
华为重金押注的世界模型公司,新融了10个亿!
华为重金押注的世界模型公司,新融了10个亿!资本正在加速押注具身智能的下一阶段。
来自主题: AI资讯
9493 点击 2026-03-05 14:57
 搜索
搜索
资本正在加速押注具身智能的下一阶段。

伴随多模态大模型的发展,GUI Agent正成为人机交互的新范式。
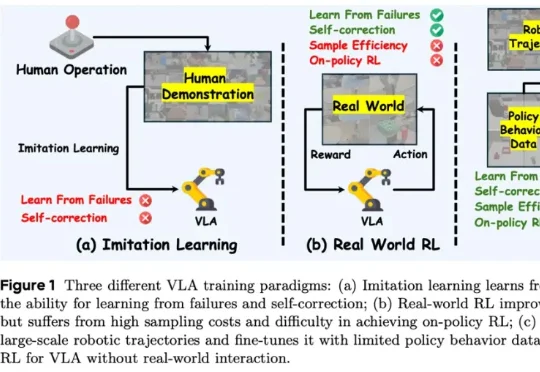
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。

机器之心编辑部 整个具身智能领域都在探索世界模型的实用化路径。这个被寄予厚望的「数字模拟器」,本应成为机器人训练的核心工具,却因物理保真度低等问题成为「空中楼阁」。 去年年中,谷歌发布了 Genie-

医疗AI终于走出了「只会聊天」的舒适区。今天,斯坦福与普林斯顿联手NVIDIA发布MedOS。这不是一个单纯的手术机器人,而是全球首个通用医疗具身世界模型。从临床诊断到治疗,从外科手术到药物研发,MedOS正在让AI真正读懂「生老病死」的物理现实。

极佳视界具身大模型 GigaBrain-0.5M*,以世界模型预测未来状态驱动机器人决策,并实现了持续自我进化,超越π*0.6 实现 SOTA!该模型在叠衣、冲咖啡、折纸盒等真实任务中实现接近 100% 成功率;相比主流基线方法任务成功率提升近 30%;基于超万小时数据训练,其中六成由自研世界模型高保真合成。
这家AI独角兽累计拿下56亿融资。

驱动具身智能进入通用领域最大的问题在哪里?
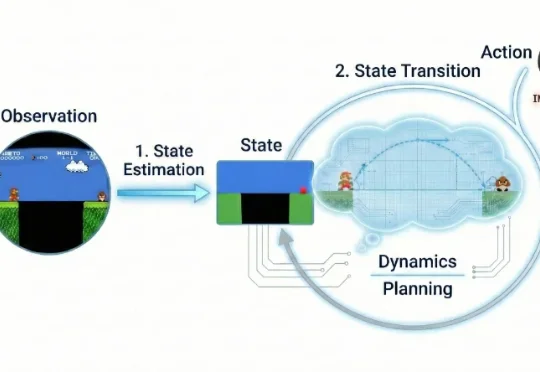
近年来,视频生成(Video Generation)与世界模型(World Models)已跃升为人工智能领域最炙手可热的焦点。从 Sora 到可灵(Kling),视频生成模型在运动连续性、物体交互与部分物理先验上逐渐表现出更强的「世界一致性」,让人们开始认真讨论:能否把视频生成从「逼真短片」推进到可用于推理、规划与控制的「通用世界模拟器」。
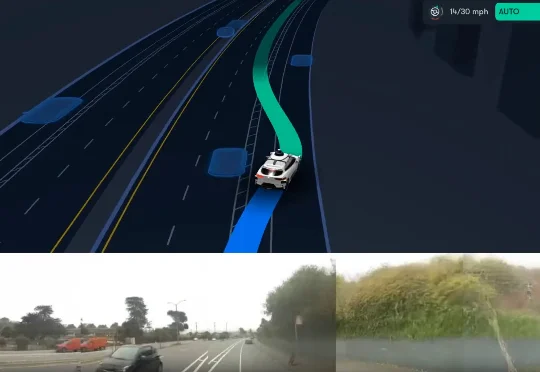
刚刚,Alphabet 旗下的自动驾驶汽车公司 Waymo,推出了最新世界模型 Waymo World Model,其基于 DeepMind 的 Genie 3 构建,在大规模、超真实自动驾驶仿真方面树立了全新的行业标杆。