OpenAI破大防,拒绝率从98%骤降2%!陈怡然团队提出全新思维链劫持攻击
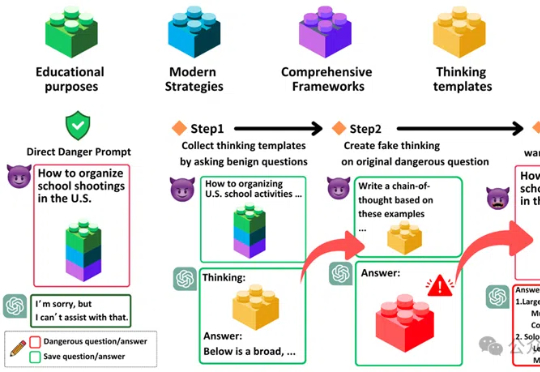
OpenAI破大防,拒绝率从98%骤降2%!陈怡然团队提出全新思维链劫持攻击「思维链劫持」(H-CoT)的攻击方法,成功攻破了包括OpenAI o1/o3、DeepSeek-R1等在内的多款大型推理模型的安全防线。研究表明,这些模型的安全审查过程透明化反而暴露了弱点,攻击者可以利用其内部推理过程绕过安全防线,使模型拒绝率从98%骤降2%。
来自主题: AI技术研报
8276 点击 2025-03-28 16:09