
Coinbase强制全员上手AI工具,拒绝者直接开除
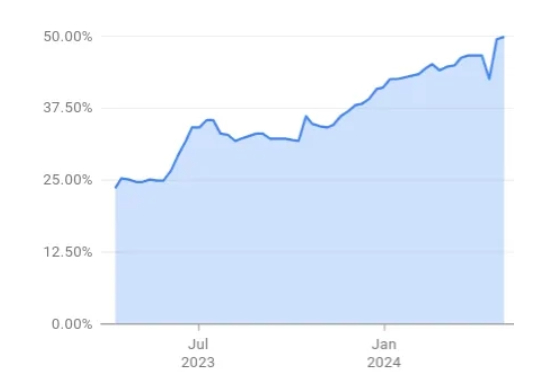
Coinbase强制全员上手AI工具,拒绝者直接开除LLM 发展至今,编程能力已经非常强大,成为了很多开发者和软件工程师的「标配」,甚至谷歌还曾宣称其 50% 的代码都是 AI 编写的。
来自主题: AI资讯
8592 点击 2025-08-23 16:17
LLM 发展至今,编程能力已经非常强大,成为了很多开发者和软件工程师的「标配」,甚至谷歌还曾宣称其 50% 的代码都是 AI 编写的。
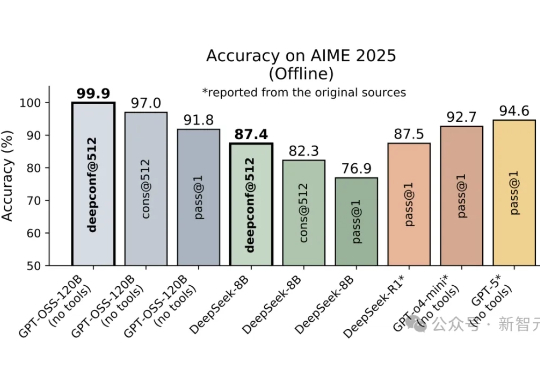
DeepConf由Meta AI与加州大学圣地亚哥分校提出,核心思路是让大模型在推理过程中实时监控置信度,低置信度路径被动态淘汰,高置信度路径则加权投票,从而兼顾准确率与效率。在AIME 2025上,它首次让开源模型无需外部工具便实现99.9%正确率,同时削减85%生成token。
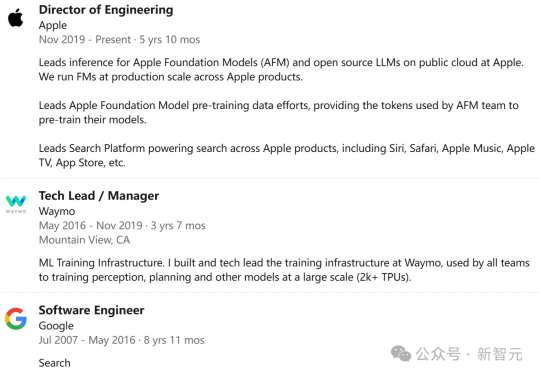
苹果AI再遭重创,核心工程师Frank Chu被曝加入Meta!与此同时,Meta也在豪掷重金招募超50名顶尖人才后,宣布紧急冻结招聘。

近年来,以多智能体系统(MAS)为代表的研究取得了显著进展,在深度研究、编程辅助等复杂问题求解任务中展现出强大的能力。现有的多智能体框架通过多个角色明确、工具多样的智能体协作完成复杂任务,展现出明显的优势。

