
MiniMax海螺首次开源,发现了AI视觉生成领域的Scaling Law
MiniMax海螺首次开源,发现了AI视觉生成领域的Scaling Law2025 年还有一周结束,年底,AI 视频圈又卷起来了。
来自主题: AI技术研报
9429 点击 2025-12-22 16:02
 搜索
搜索
2025 年还有一周结束,年底,AI 视频圈又卷起来了。

AI不应是巨头游戏,模型也不是越大越聪明。近日,「Transformer八子」中的Ashish Vaswani和Parmar共同推出了一个8B的开源小模型,剑指Scaling Law软肋,为轻量化、开放式AI探索了新方向。
谷歌大模型将迎颠覆升级!Gemini负责人爆料:长上下文效率与长度双重突破在即,注意力机制迎来惊人发现。Scaling Law未死,正加速演变!

MiniMax 海螺视频团队「首次开源」了 VTP(Visual Tokenizer Pre-training)项目。他们同步发布了一篇相当硬核的论文,它最有意思的地方在于 3 个点:「重建做得越好,生成反而可能越差」,传统 VAE 的直觉是错的
压缩即智能,又有新进展!

智能体(Agent),即基于语言模型且具备推理、规划和行动能力的系统,正在成为现实世界 AI 应用的主导范式。
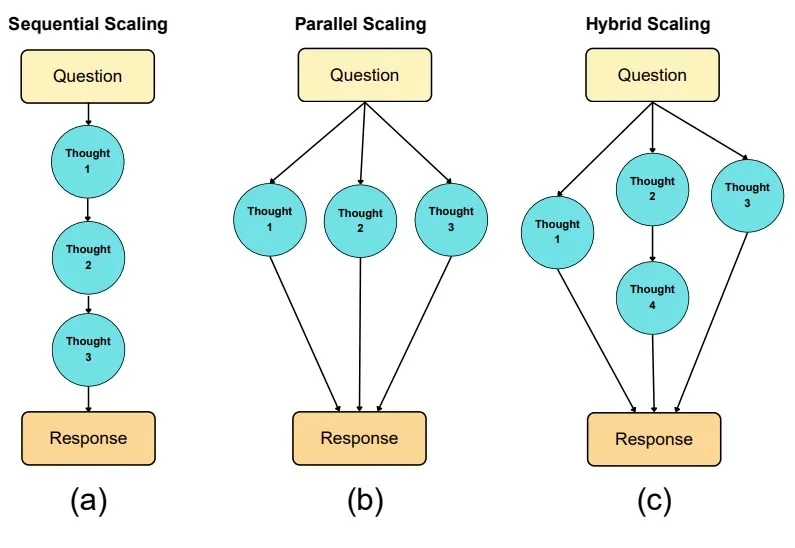
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。
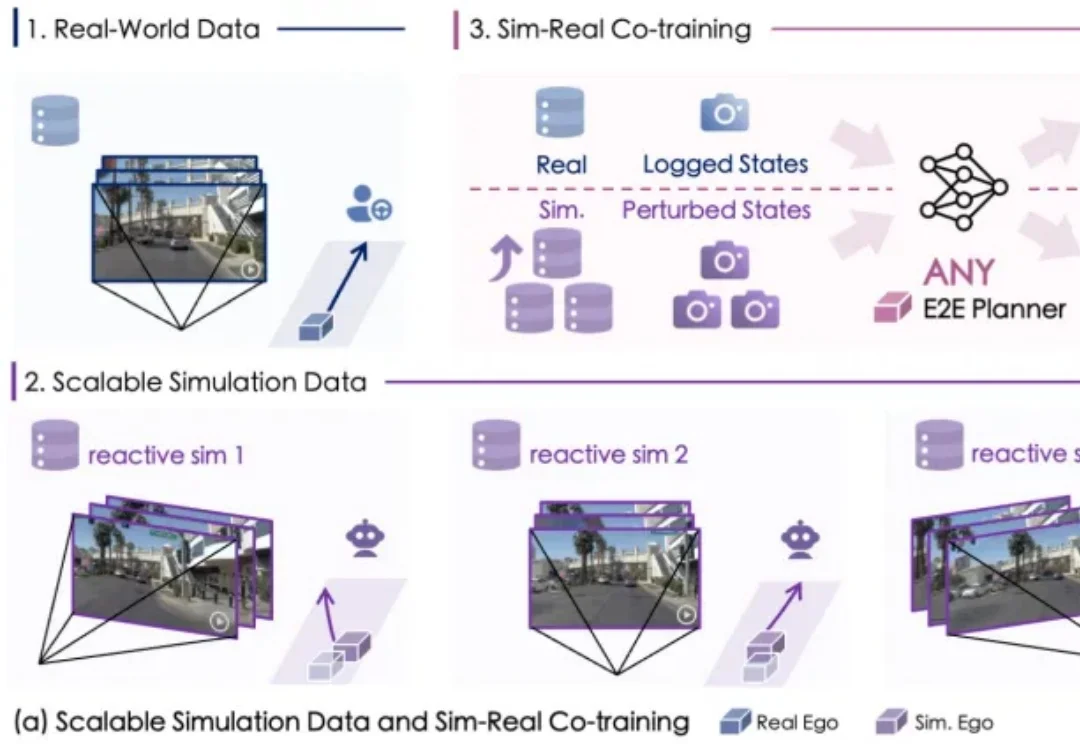
自动驾驶数据荒怎么破?

大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?

AI正从「规模时代」,重新走向「科研时代」。这是Ilya大神在最新采访中发表的观点。这一次,Ilya一顿输出近2万字,信息量爆炸,几乎把当下最热门的AI话题都聊了个遍:Ilya认为,目前主流的「预训练 + Scaling」路线已经明显遇到瓶颈。与其盲目上大规模,不如把注意力放回到「研究范式本身」的重构上。