春晚之后,AI和机器人为啥都去了一个地方?
春晚之后,AI和机器人为啥都去了一个地方?2026年的除夕夜,AI技术第一次以如此密集的方式进入全民文化场景。很多观众或许说不清技术原理,但一定记住了那几个关键词:AI、机器人、具身智能。然而,对于身处其中的科技大厂和独角兽们来说,焦虑并没有随着《难忘今宵》的响起而消散。
来自主题: AI资讯
9522 点击 2026-02-20 12:34
 搜索
搜索
2026年的除夕夜,AI技术第一次以如此密集的方式进入全民文化场景。很多观众或许说不清技术原理,但一定记住了那几个关键词:AI、机器人、具身智能。然而,对于身处其中的科技大厂和独角兽们来说,焦虑并没有随着《难忘今宵》的响起而消散。

进入 AI 时代之后,这件事开始被反复拿出来讨论。如果内容不只是被看,而是可以被「操作」、被「玩」,那它还算不算我们熟悉的内容平台?最近一两天,这个问题突然被推到了舆论场的正中央。
谷歌在 7.5 亿月活的 Gemini 中上线了 AI 音乐生成功能,输入一句话或一张照片,几秒就能得到一首带人声和歌词的完整歌曲。背后是 DeepMind 最新的 Lyria 3 模型,训练数据超 200 万首曲目。对 Suno 等 AI 音乐创业公司而言,竞争从此不再只是比模型,更是要比入口。
这次的 Kimi Claw,其实已经把 ClawHub 里的 Skills 全都接进来了。你可以直接用一句话,让它在浏览器里把需要的 Skills 装到云端环境里,不用自己折腾配置,也不用手动一堆步骤。

1970年,一个叫Gordon Gallup的心理学家把一面镜子放进了黑猩猩的笼子里。黑猩猩一开始对着镜子龇牙。它以为那是另一只黑猩猩。它威胁它,拍胸脯,绕到镜子后面找那只不存在的敌人。

这一届上台的机器人各有各的路子——有的走仿生路线,模仿起人来连神态都安排上了;有的直接拼运动能力,一整套动作打下来,现场效果确实很炸。但如果你这一年已经看过太多机器人 demo,其实也不会太惊讶。春晚这个舞台,本来就是要把「最能表演的东西」集中展示出来。
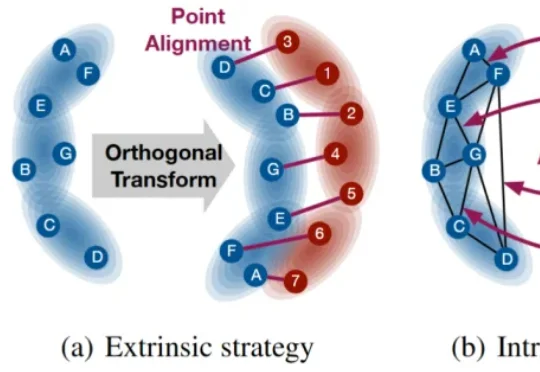
本文提出一种具有 SE(p) 不变传输性质的度量 SEINT:通过构造无需训练的 SE(p) 不变表示,将高维结构信息压缩为可用于 Optimal Transport (OT) 对齐的一维表征,从而在保持不变性与严格度量性质的同时显著提升效率。
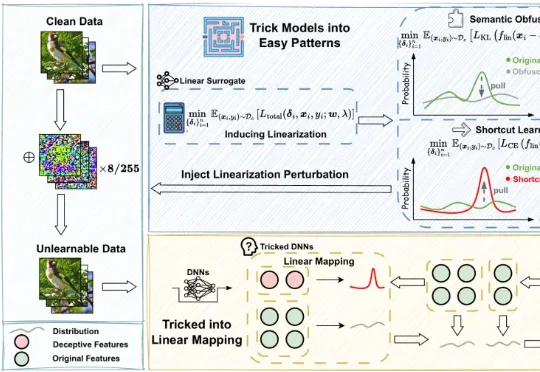
不可学习样本(Unlearnable Examples)是一类用于数据保护的技术,其核心思想是在原始数据中注入人类难以察觉的微小扰动,使得未经授权的第三方在使用这些数据训练模型时,模型的泛化性能显著下降,甚至接近随机猜测,从而达到阻止数据被滥用的目的。
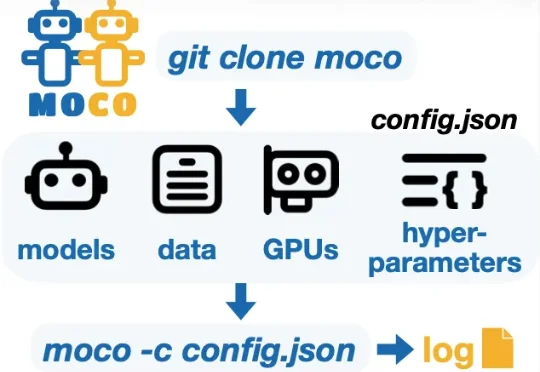
为了支持多模型协同研究并加速这一未来愿景的实现,华盛顿大学 (University of Washington) 冯尚彬团队联合斯坦福大学、哈佛大学等研究人员提出 MoCo—— 一个针对多模型协同研究的 Python 框架。MoCo 支持 26 种在不同层级实现多模型交互的算法,研究者可以灵活自定义数据集、模型以及硬件配置,比较不同算法,优化自身算法,以此构建组合式人工智能系统。MoCo 为设计、

千问 3.5 总参数量仅 3970 亿,激活参数更是只有 170 亿,不到上一代万亿参数模型 Qwen3-Max 的四分之一,性能大幅提升、还顺带实现了原生多模态能力的代际跃迁。