不走Transformer寻常路,「元始智能RWKV」获数千万天使轮融资
不走Transformer寻常路,「元始智能RWKV」获数千万天使轮融资要做大模型领域的安卓和Linux。
来自主题: AI资讯
5837 点击 2025-01-03 16:10
 搜索
搜索
要做大模型领域的安卓和Linux。
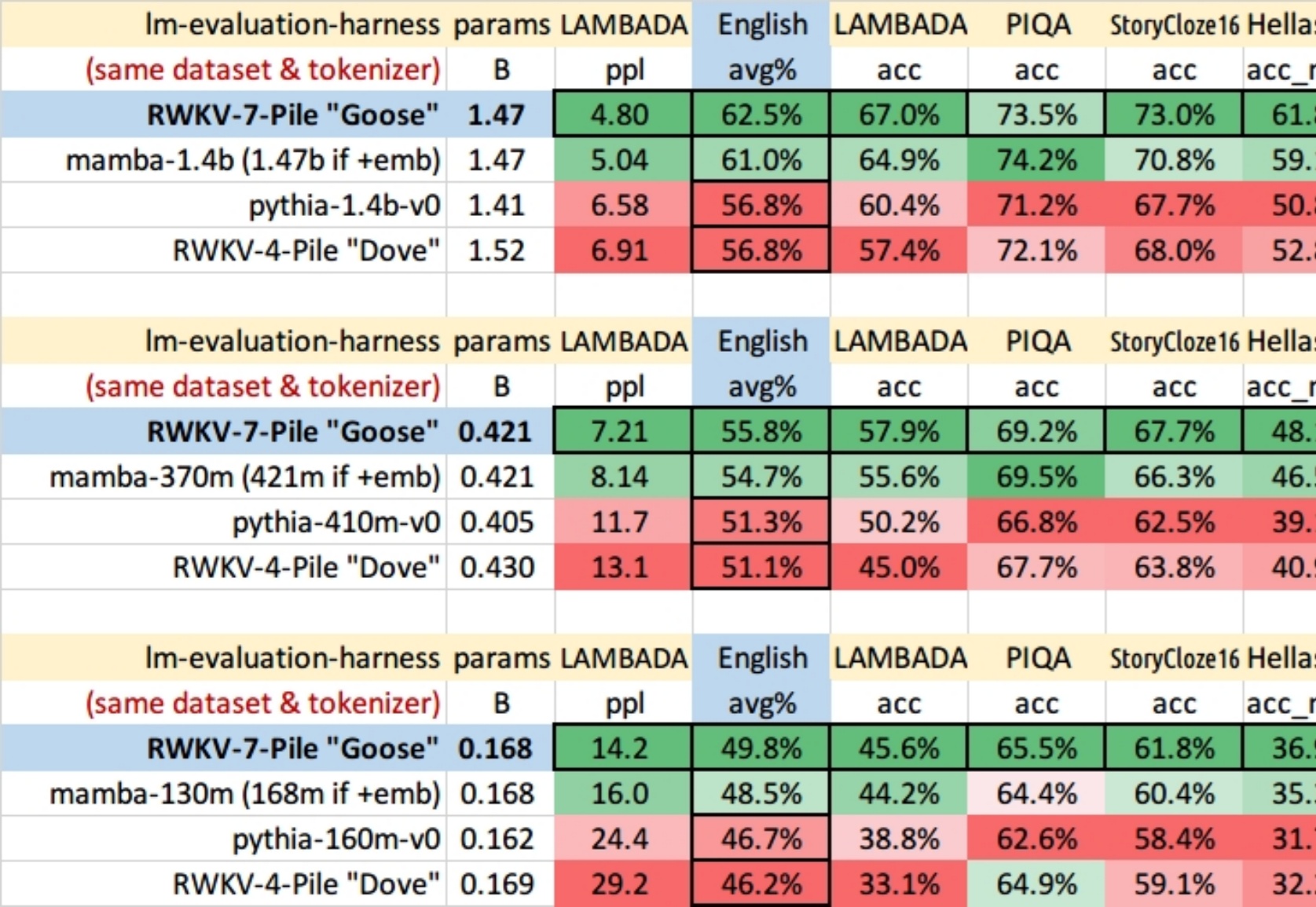
时间序列数据,作为连续时间点的数据集合,广泛存在于医疗、金融、气象、交通、能源(电力、光伏等)等多个领域。有效的时间序列预测模型能够帮助我们理解数据的动态变化,预测未来趋势,从而做出更加精准的决策。

2022年,我们打赌说transformer会统治世界。 我们花了两年时间打造Etched chip,这是世界上第一个用于transformer(ChatGPT中的“T”)的专用芯片。
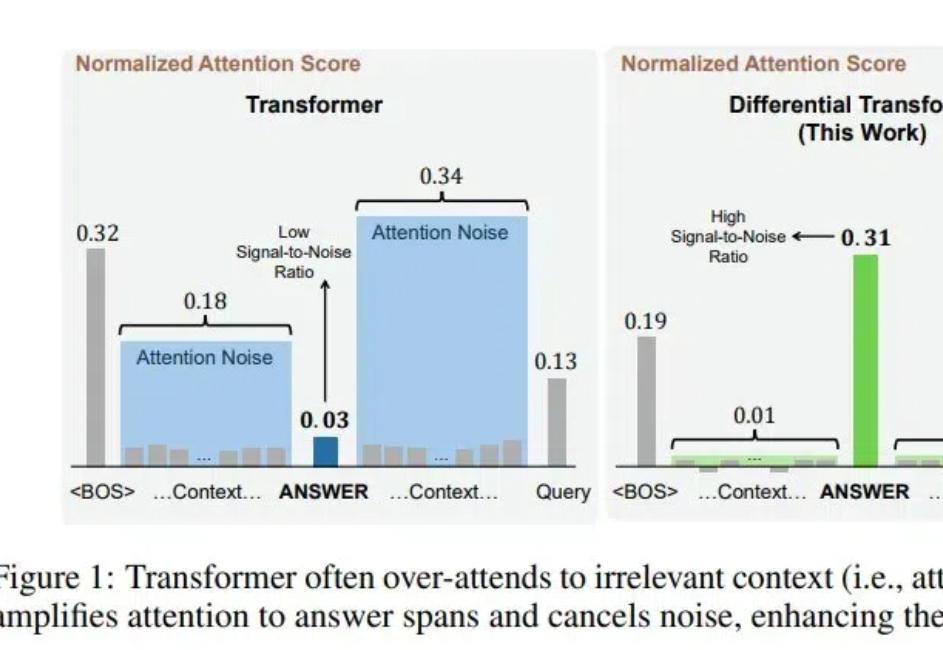
