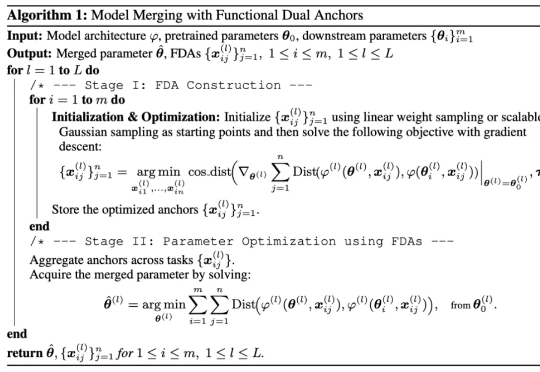
FDA对偶锚点:模型知识迁移的新视角——从参数空间到输入空间
FDA对偶锚点:模型知识迁移的新视角——从参数空间到输入空间研究者们提出了 FDA(Model Merging with Functional Dual Anchors)——一个全新的模型融合框架。与传统的参数空间操作不同,FDA 将专家模型的参数知识投射到输入-表征空间中的合成锚点,通过功能对偶的方式实现更高效的知识整合。
来自主题: AI技术研报
8255 点击 2025-11-14 13:57
 搜索
搜索
研究者们提出了 FDA(Model Merging with Functional Dual Anchors)——一个全新的模型融合框架。与传统的参数空间操作不同,FDA 将专家模型的参数知识投射到输入-表征空间中的合成锚点,通过功能对偶的方式实现更高效的知识整合。

稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。
我们先给不知道剧情的朋友回归一下事件事件线:2025年6月30日,华为宣布开源盘古7B稠密和72B混合专家模型。然而发布会后,网络上出现华为盘古大模型抄袭的言论。7月5日,诺亚方舟实验室发布《关于盘古大模型开源代码相关讨论的声明》。本以为官方已经出来站台,这件事到此为止。

7月5日下午16:59分,隶属于华为的负责开发盘古大模型的诺亚方舟实验室发布声明对于“抄袭”指控进行了官方回应。诺亚方舟实验室表示,盘古Pro MoE开源模型是基于昇腾硬件平台开发、训练的基础大模型,并非基于其他厂商模型增量训练而来,在架构设计、技术特性等方面做了关键创新,是全球首个面向昇腾硬件平台设计的同规格混合专家模型
最近,看到各大厂商,在不断地将自己的AI大模型进行开源。华为宣布开源:盘古7B稠密和72B混合专家模型。

刚刚,华为正式宣布开源盘古 70 亿参数的稠密模型、盘古 Pro MoE 720 亿参数的混合专家模型(参见机器之心报道:华为盘古首次露出,昇腾原生72B MoE架构,SuperCLUE千亿内模型并列国内第一 )和基于昇腾的模型推理技术。

要问最近哪个模型最火,混合专家模型(MoE,Mixture of Experts)绝对是榜上提名的那一个。
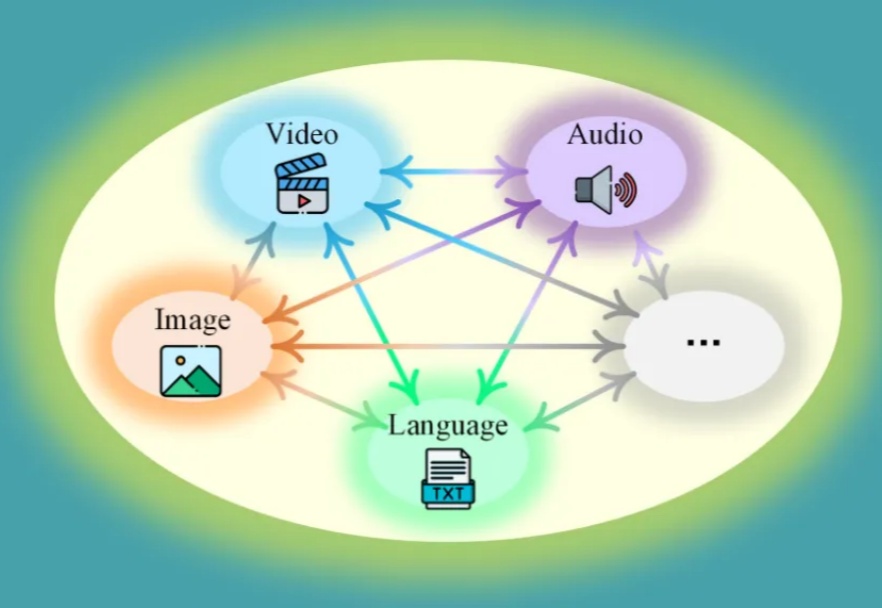
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。
DeepSeek 开源周的第三天,带来了专为 Hopper 架构 GPU 优化的矩阵乘法库 — DeepGEMM。这一库支持标准矩阵计算和混合专家模型(MoE)计算,为 DeepSeek-V3/R1 的训练和推理提供强大支持,在 Hopper GPU 上达到 1350+FP8 TFLOPS 的高性能。

DeepSeek 本周正在连续 5 天发布开源项目,今天是第 2 天,带来了专为混合专家模型(MoE)和专家并行(EP)打造的高效通信库 — DeepEP。就在半小时前,官方对此进行了发布,以下是由赛博禅心带来的详解。