
持续怒斩53K星!狠人揭秘Clawdbot反行业记忆系统!跟ChatGPT大不同:不靠狂塞上下文,而是一个个md文件!网友:AI记忆第一次被工程化了
持续怒斩53K星!狠人揭秘Clawdbot反行业记忆系统!跟ChatGPT大不同:不靠狂塞上下文,而是一个个md文件!网友:AI记忆第一次被工程化了过去一年,几乎所有 AI 产品都在谈一个词:记忆。
来自主题: AI技术研报
7584 点击 2026-01-27 16:52
 搜索
搜索
过去一年,几乎所有 AI 产品都在谈一个词:记忆。
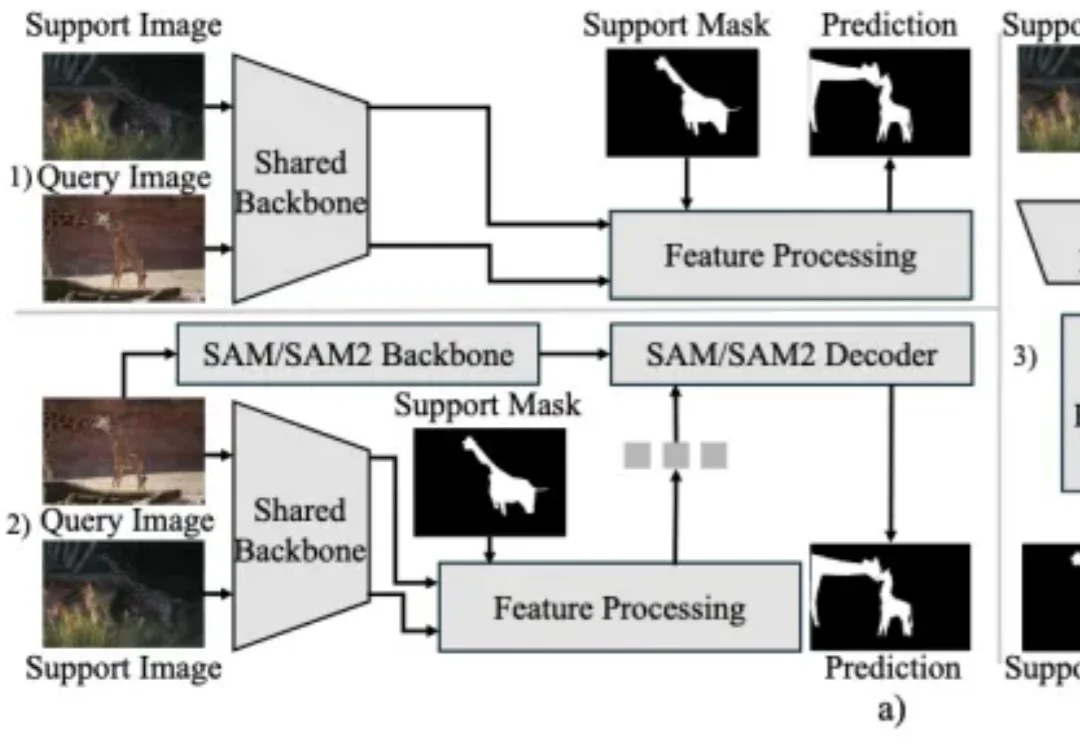
上下文分割(In-Context Segmentation)旨在通过参考示例指导模型实现对特定目标的自动化分割。