ViT核心作者Lucas Beyer,长文分析了一篇改进Transformer架构的论文,引起推荐围观。

Transformer——支撑像 OpenAI 的 ChatGPT 和 Anthropic 的 Claude 这样的聊天机器人的基础 AI 技术——正在帮助机器人更快地学习。
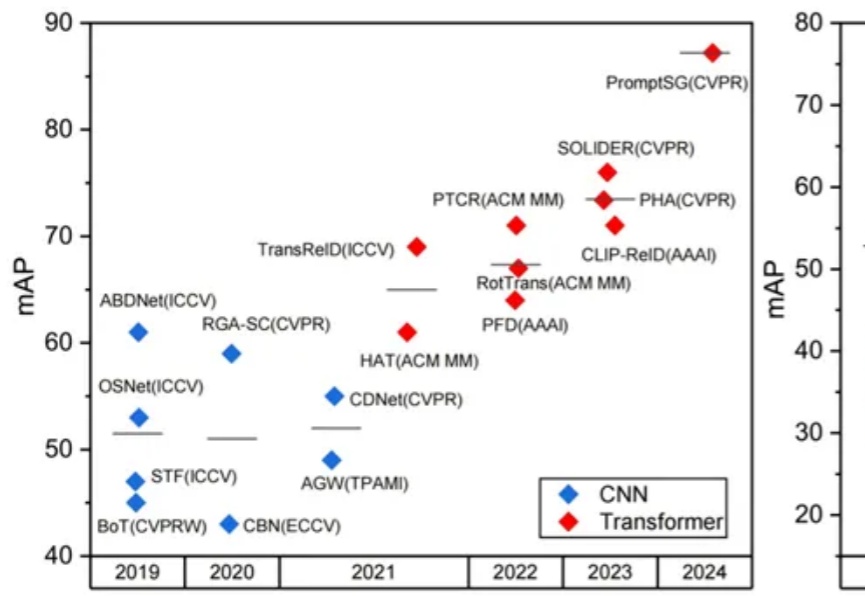
研究人员对基于Transformer的Re-ID研究进行了全面回顾和深入分析,将现有工作分类为图像/视频Re-ID、数据/标注受限的Re-ID、跨模态Re-ID以及特殊Re-ID场景,提出了Transformer基线UntransReID,设计动物Re-ID的标准化基准测试,为未来Re-ID研究提供新手册。
天啦撸!!AI想出来的idea,还真有人写成论文了。甚至预印本arXiv、博客、代码全都有了。今年8月,Sakana AI(由Transformer论文8位作者的最后一位Llion Jones创业成立)这家公司推出了史上首位“AI科学家”,且一登场就一口气生成了十篇完整学术论文。

