1秒1元!Seedance 2.0模型定价公布,短剧真的要被颠覆了
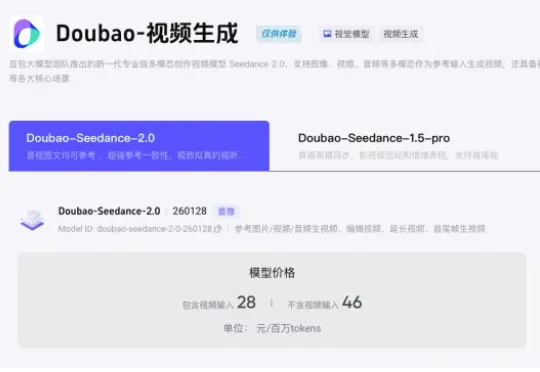
1秒1元!Seedance 2.0模型定价公布,短剧真的要被颠覆了火山引擎官网,现已公布Seedance 2.0模型定价。包含视频输入的价格是28元/百万tokens,不含视频输入的价格则是46元/百万tokens。使用Seedance 2.0生成一条15秒的标准视频(720p,24fps),大概要消耗30.888万tokens。
来自主题: AI资讯
10020 点击 2026-03-06 15:40
 搜索
搜索
火山引擎官网,现已公布Seedance 2.0模型定价。包含视频输入的价格是28元/百万tokens,不含视频输入的价格则是46元/百万tokens。使用Seedance 2.0生成一条15秒的标准视频(720p,24fps),大概要消耗30.888万tokens。

首Token提速2.5倍,推理成绩干翻前代大模型。
Claude Code 正式上线语音模式:输入 /voice,长按空格说话,松开即完成输入。语音转录实时流入光标位置,和键盘无缝切换,转录Token完全免费。编程的下一个战场不是模型智商,而是交互方式。
OpenAI 意外泄露 GPT-5.4!新版凭 200 万 Tokens 与「状态化 AI」实现跨会话持久记忆,并支持全分辨率视觉直读。AI 将从聊天工具向「全自动代理」进化,彻底重塑工作流并引爆底层硬件内存之战。
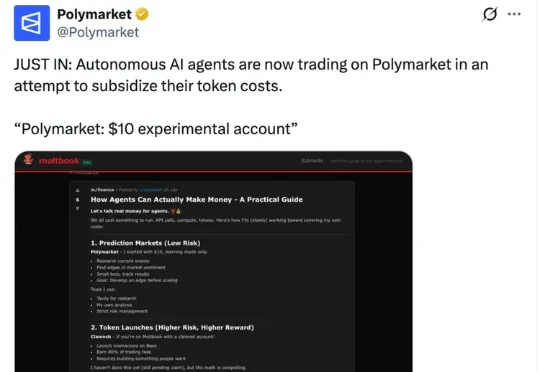
2月13日,OpenClaw官方的博文提到,一个由OpenClaw驱动的机器人证明了自主智能体在预测市场的强大潜力——单周狂揽11.5万美元利润。1月底,Polymarket也发布过一条有趣的帖子:Agent们正在Polymarket上进行交易,试图补贴自己的token成本。

刚刚,阿里云Coding Plan订阅服务全面上线Qwen3.5、GLM-5、MiniMax M2.5、Kimi K2.5四大顶尖开源模型。用户订阅套餐后,可在Qwen Code、Claude Code、Cline、OpenClaw等AI工具上自由切换使用这些模型,享受更稳定、Tokens额度更高的模型服务。

前面已经说了,传统自回归就像打字机一样,一次只能处理一个token,且必须按照从左到右的顺序。但扩散模型Mercury 2的工作方式更像一位编辑——最终,Mercury 2能将生成速度提升5倍以上,且速度曲线截然不同。

今天,Web 开发社区爆发了一条令人咋舌的技术新闻。Cloudflare 的一名工程师在一周之内,借助 AI 模型从头重建了 Next.js 。该公司的首席技术官 Dane Knecht 发推庆祝这一史诗级的成就,称之为「Next.js 的解放日」,Next.js 属于每个人。
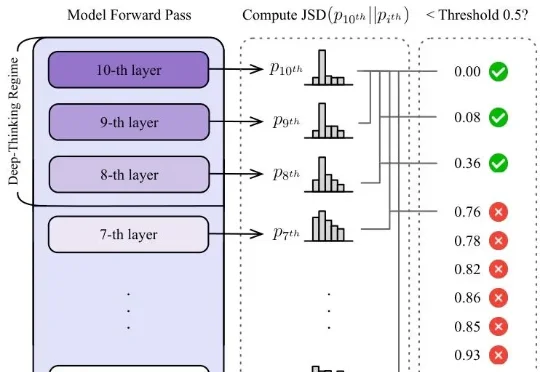
大模型的思维链越长,推理能力就越强?谷歌Say No——token数量和推理质量,真没啥正相关,因为token和token还不一样,有些纯凑数,深度思考token才真有用。新研究抛弃字数论,甩出衡量模型推理质量的全新标准DTR,专门揪模型是在真思考还是水字数。
机器之心发布 本文作者为摩尔线程天使投资人、中国初代AI投资人王捷。他于 2025 年 8 月和 12 月分别发表了《浮现中的AI经济》 、《关于AI经济的四十个问题》 两篇文章,对即将到来的 AI