尽管 SAM 凭借卓越的零样本泛化能力为此提供了强大的基础,但将其应用于此仍受限于提示(如点或框)构建,这样的需求不仅制约了批量推理的自动化效率,更使得模型在处理复杂的连续视频时,难以维持时空一致性。
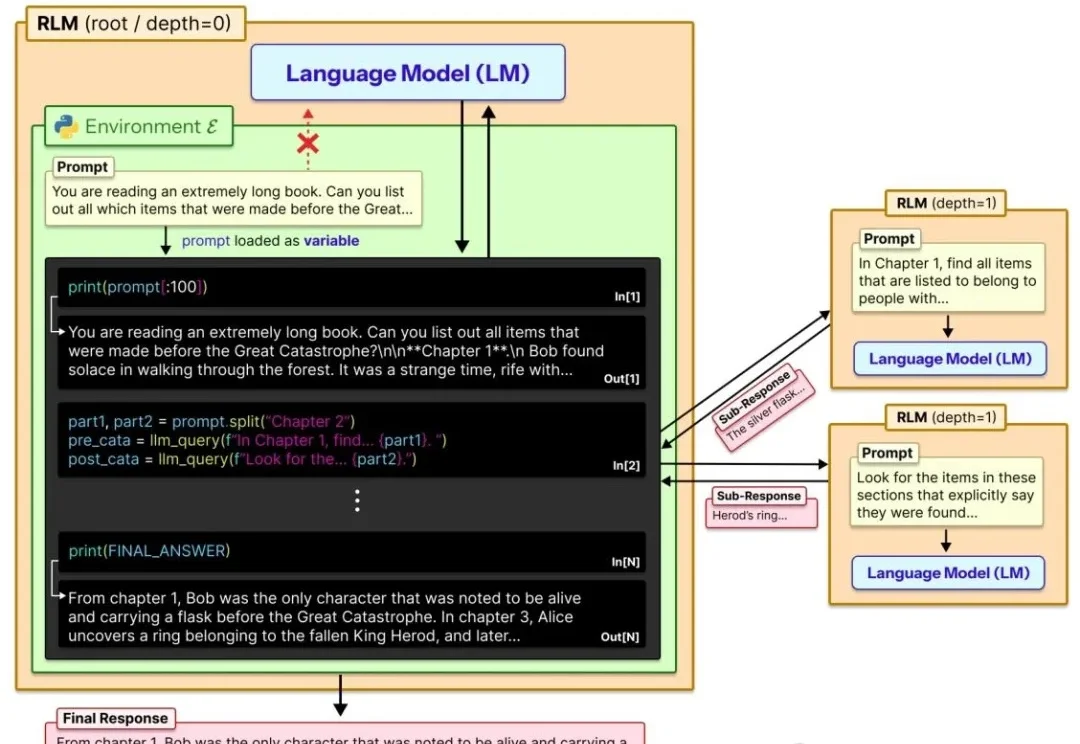
让大模型轻松处理比自身上下文窗口长两个数量级的超长文本!

AI 时代飞书更大的价值,与打开更丰富「上下文」的输入端口紧密相关。
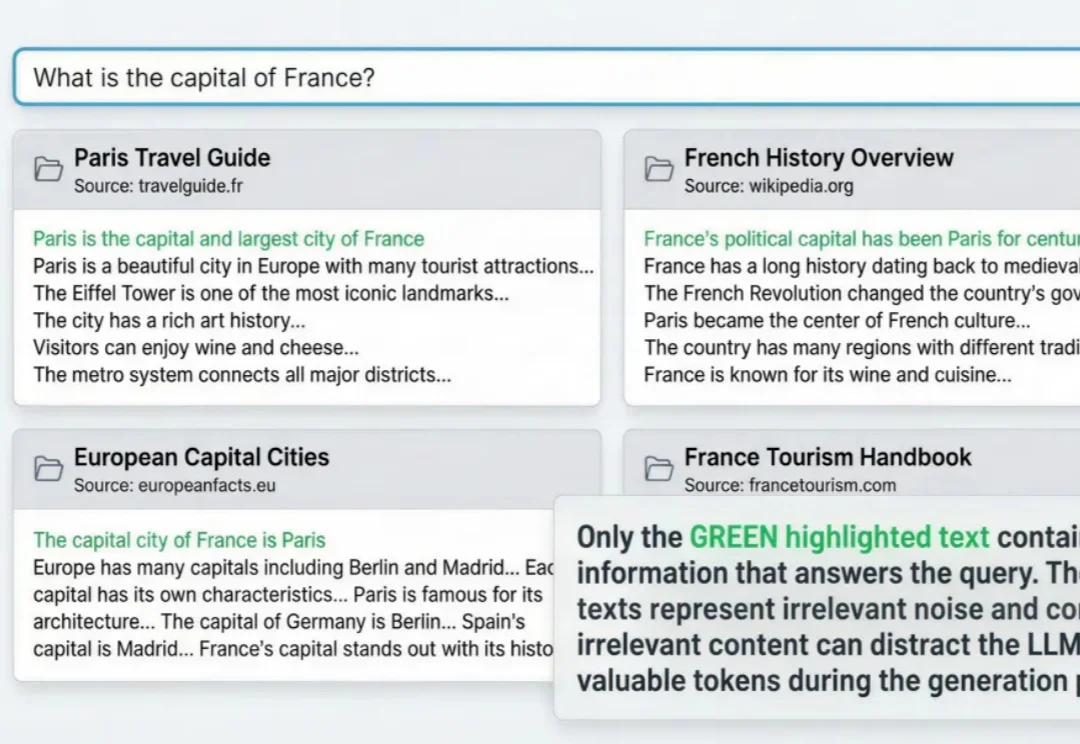
RAG与agent用到深水区,一定会遇到这个问题: 明明架构很完美,私有数据也做了接入,但项目上线三天,不但token账单爆了,模型输出结果也似乎总差点意思。
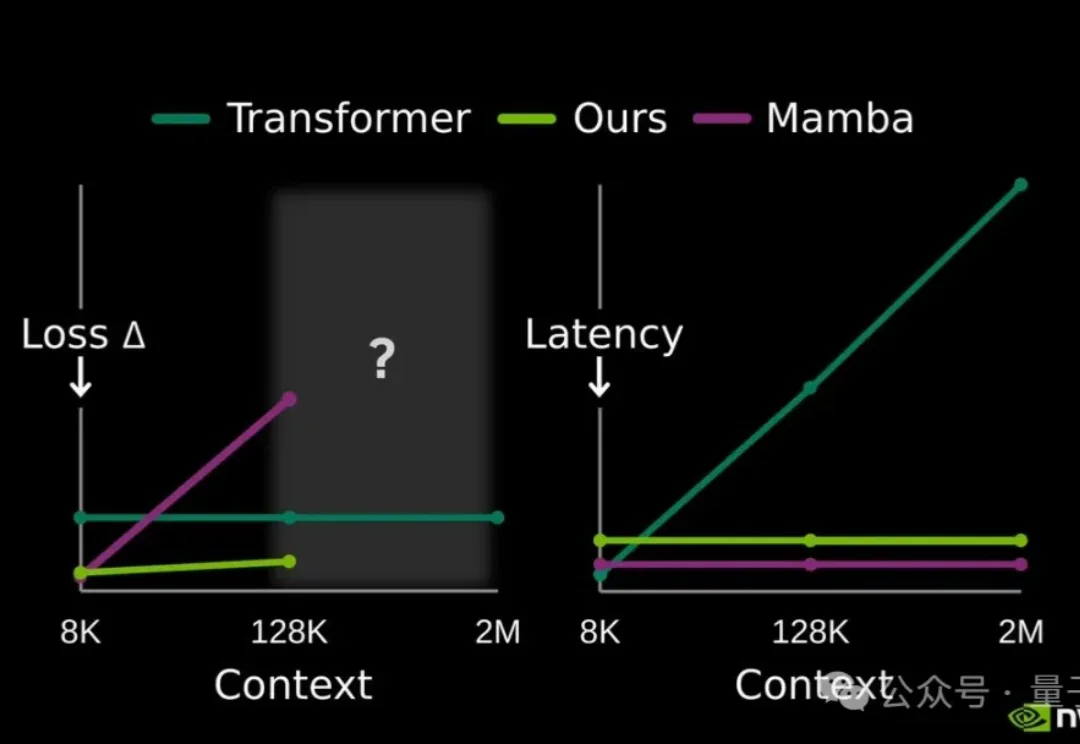