AI如何颠覆生物科技? AI正在入侵科学界,特别是生物科技方向。 瑞典皇家科学院在2024年10月宣布了当年诺贝尔化学奖的获奖者,出乎意料的是—— AI又是大赢家。

Mamba 这种状态空间模型(SSM)被认为是 Transformer 架构的有力挑战者。近段时间,相关研究成果接连不断。而就在不久前,Mamba 作者 Albert Gu 与 Karan Goel、Chris Ré、Arjun Desai、Brandon Yang 一起共同创立的 Cartesia 获得 2700 万美元种子轮融资。
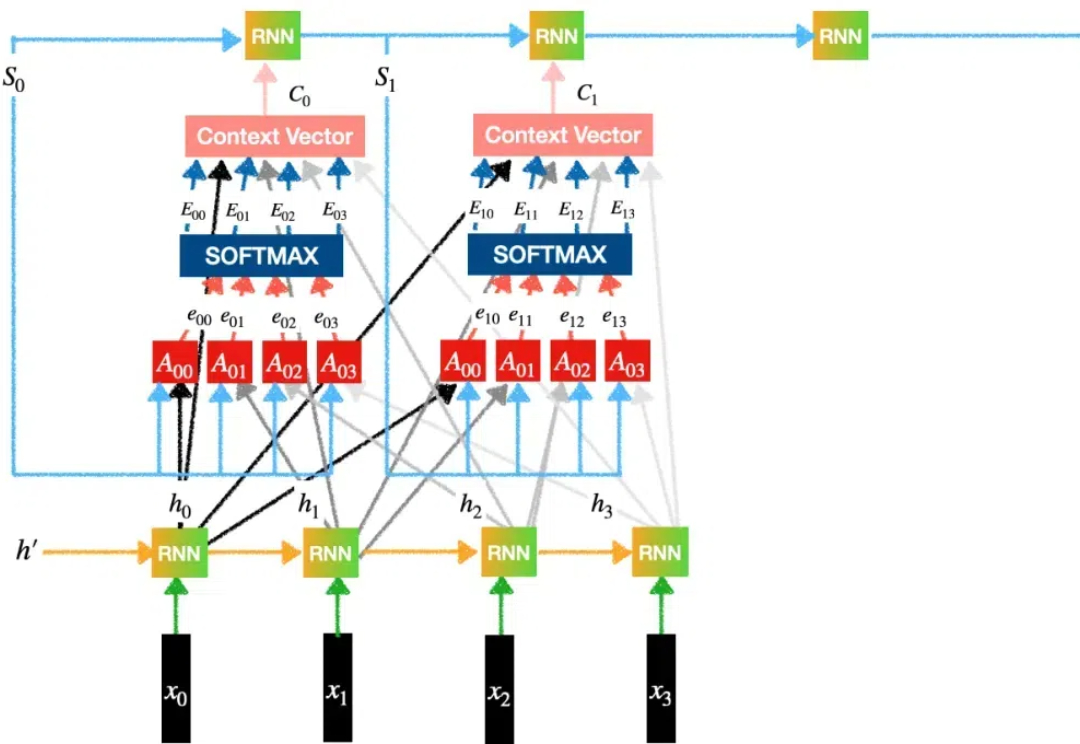
Transformer模型自2017年问世以来,已成为AI领域的核心技术,尤其在自然语言处理中占据主导地位。然而,关于其核心机制“注意力”的起源,学界存在争议,一些学者如Jürgen Schmidhuber主张自己更早提出了相关概念。