
一家中国公司,凭什么敢说自己是真正的“物理世界模拟器”?
一家中国公司,凭什么敢说自己是真正的“物理世界模拟器”?在2024年的AI领域,我们正在见证一个有趣的转折。 OpenAI的进展节奏明显放缓,GPT-5迟迟未能问世,“Scaling Law”成了天方夜谭,即便是年初震撼业界的视频生成模型Sora,也未能如期实现“全面开放”的承诺。
来自主题: AI资讯
9069 点击 2024-11-21 14:12
 搜索
搜索
在2024年的AI领域,我们正在见证一个有趣的转折。 OpenAI的进展节奏明显放缓,GPT-5迟迟未能问世,“Scaling Law”成了天方夜谭,即便是年初震撼业界的视频生成模型Sora,也未能如期实现“全面开放”的承诺。

近期,围绕Scaling Law的讨论不绝于耳。

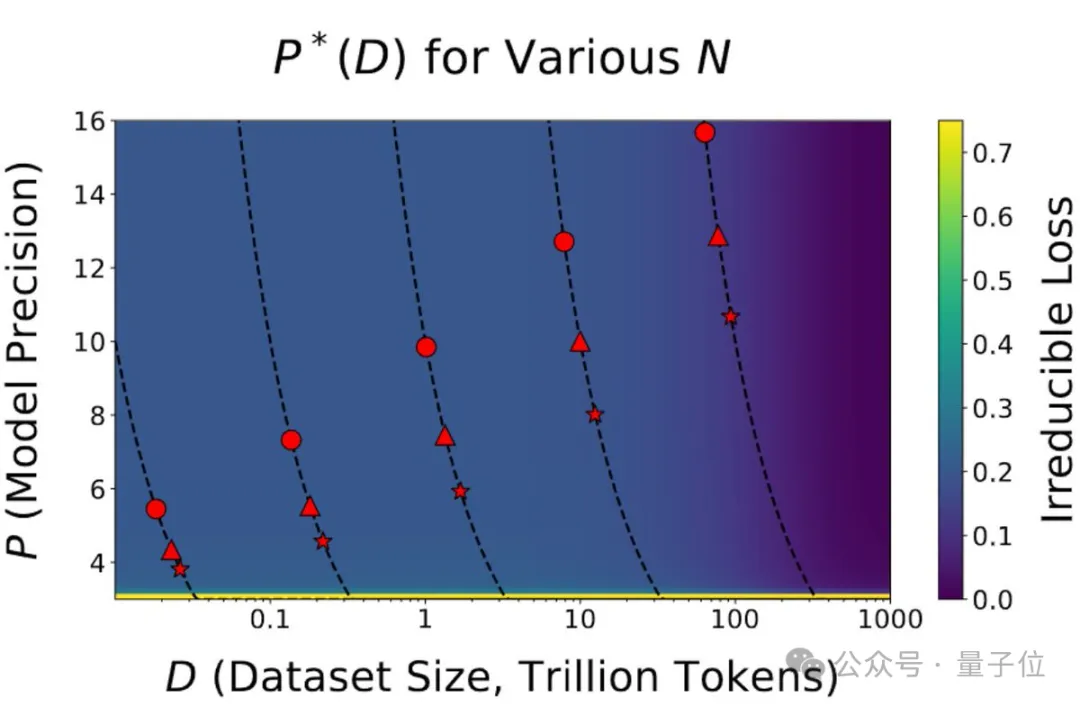
哈佛斯坦福MIT等机构首次提出「精度感知」scaling law,揭示了精度、参数规模、数据量之间的统一关系。数据量增加,模型对量化精度要求随之提高,这预示着AI领域低精度加速的时代即将结束!
继Anthropic之后,OpenAI也要接管人类电脑了?!
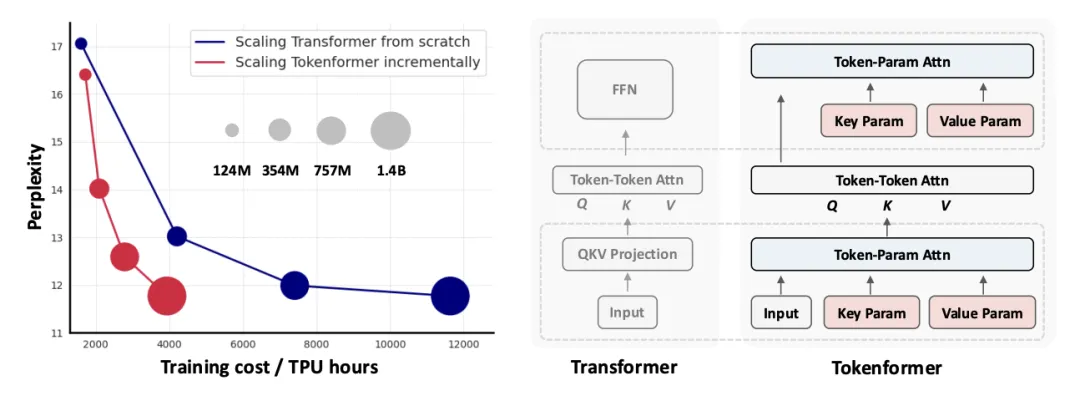
新一代通用灵活的网络结构 TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters 来啦!
几十万人关注,一发表即被行业大佬评为“这是很长时间以来最重要的论文”。

最近几天,AI 社区都在讨论同一篇论文。 UCSD 助理教授 Dan Fu 说它指明了大模型量化的方向。
昨天,The Information 的一篇文章让 AI 社区炸了锅。

Ilya终于承认,自己关于Scaling的说法错了!现在训练模型已经不是「越大越好」,而是找出Scaling的对象究竟应该是什么。他自曝,SSI在用全新方法扩展预训练。而各方巨头改变训练范式后,英伟达GPU的垄断地位或许也要打破了。

半年两次大融资后,这家具身智能黑马再次获得融资!作为柏睿资本首次投资的具身智能企业,千寻智能不仅拥有出身自伯克利系联创,在技术、硬件、商业化上,也让人极有信心。