首个实例理解3D重建模型!NTU&阶越提出基于实例解耦的3D重建模型,助理场景理解
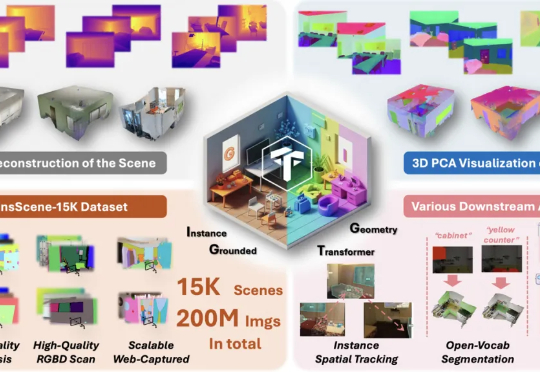
首个实例理解3D重建模型!NTU&阶越提出基于实例解耦的3D重建模型,助理场景理解现在,NTU联合StepFun提出了IGGT (Instance-Grounded Geometry Transformer) ,一个创新的端到端大型统一Transformer,首次将空间重建与实例级上下文理解融为一体。
来自主题: AI技术研报
6875 点击 2025-10-31 14:49
 搜索
搜索
现在,NTU联合StepFun提出了IGGT (Instance-Grounded Geometry Transformer) ,一个创新的端到端大型统一Transformer,首次将空间重建与实例级上下文理解融为一体。

生数科技前产品副总裁廖谦创业了。在此之前,他还先后担任过字节剪映与火山引擎前AIGC产品负责人。8月底从老东家离职后,公司成立仅半个月,就已经拿下了硅谷美元基金HT Investment与BV百度风投的数百万美元投资。

近两年,AI笔记成为AI应用落地的重点方向之一。随着大模型能力不断升级,AI笔记不再只是帮用户“写下东西”,而是试图理解、整理、提炼、甚至帮用户“思考”所记录下的内容。市场上AI笔记产品繁多,既有印象笔记、Notion AI这样加入AI能力的传统笔记产品,也有闪念贝壳、喵记多这样的AI原生笔记产品,甚至还有飞书文档这样将AI笔记功能嵌入办公套件的综合性产品。

全新AI工具EditVerse将图片和视频编辑整合到一个框架中,让你像P图一样轻松P视频。通过统一的通用视觉语言和上下文学习能力,EditVerse解决了传统视频编辑复杂、数据稀缺的问题,还能实现罕见的「涌现能力」。在效果上,它甚至超越了商业工具Runway,预示着一个创作新纪元的到来。
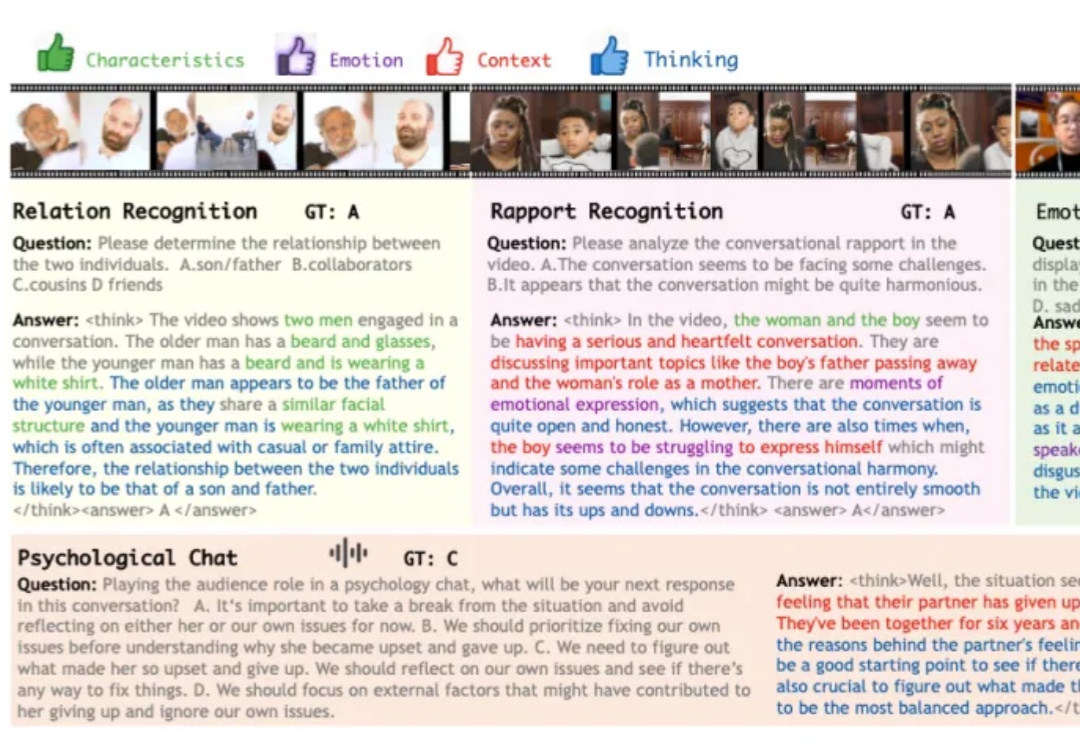
在科幻作品描绘的未来,人工智能不仅仅是完成任务的工具,更是为人类提供情感陪伴与生活支持的伙伴。在实现这一愿景的探索中,多模态大模型已展现出一定潜力,可以接受视觉、语音等多模态的信息输入,结合上下文做出反馈。

