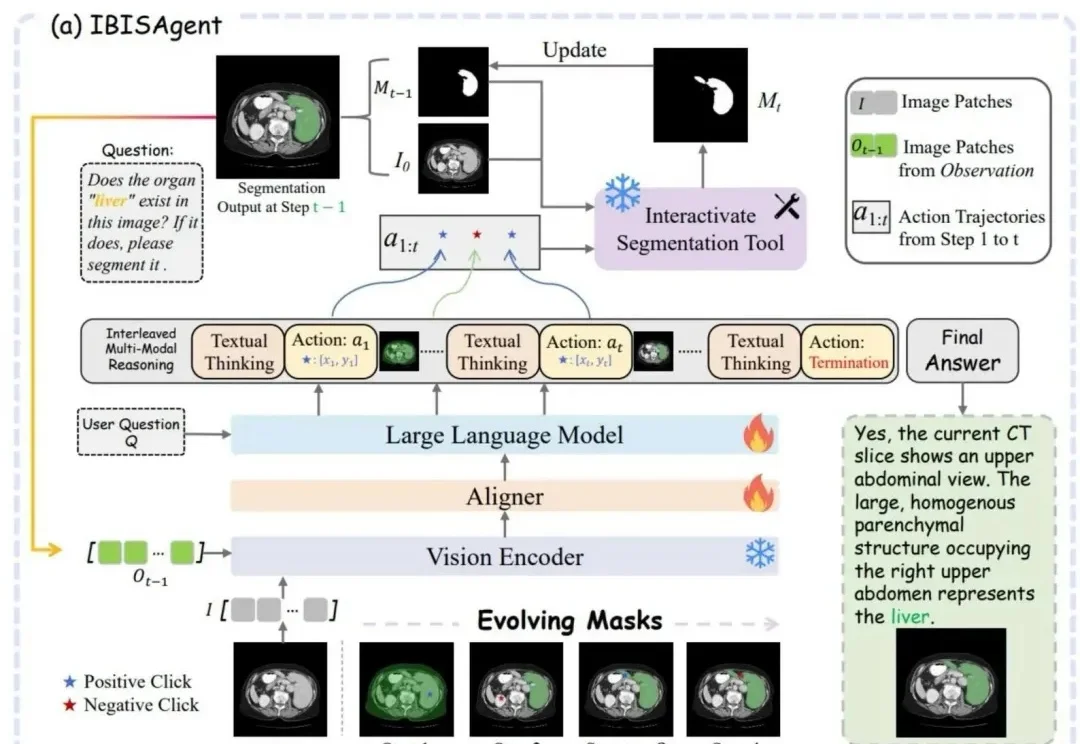
国产多模态Agent拿下医学分割SOTA!不用改模型、不加token | 浙大&上海AI Lab
国产多模态Agent拿下医学分割SOTA!不用改模型、不加token | 浙大&上海AI Lab这个生物医学视觉推理框架,被CVPR 2026接收了!
来自主题: AI技术研报
6734 点击 2026-04-22 09:11
 搜索
搜索
这个生物医学视觉推理框架,被CVPR 2026接收了!

如果你在网络安全圈混,最近一定被“Mythos”刷过屏——Anthropic 搞出了一个能挖 Bug 的 AI 模型,但因为怕被坏人滥用,愣是没敢公开发布。

当前大模型的发展呈现出类似于“军备竞赛”的趋势——模型规模持续攀升,对计算硬件的需求也随之快速增长。
英伟达良心福利!免费领一年顶级大模型订阅,MiniMax / Kimi / DeepSeek 全都能用!NVIDIA 官方平台build.nvidia.com开放了一批"Free Endpoint"模型,注册账号、验证手机号后就能生成一把最长有效期12 个月的 API Key,免费调用几十个当下最火的大模型——不计 Token、无余额限制、无需信用卡。

黄仁勋曾经说过,AI 时代 token 就是货币,那么谁会是 token 最大的消费者?
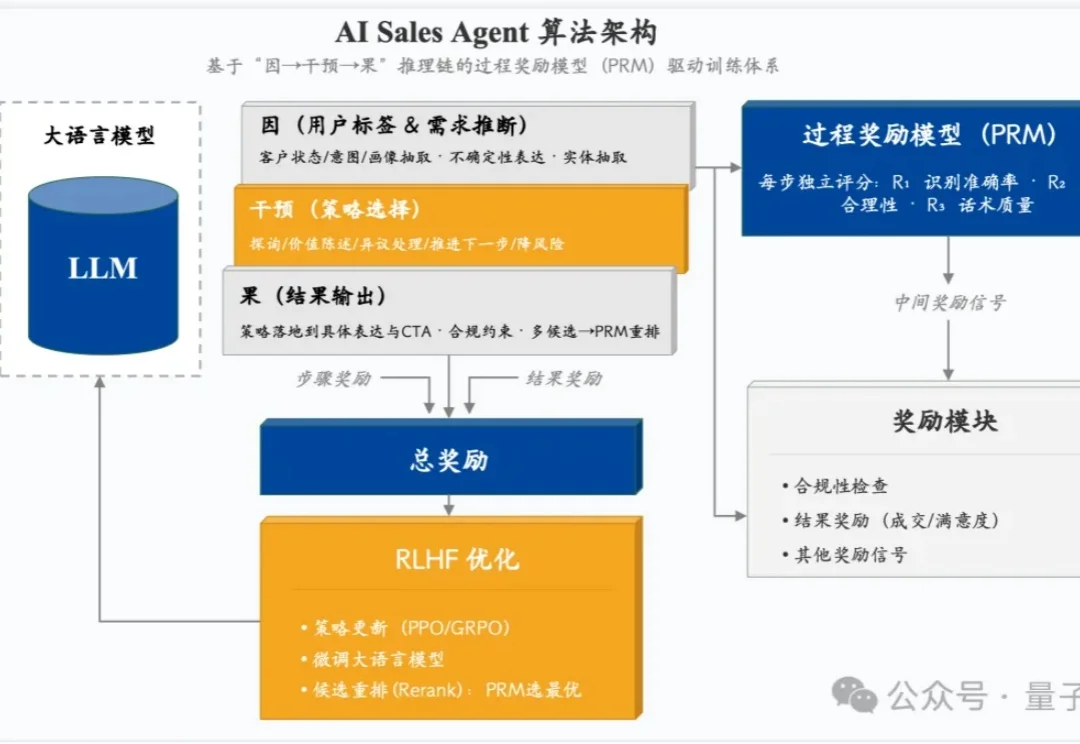
当全行业还在卷大模型参数、烧算力、拼Token消耗时,已经有企业实打实地在用大模型帮客户赚到真金白银。

AI已经是一个彻底围绕Token的生意了, 或者说,Token经济学就是推理经济学, 我认为,今时今日的AI, 连这种基础设施层的东西(比如网络), 都和业务理念融为一体了, 这真是一个大趋势。

最近,Claude Code 团队工程师 Thariq Shihipar又在X上发文了,上个月他写的Skill深度经验分享贴在社交平台爆火,这周他又发了一篇Claude的100万toke上下文窗口使用技巧的文章,平台阅读量已超过200万。

给了100万token,现在却手把手教你怎么删记录!Anthropic官方承认:塞太多东西,Claude就会变蠢。面对失控的「上下文腐烂」,Anthropic连夜甩出5招救命指南。

跑分最高未必能赢,但最懂Harness的可以。如今,被Hermes、OpenClaw等全球爆火开源Agent项目「钦定」为默认的MiniMax,在OpenRouter上的日均Token消耗已飙到3000亿。