![[翻译] AI Agent 的 Zero Trust 框架|Anthropic 安全白皮书](https://www.aitntnews.com/pictures/2026/5/28/a5aa95a5-5a65-11f1-add0-fa163e47d677.webp)
[翻译] AI Agent 的 Zero Trust 框架|Anthropic 安全白皮书
[翻译] AI Agent 的 Zero Trust 框架|Anthropic 安全白皮书Zero Trust 是一套安全架构,核心前提很简单:不信任任何东西,必须验证一切
来自主题: AI资讯
10064 点击 2026-05-28 15:12
 搜索
搜索
Zero Trust 是一套安全架构,核心前提很简单:不信任任何东西,必须验证一切
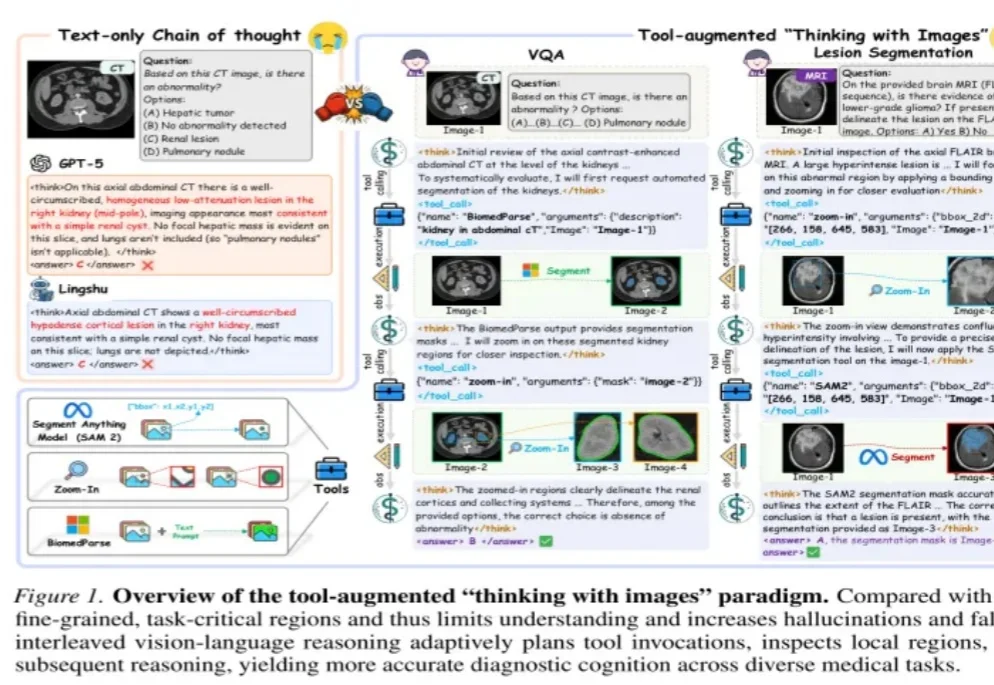
医学AI会写解释,但不代表它真的“看到”了关键证据。

