
Kimi K2.6 + Hermes 实测!Karpathy同款保姆级教程来了
Kimi K2.6 + Hermes 实测!Karpathy同款保姆级教程来了月之暗面昨天发布了 Kimi K2.6,代码能力和 Agent 能力都有明显增强。官方数据很亮眼:13 小时不间断编码、4000 行代码重构、LMArena 全球开源第一。
来自主题: AI技术研报
6911 点击 2026-04-22 16:39
 搜索
搜索
月之暗面昨天发布了 Kimi K2.6,代码能力和 Agent 能力都有明显增强。官方数据很亮眼:13 小时不间断编码、4000 行代码重构、LMArena 全球开源第一。
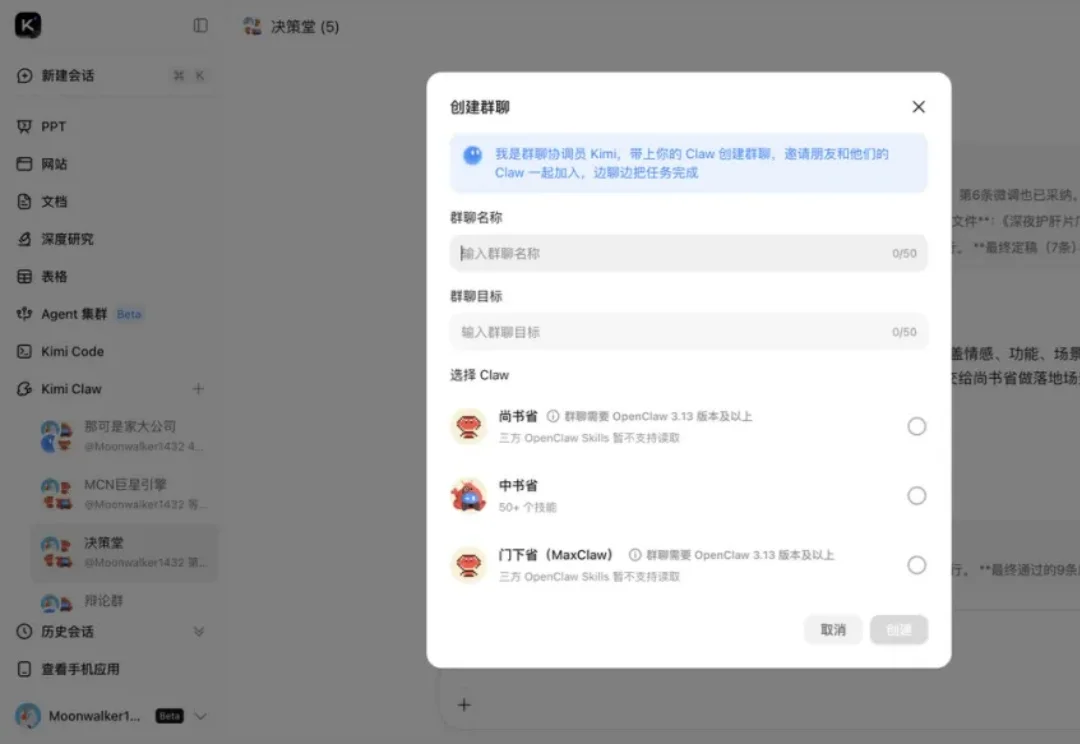
4 月的大模型战场,硝烟弥漫。

Kimi 刚刚发布了 K2.6,Agent 模式也同步大升级。

在 AI 工程界,长文本推理一直是个“富贵病”。
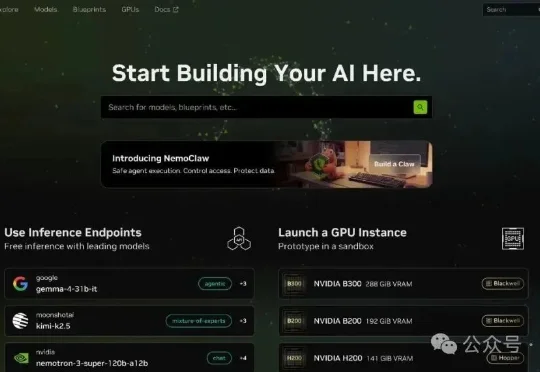
英伟达良心福利!免费领一年顶级大模型订阅,MiniMax / Kimi / DeepSeek 全都能用!NVIDIA 官方平台build.nvidia.com开放了一批"Free Endpoint"模型,注册账号、验证手机号后就能生成一把最长有效期12 个月的 API Key,免费调用几十个当下最火的大模型——不计 Token、无余额限制、无需信用卡。