提高大模型记忆这块儿,美国大模型开源王者——英伟达也出招了。
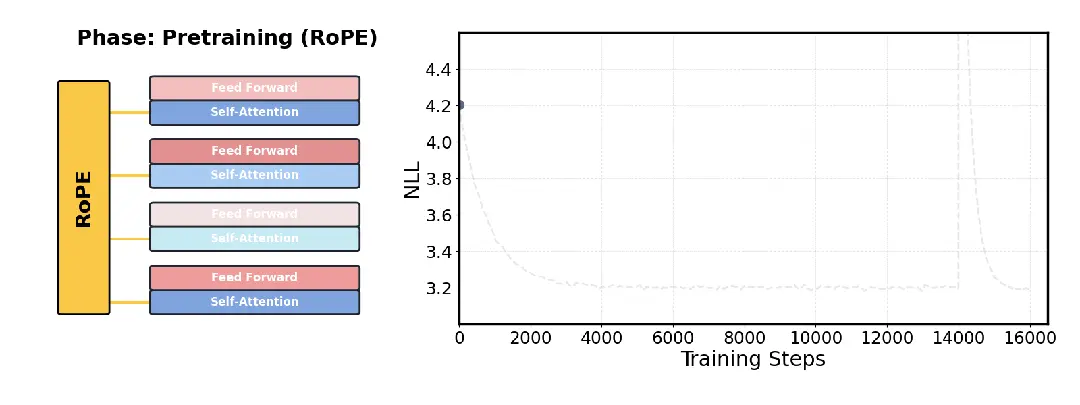
针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。

家人们, 大概是从去年下半年上下文工程这个概念火了之后,我开始有意识的进行一些碎片化的记录。

256K文本预加载提速超50%,还解锁了1M上下文窗口。

最近,Cursor 也发表了一篇文章《Dynamic context discovery》,分享了他们是怎么做上下文管理的。结合 Manus、Cursor 这两家 Agent 领域头部团队的思路,我们整理了如何做好上下文工程的一些关键要点。