
AI助手集体免费,微软OpenAI谷歌火力全开!Gemini 18万次代码补全白送
AI助手集体免费,微软OpenAI谷歌火力全开!Gemini 18万次代码补全白送谷歌Gemini 2.0代码助手免费,每月18万次代码补全,支持超大上下文窗口。微软Copilot语音与深度思考功能,同样免费!OpenAI也免费推出了GPT-4o mini高级语音模式。
来自主题: AI资讯
8946 点击 2025-02-27 16:42
 搜索
搜索
谷歌Gemini 2.0代码助手免费,每月18万次代码补全,支持超大上下文窗口。微软Copilot语音与深度思考功能,同样免费!OpenAI也免费推出了GPT-4o mini高级语音模式。
Zep,一个为大模型智能体提供长期记忆的插件,能将智能体的记忆组织成情节,从这些情节中提取实体及其关系,并将它们存储在知识图谱中,从而让用户以低代码的方式为智能力构建长期记忆。
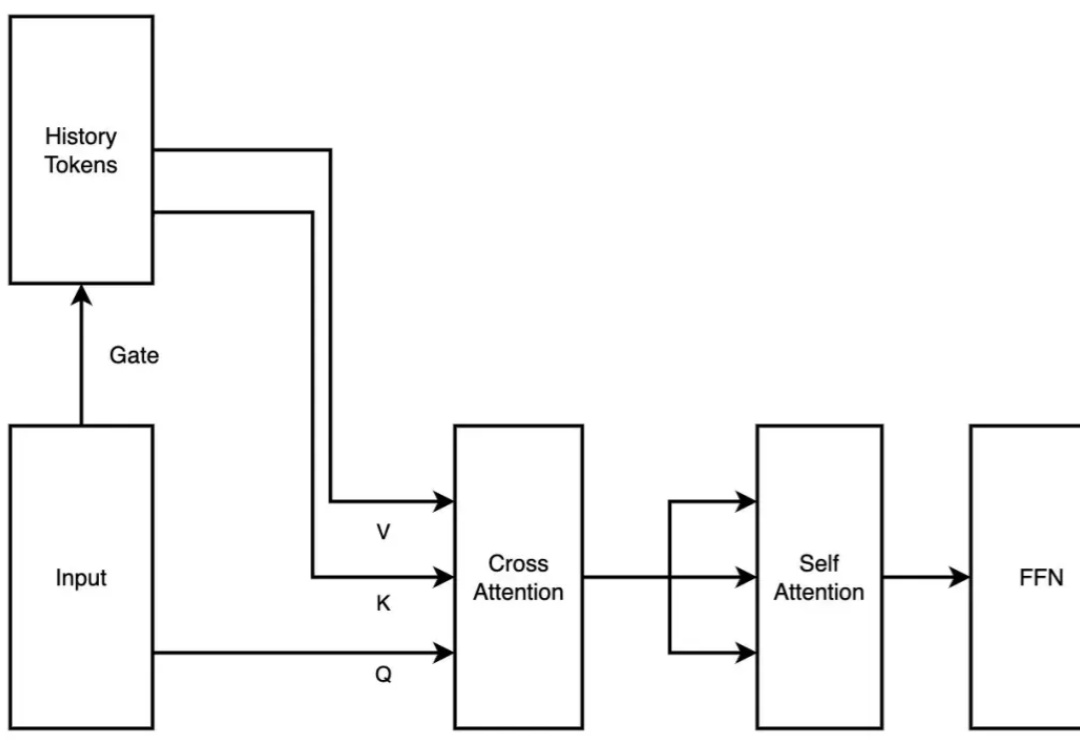
2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。
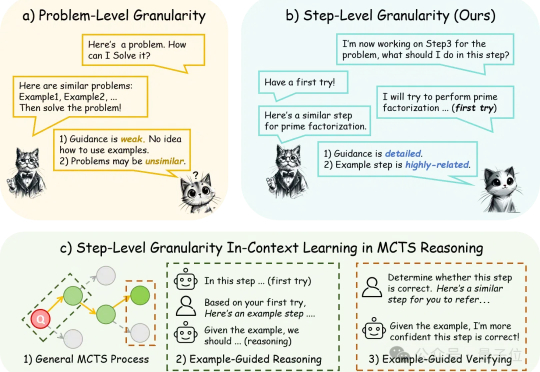
仅需简单提示,满血版DeepSeek-R1美国数学邀请赛AIME分数再提高。
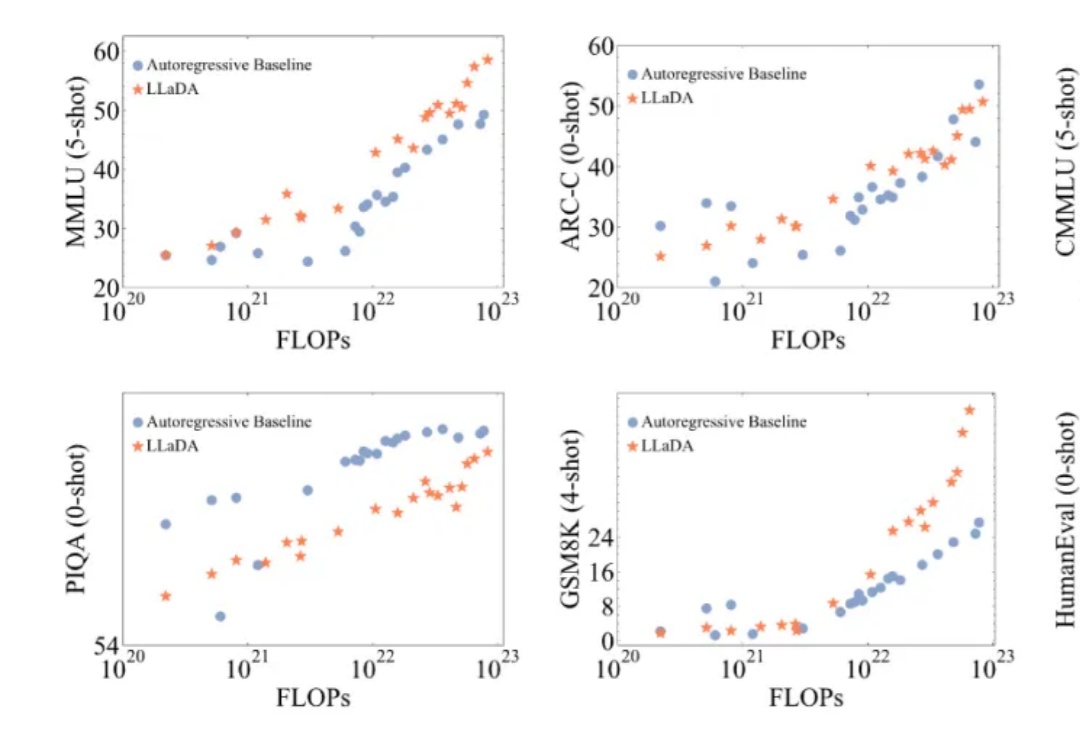
