Meta用40万个GPU小时做了一个实验,只为弄清强化学习Scaling Law
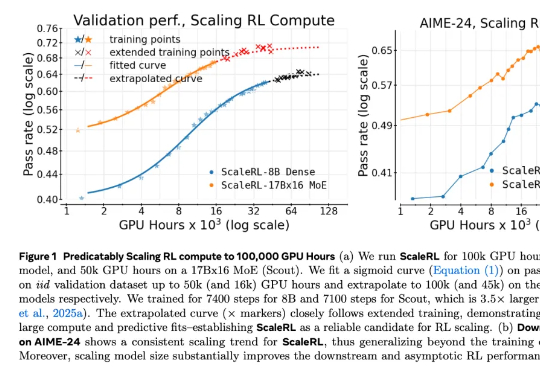
Meta用40万个GPU小时做了一个实验,只为弄清强化学习Scaling Law在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?
来自主题: AI技术研报
9956 点击 2025-10-19 17:54
 搜索
搜索
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?
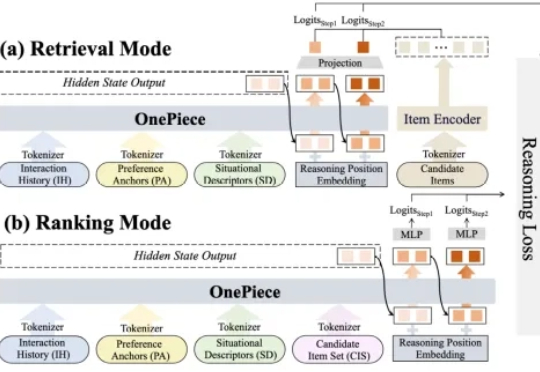
2025 年,生成式推荐(Generative Recommender,GR)的发展如火如荼,其背后主要的驱动力源自大语言模型(LLM)那诱人的 scaling law 和通用建模能力(general-purpose modeling),将这种能力迁移至搜推广工业级系统大概是这两年每一个从业者孜孜不倦的追求。
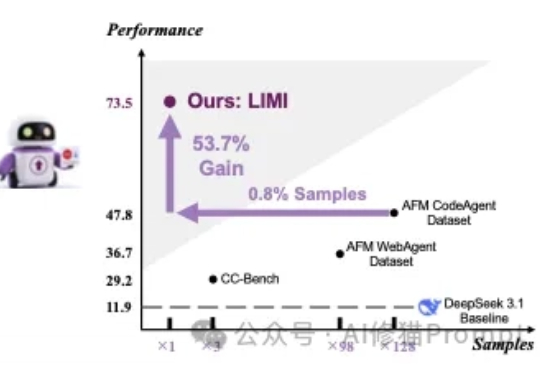
对于提升AI能主动发现问题、提出假设、调用工具并执行解决方案,在真实环境里闭环工作,而不只是在对话里“想”的智能体能力(Agency)。在这篇论文之前的传统方法认为,需要遵循传统语言模型的“规模法则”(Scaling Laws)才能实现,即投入更多的数据就能获得更好的性能。

Epoch AI 最近受 Google DeepMind 委托编写了一份分析报告,探讨这种规模扩张(Scaling)在计算、投资、数据、硬件和能源方面将带来哪些影响。在报告中,进一步探讨了这种规模扩张将赋予的未来 AI 能力,尤其是在科研领域,而这正是领先 AI 开发者关注的重点。

近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。

很多人认为,Scaling Law 正在面临收益递减,因此继续扩大计算规模训练模型的做法正在被质疑。最近的观察给出了不一样的结论。研究发现,哪怕模型在「单步任务」上的准确率提升越来越慢,这些小小的进步叠加起来,也能让模型完成的任务长度实现「指数级增长」,而这一点可能在现实中更有经济价值。

爱诗科技CEO王长虎告诉我们,过去两年,公司做对了两件事:不盲目烧钱扩张,不盲目对模型做Scaling。

这几天,一篇关于向量嵌入(Vector Embeddings)局限性的论文在 AlphaXiv 上爆火,热度飙升到了近 9000。

AI 也要「考古」式科研?
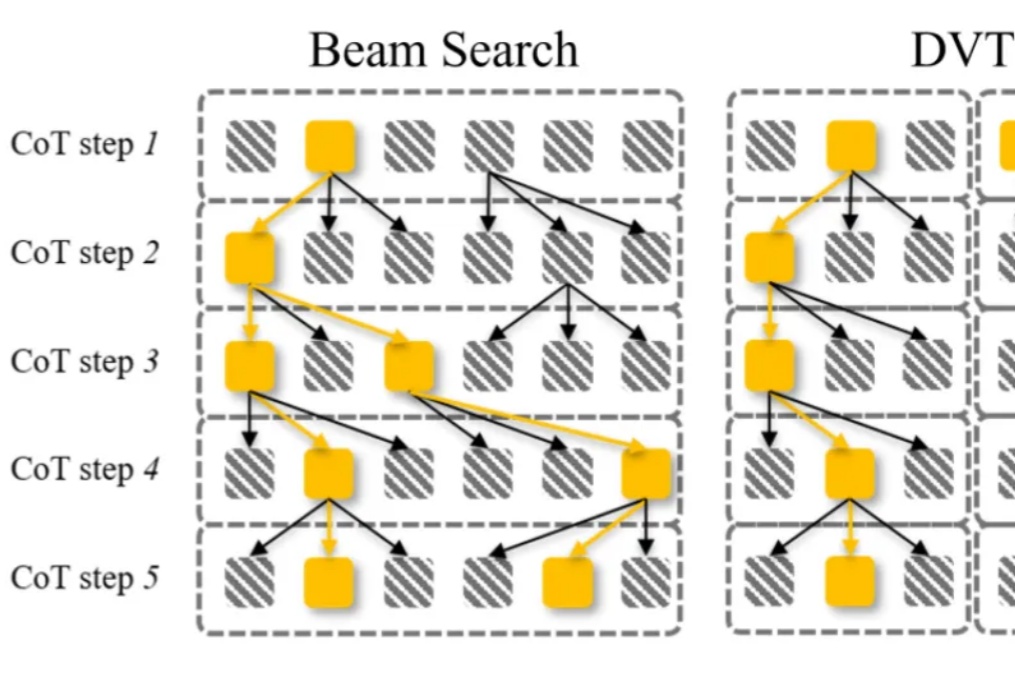
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。