
第一个100%开源的MoE大模型,7B的参数,1B的推理成本
第一个100%开源的MoE大模型,7B的参数,1B的推理成本训练代码、中间 checkpoint、训练日志和训练数据都已经开源。
来自主题: AI技术研报
10728 点击 2024-09-05 22:02
 搜索
搜索
训练代码、中间 checkpoint、训练日志和训练数据都已经开源。

AnyGraph聚焦于解决图数据的核心难题,跨越多种场景、特征和数据集进行预训练。其采用混合专家模型和特征统一方法处理结构和特征异质性,通过轻量化路由机制和高效设计提升快速适应能力,且在泛化能力上符合Scaling Law。

最近 ACL 2024 论文放榜,扫了下,SMoE(稀疏混合专家)的论文不算多,这里就仔细梳理一下,包括动机、方法、有趣的发现,方便大家不看论文也能了解的七七八八,剩下只需要感兴趣再看就好。

以 GPT 为代表的大型语言模型预示着数字认知空间中通用人工智能的曙光。这些模型通过处理和生成自然语言,展示了强大的理解和推理能力,已经在多个领域展现出广泛的应用前景。无论是在内容生成、自动化客服、生产力工具、AI 搜索、还是在教育和医疗等领域,大型语言模型都在不断推动技术的进步和应用的普及。
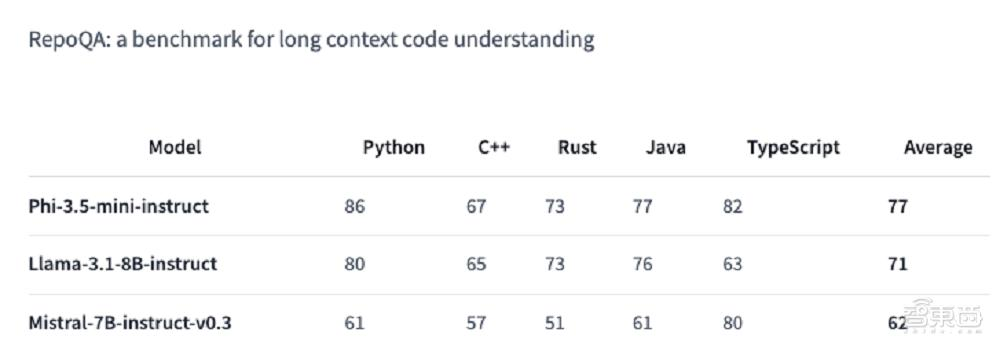
轻量级模型的春天要来了吗?
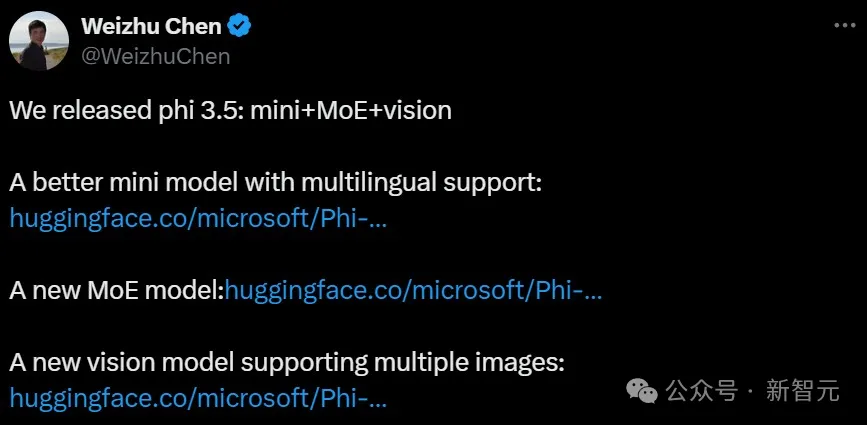
微软Phi 3.5系列上新了!mini模型小而更美,MoE模型首次亮相,vision模型专注多模态。

人工智能正经历一场由大模型引发的革命。这些拥有数十亿甚至万亿参数的庞然大物,正在重塑我们对 AI 能力的认知,也构筑起充满挑战与机遇的技术迷宫——从计算集群高速互联网络的搭建,到训练过程中模型稳定性和鲁棒性的提升,再到探索更快更优的压缩与加速方法,每一步都是对创新者的考验。

最近ACL 2024 论文放榜,扫了下,SMoE(稀疏混合专家)的论文不算多,这里就仔细梳理一下,包括动机、方法、有趣的发现,方便大家不看论文也能了解的七七八八,剩下只需要感兴趣再看就好。
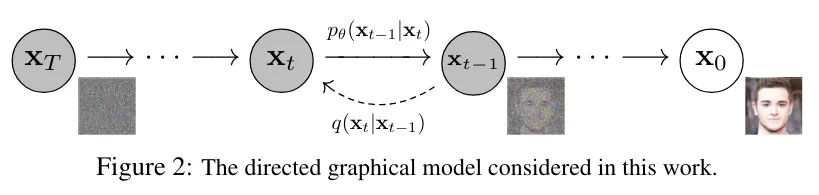
近日,来自加州大学尔湾分校等机构的研究人员,利用延迟掩蔽、MoE、分层扩展等策略,将扩散模型的训练成本降到了1890美元。

残暴的欢愉,终将以残暴结束。 当盛宴开启之时,没人想到,大模型的淘汰赛,会来的如此之快。 火药味首先表现在创投市场。PitchBook 最新报告披露,相比2023年一季度,全球2024年一季度大模型融资额,从216.9亿美元增长到了258.7亿美元,但涉及的交易数量,却从 1909 笔下滑至1545笔——产业格局正迅速向强者收拢。