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。
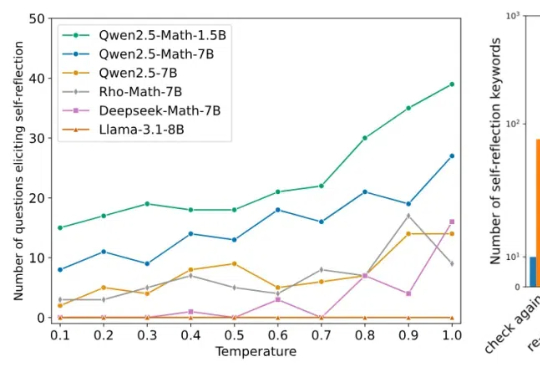
一项非常鼓舞人心的发现是:DeepSeek-R1-Zero 通过纯强化学习(RL)实现了「顿悟」。在那个瞬间,模型学会了自我反思等涌现技能,帮助它进行上下文搜索,从而解决复杂的推理问题。
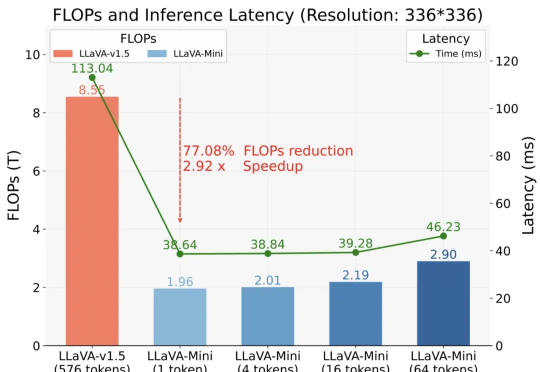
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。

谈到大模型的“国货之光”,除了DeepSeek之外,阿里云Qwen这边也有新动作——首次将开源Qwen模型的上下文扩展到1M长度。

研究人员首次探讨了大型语言模型(LLMs)在问题生成任务中的表现,与人类生成的问题进行了多维度对比,结果发现LLMs倾向于生成需要较长描述性答案的问题,且在问题生成中对上下文的关注更均衡。
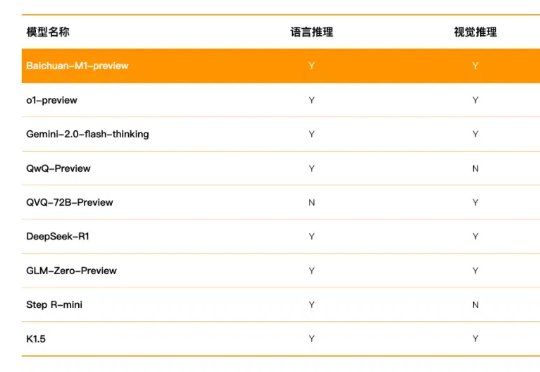
就在本周,Kimi 的新模型打开了强化学习 Scaling 新范式,DeepSeek R1 用开源的方式「接班了 OpenAI」,谷歌则把 Gemini 2.0 Flash Thinking 的上下文长度延伸到了 1M。1 月 24 日上午,百川智能重磅发布了国内首个全场景深度思考模型,把这一轮军备竞赛推向了高潮。