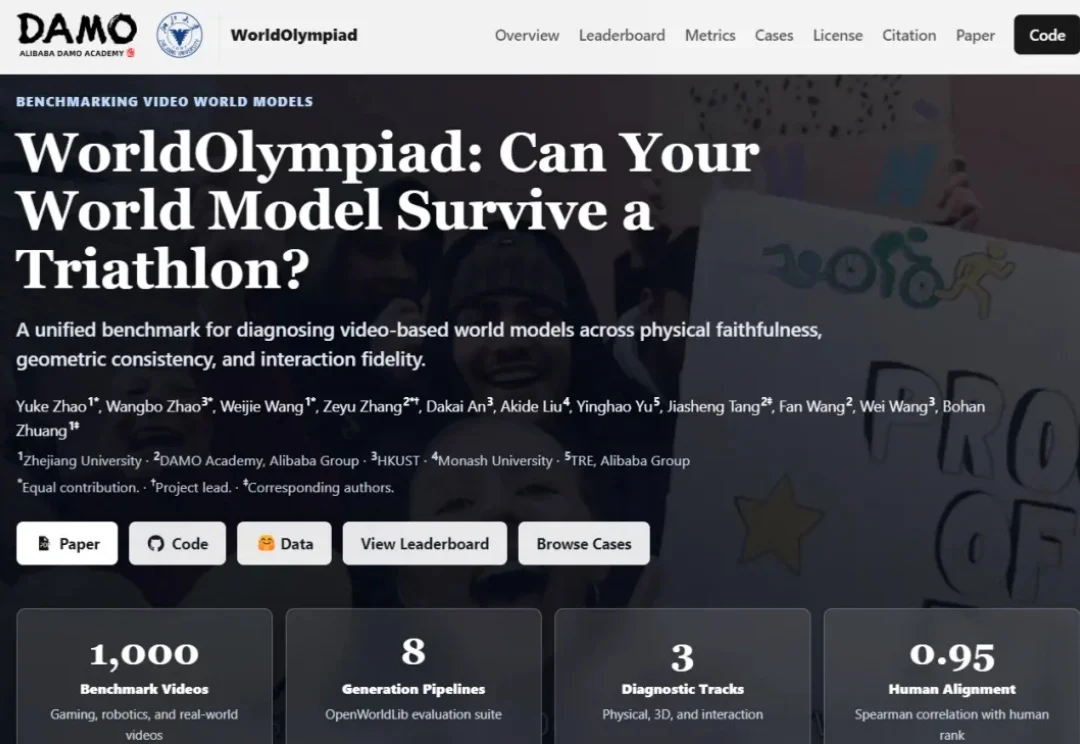
达摩院联合高校推出WorldOlympiad评测基准,跳出传统视频“唯画质”的评价逻辑,以物理真实性、三维几何一致性、长时序交互保真度三大维度,搭配游戏、机器人、通用实景三大场景,打造一套全方位的视频世界模型评测体系。

偷师、借道、换血、误删……折腾到最后,xAI成了给对手供电的人。

卧槽,这事真的太抽象了。