
大模型能“原地”改参数了!字节Seed&北大新论文:测试时推理无需加层重训练
大模型能“原地”改参数了!字节Seed&北大新论文:测试时推理无需加层重训练字节Seed最新研究,让大模型能“原地改参数”了。既不用改模型结构,也不用重新训练,还跑得很快。具体是这么个情况。智能体时代嘛,大家都知道模型们面对的任务开始变得越来越复杂、上下文越来越长。
来自主题: AI技术研报
8735 点击 2026-04-11 10:25
 搜索
搜索
字节Seed最新研究,让大模型能“原地改参数”了。既不用改模型结构,也不用重新训练,还跑得很快。具体是这么个情况。智能体时代嘛,大家都知道模型们面对的任务开始变得越来越复杂、上下文越来越长。

HappyHorse身份曝光,或将明天上线?
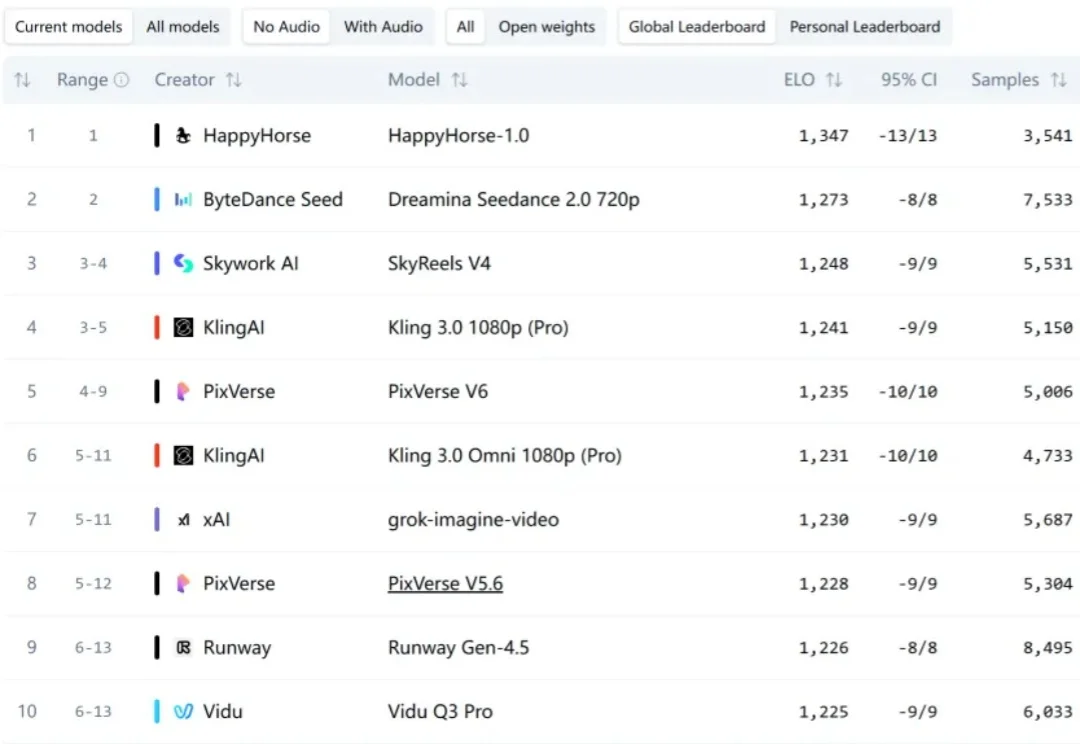
就在 OpenAI 都停了 Sora,所有人以为 Seedance 2.0 要一统天下的时候,没想到不知哪里冒出来一匹马。

AI交互的「机械感」消失了!今天,豆包甩出原生全双工语音大模型Seeduplex,不仅能边听边说,甚至能听懂你在思考时的「卡壳」,就算环境再吵也不怕,抗干扰能力直接拉满。

被动成为新一代 AI 黄埔军校的字节跳动。

最近Seedance 2.0接入大赛开始了,有头有脸的视频agent都当上字节中介原地起飞了。
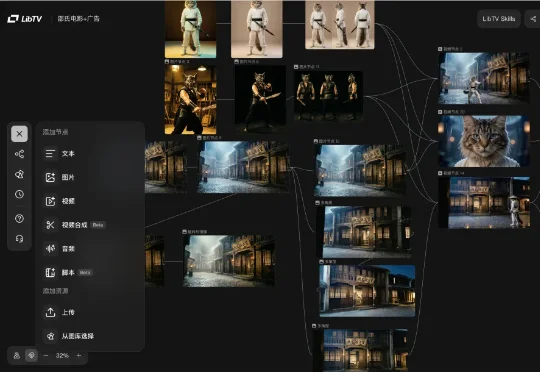
不过,最近有个好用的破局工具。LibTV终于接入了万众瞩目的Seedance 2.0!最关键的是,在LibTV里跑Seedance 2.0,速度非常快,几分钟就能出一条高质量的视频,彻底治好了我的排队焦虑。

每天 120 万亿 Tokens,这就是今天上午火山引擎 AI 创新巡展上,豆包大模型亮出的最新成绩单。

相似度超越Seed-TTS、MiniMax-Speech等知名模型。昨晚,美团LongCat团队发布了文本转语音模型LongCat-AudioDiT,并开源1B、3.5B参数量的版本。这一模型的最大特点,是彻底抛弃了梅尔谱等中间表示,直接在波形潜空间进行基于扩散模型的文本转语音。通俗地说,这一模型直接根据声音本身的规律进行生成,“雕刻”出最原始的声音波形,从根源阻断数据转换的级联误差。

第一篇论文来自字节SEED团队, 打了一些基础; 《Over-Tokenized Transformer》。 论文标题看上去在讨论“过度分词”。 而重点必然是在第二篇上—— DeepSeek公司的学术成果Engram。 《Conditional Memory via Scalable Lookup》 也就是Engram模块所出处的论文。