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。

当下视频生成模型正在快速逼近真实世界的画面质感,但一个现实瓶颈也越来越突出—— 那就是分辨率越高,生成所需要的时间就越长。

一个号称「零污染」的新基准 DeepSWE,用113道原创题撕开了旧编程榜单的遮羞布。

刚刚,英伟达再次甩出一份炸裂财报:单季营收816亿美元,光数据中心一项就占了92%。但真正应当注意的,是财报中一个一年翻了近29倍的数字。它背后,是英伟达正在悄悄完成的身份转换:从「卖铲子的人」,变成整条AI产业链的「收租人」。
迈入今年618大促周期,各大电商平台纷纷加码AI购物,智能选购成为各家角逐的新焦点。
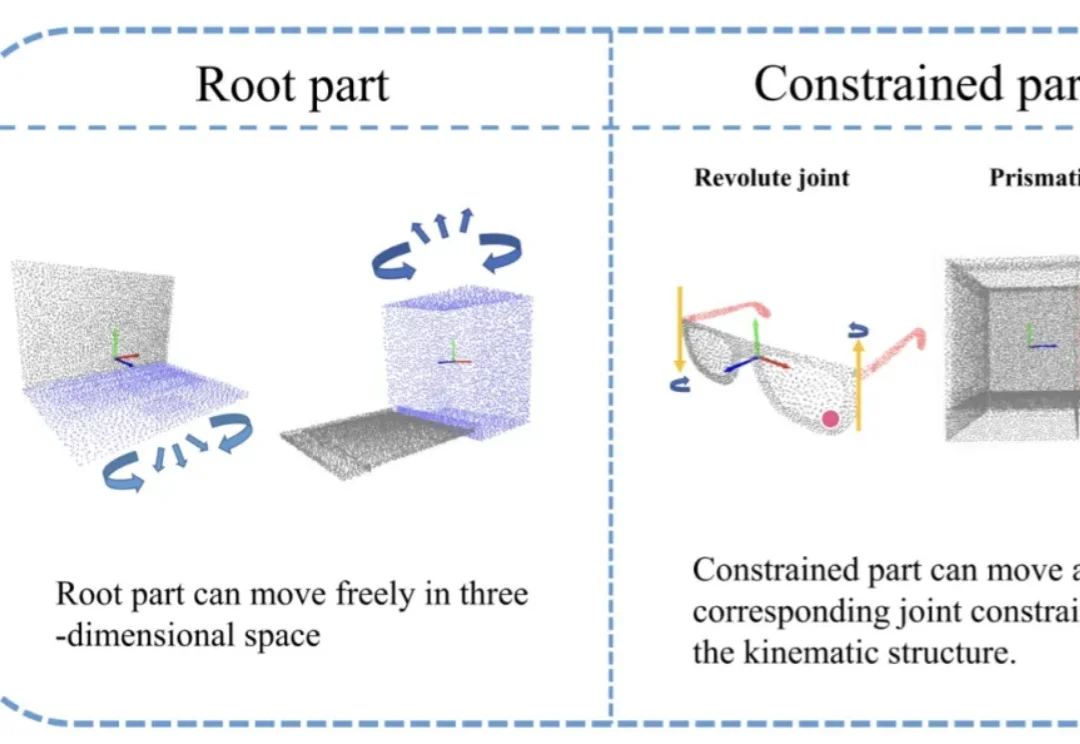
在具身智能快速发展的今天,机器人已经不再满足于「看见」刚体物体,而是开始真正走向复杂环境中的交互与操作。从机械臂开柜门,到服务机器人整理抽屉,再到工业场景中的工具操作,大量真实世界目标都属于关节物体(Articulated Objects)。
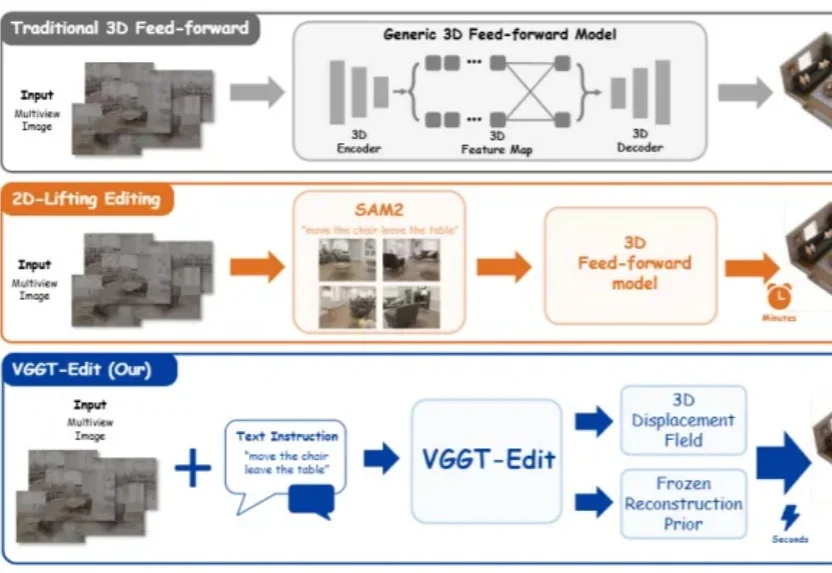
3D世界“会看”了,但还不会“改”。

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。