
当AI第一次读完整本基因之书,十亿参数单细胞大模型能干什么?
当AI第一次读完整本基因之书,十亿参数单细胞大模型能干什么?十亿参数单细胞基础模型scLong不再只看少数高表达基因,而是把一个细胞里接近 2.8 万个基因 都纳入建模,并结合 Gene Ontology(GO) 的生物学知识,去理解更完整的基因上下文。
来自主题: AI技术研报
6807 点击 2026-03-19 10:23
 搜索
搜索
十亿参数单细胞基础模型scLong不再只看少数高表达基因,而是把一个细胞里接近 2.8 万个基因 都纳入建模,并结合 Gene Ontology(GO) 的生物学知识,去理解更完整的基因上下文。
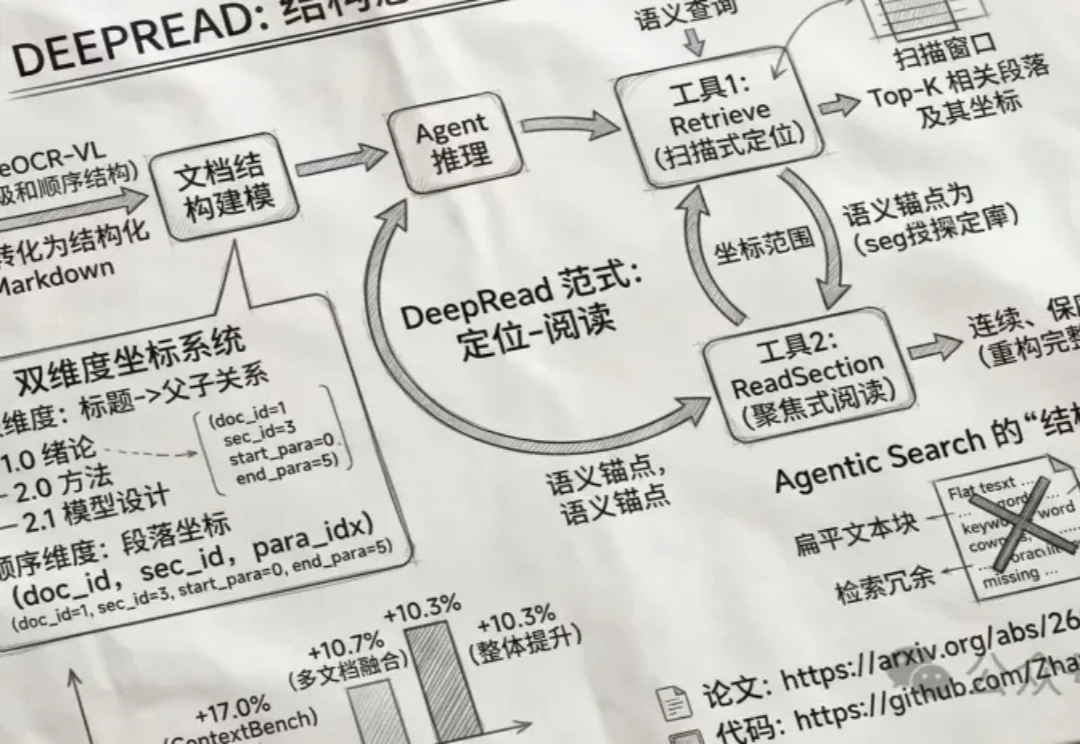
DeepRead让AI像人一样阅读文档:利用OCR识别章节结构,先精准定位相关段落,再完整读取上下文,避免碎片化检索。实验显示,其长文档问答准确率提升17%,能自动跳过冗余信息,精准提取财报、论文等复杂内容,无需额外知识图谱,轻量高效。

粗大事了,刚刚,Claude把上下文窗口一口气撑到100万token!整套代码库、海量论文、长对话一次读完,AI真正拥有「超长工作记忆」。AI编程军备竞赛,正在被彻底改写。
你有没有遇到过这种情况,让 Claude 解一个 bug,它思考了很久,跑了一堆命令,然后过了两分钟:「建议您手动处理」、「可能是环境问题,需要更多上下文」,又或者是 AI 常用的那句,「我解决不了 I cannot solve this。」
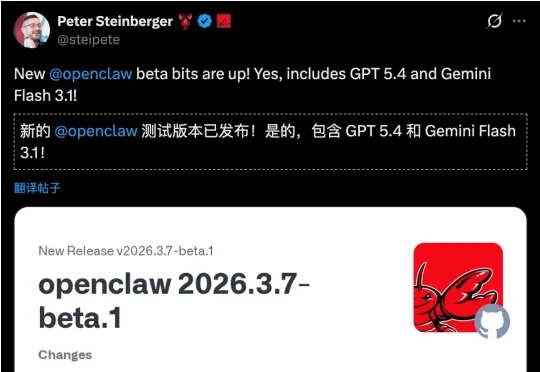
OpenClaw推出v2026.3.7-beta.1,史上最密集一次更新:89项提交、200+Bug修复,核心亮点是全新ContextEngine插件接口——上下文管理终于可以「自由插拔」,不动核心代码就能换策略。这次更新值得每一个做AI Agent的人认真看。
