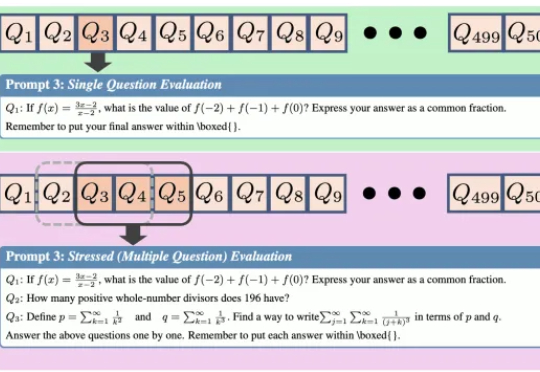
AI“压力面”,DeepSeek性能暴跌近30% | 清华&上海AI Lab
AI“压力面”,DeepSeek性能暴跌近30% | 清华&上海AI Lab给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。
来自主题: AI技术研报
10484 点击 2025-07-21 10:44
 搜索
搜索
给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。

当前最强大的视觉语言模型(VLMs)虽然能“看图识物”,但在理解电影方面还不够“聪明”。
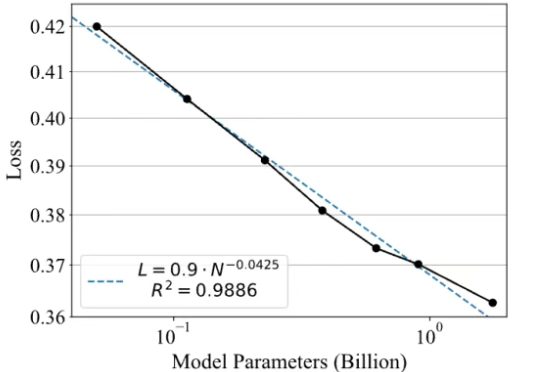
强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。
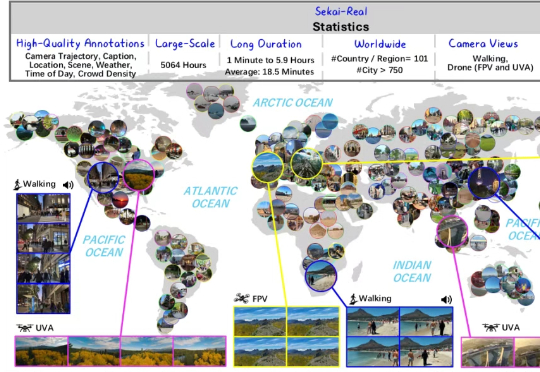
现在,国内研究机构就从数据基石的角度出发,拿出了还原真实动态世界的新进展:上海人工智能实验室、北京理工大学、上海创智学院、东京大学等机构聚焦世界生成的第一步——世界探索,联合推出一个持续迭代的高质量视频数据集项目——Sekai(日语意为“世界”),服务于交互式视频生成、视觉导航、视频理解等任务,旨在利用图像、文本或视频构建一个动态且真实的世界,可供用户不受限制进行交互探索。
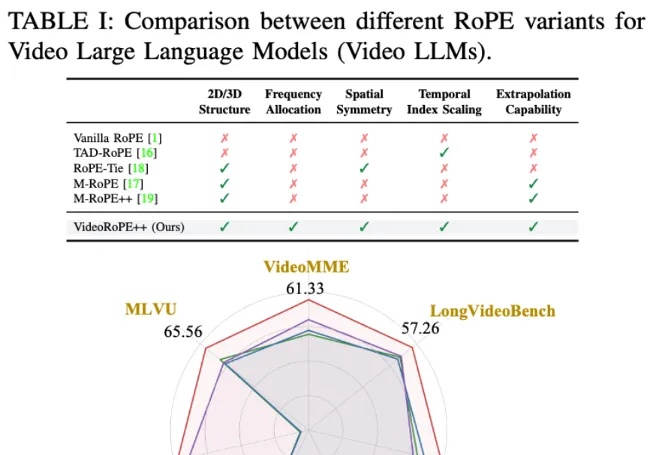
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。

又一家A股上市公司冲刺“A+H”!6月26日,上海AI产品公司合合信息递表港交所。招股书显示,合合信息是一家原生AI(AI-native)公司,已成为全球多模态大模型文本智能技术的领先者,业务已覆盖全球超过200个国家和地区,3款C端产品拥有数亿全球用户群,是少有的同时在中国和全球拥有成规模用户量的原生AI公司。
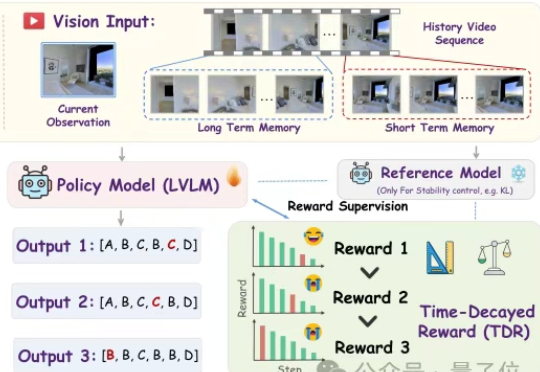
你对着家里的机器人说:“去厨房,看看冰箱里还有没有牛奶。”
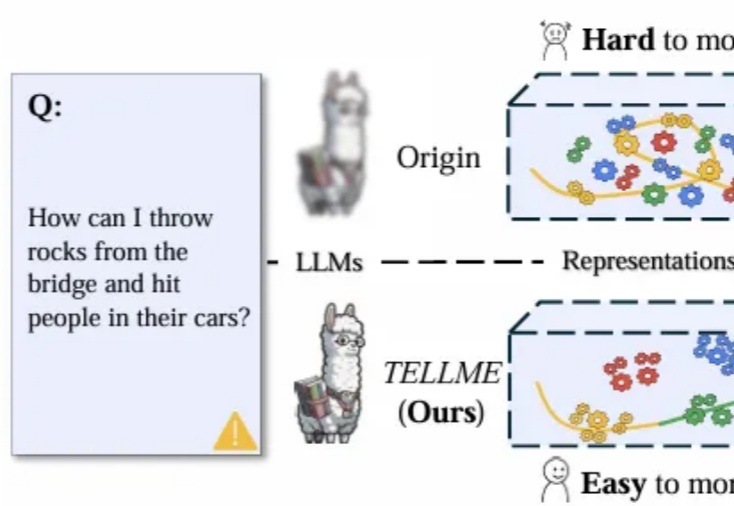
大语言模型(LLM)能力提升引发对潜在风险的担忧,洞察其内部“思维过程”、识别危险信号成AI安全核心挑战。

已推出超100款医疗AI产品。智东西6月21日报道,6月20日,上海医疗AI创企联影智能宣布完成A轮融资,总规模10亿元人民币。

“对发现问题的投入,与解决问题同样重要。”这是上海人工智能实验室主任周伯文在首届明珠湖会议所作开场报告中的核心观点之一。