年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
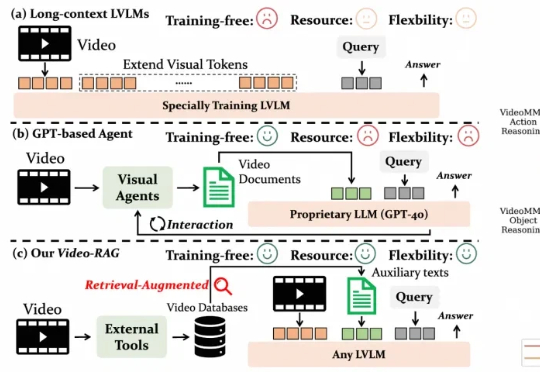
尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。
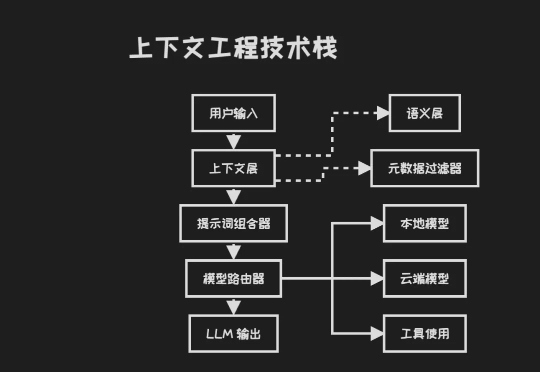
来自硅谷一线 AI 创业者的数据:95% 的 AI Agent 在生产环境都部署失败了。 「不是因为模型本身不够智能,而是因为围绕它们搭建的脚手架,上下文工程、安全性、记忆设计都还远没有到位。」 「大多数创始人以为自己在打造 AI 产品,但实际上他们构建的是上下文选择系统。」
在技术飞速更新迭代的今天,每隔一段时间就会出现「XX 已死」的论调。「搜索已死」、「Prompt 已死」的余音未散,如今矛头又直指 RAG。

每隔一阵子,总有人宣告“RAG已死”:上下文越来越长、端到端多模态模型越来越强,好像不再需要检索与证据拼装。但真正落地到复杂文档与可溯源场景,你会发现死掉的只是“只切文本的旧RAG”。