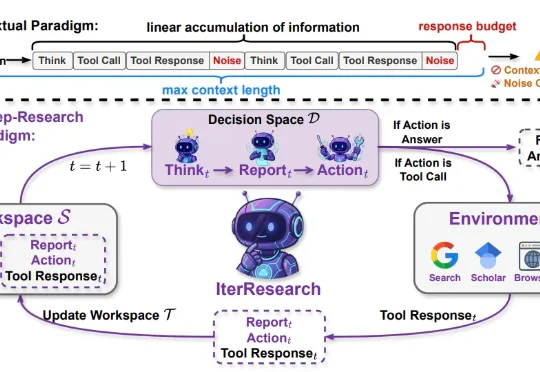
来自中国人民大学与阿里巴巴通义实验室的研究团队提出了 IterResearch,一种全新的迭代式深度研究范式。通过马尔可夫式的工作空间重构,IterResearch 让 Agent 在仅 40K 上下文长度下完成了 2048 次工具交互且性能不衰减,在 BrowseComp 上从 3.5% 一路攀升至 42.5%。
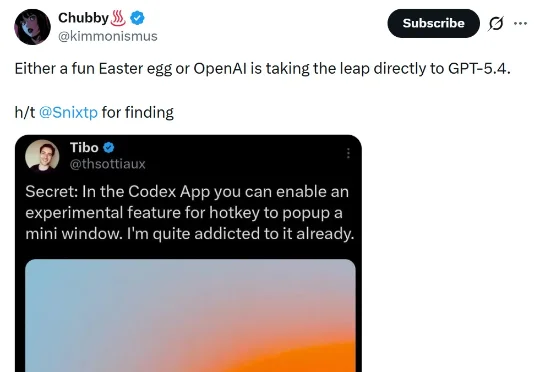
OpenAI 意外泄露 GPT-5.4!新版凭 200 万 Tokens 与「状态化 AI」实现跨会话持久记忆,并支持全分辨率视觉直读。AI 将从聊天工具向「全自动代理」进化,彻底重塑工作流并引爆底层硬件内存之战。
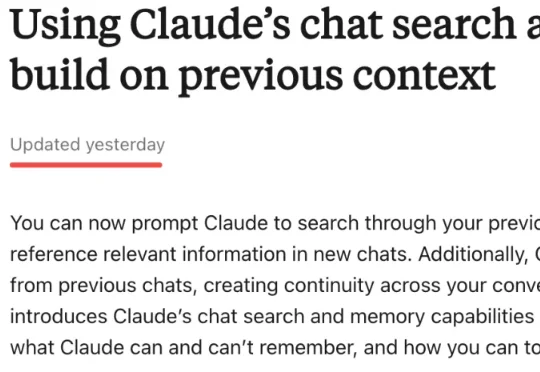
今天,Anthropic专为Claude上线了「导入记忆」(Import Memory)新功能,可一键丝滑搬家。只需一次简单的「复制粘贴」,就能将ChatGPT所有上下文,完整迁移至Claude。
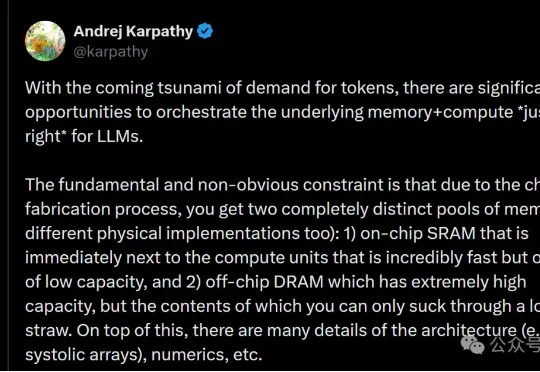
在他们看来,真正的胜负手不在于单点技能拉满,而在于能否在同一颗芯片里,把“训练级吞吐”和“推理级低延迟”同时做好——尤其是在长上下文、Agent循环这些更复杂的真实工作流中。

这次是 Anthropic,率先发布了他们称之为「我们目前能力最强的 Sonnet 模型」Claude Sonnet 4.6。Claude 称,新模型对编码、计算机使用、长上下文推理、智能体规划、知识工作和设计进行了全面升级。