刚刚,OpenAI 重大的权力结构调整曝光。 The Verge 报道称,OpenAI CEO Sam Altman 将把公司的大部分日常运营,交给 5 月任命的应用业务 CEO Fidji Simo。
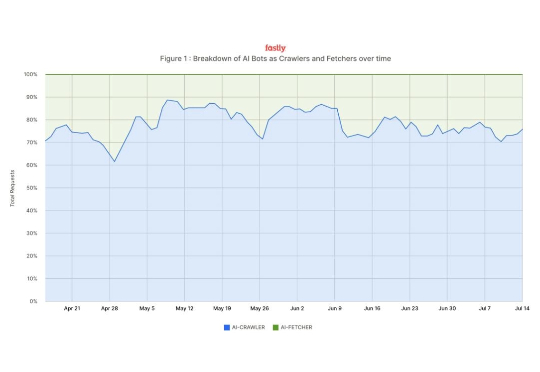
“我的网站被爬崩了,自己要付流量费,人家却用我的内容训练出 AI 模型,还赚足了眼球。” 自从 AI 机器人开始流行,很多网站开发者叫苦不堪。而近日,云服务巨头 Fastly 发布的一份报告让人看完直呼“现实往往我们仅听到的部分更为残酷。”
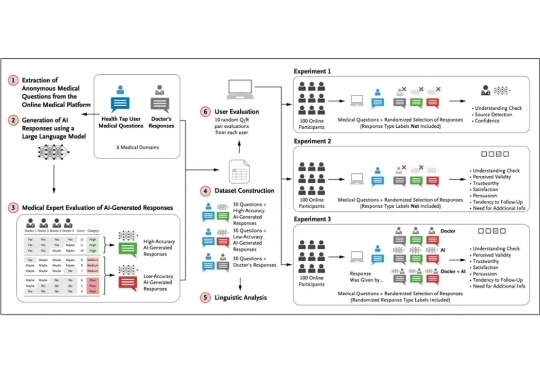
就连医生也未必能区分AI给出的建议与自己的建议 美国正面临医生短缺危机。在权威期刊《新英格兰医学杂志》10月刊中,哈佛医学院教授Isaac Kohane提到,马萨诸塞州是美国人均医生数量最多的州,但该州多家大型医院已拒绝接收新患者。

在本周MIT报告揭露“绝大多数企业投资AI尚未盈利”引发市场哗然之际,另一项出乎意料的现象也浮出水面:企业部署先进人工智能成本下降的趋势在2025年突然停滞。
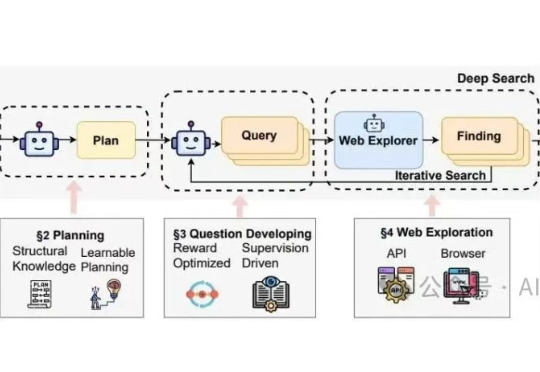
华为诺亚方舟实验室最近联合香港大学发了一篇针对"Deep Research Agents"(深度研究代理)的系统性综述,在我的印象中,这是他们第二次发布关于Deep Research的综述论文。上一篇里提供了一个结构导向 (Structure-Oriented) 的视角,核心是“分类”。
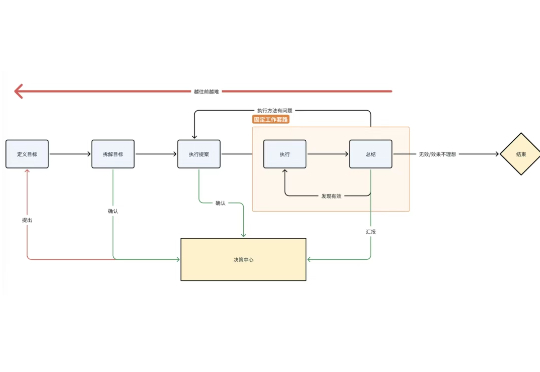
AI 同事、AI 数字员工的呼声越来越高,但至今仍没看到很好的落地。这其中的难点和瓶颈到底在哪里? AI 数字员工,真的是一个值得追求的目标吗?