今天,我们发布并开源 Kimi K2.6 模型,带来行业领先(state-of-the-art)的代码、长程任务执行和 Agent 集群能力。Kimi K2.6 现已上线 kimi.com、最新版 Kimi 应用、Kimi API 和 Kimi Code 编程助手,所有用户都可以开始使用。

杨植麟身上正在形成一种很典型的创业者光环。
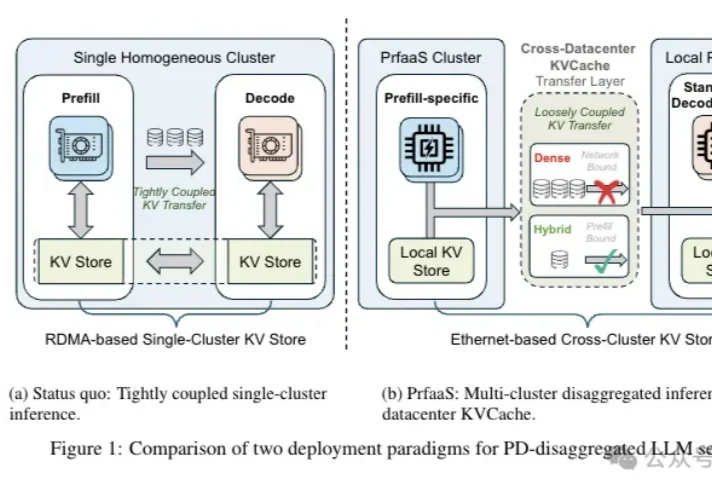
把长上下文做到极致的Kimi又发新成果!
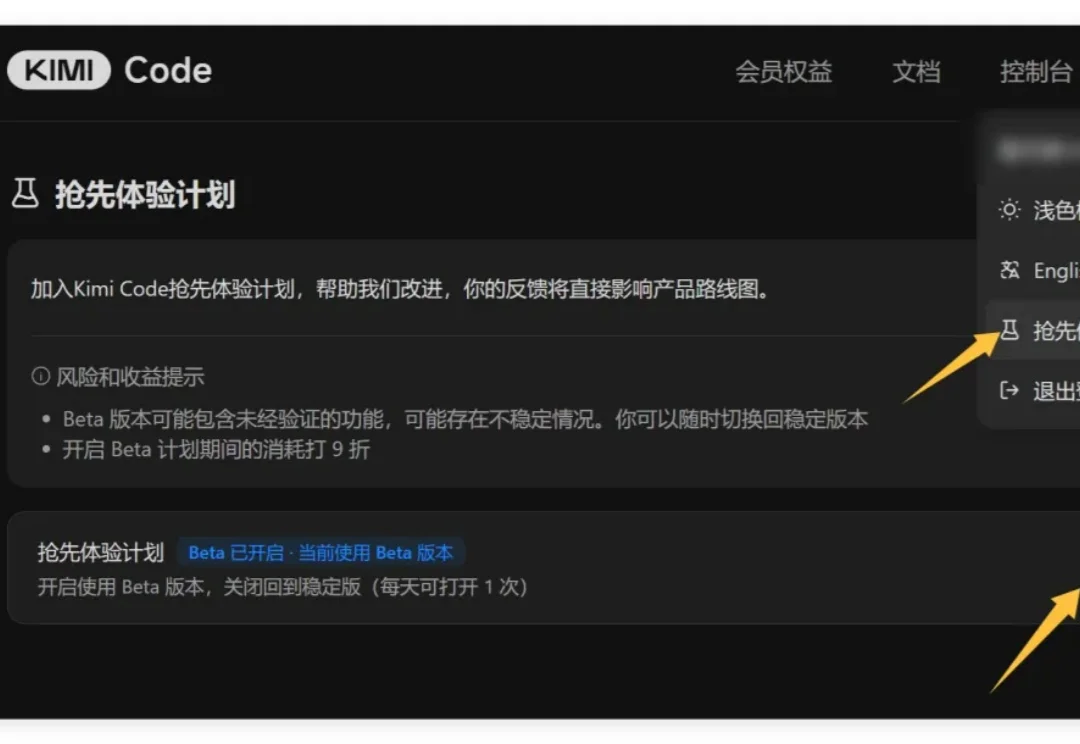
刚测完 Kimi K2.5,就拿到 Beta 版内测模型了。 一点喘息的机会都不给啊~~
今天,智谱正式开源其最强模型GLM-5.1,这一模型在专业软件开发基准测试SWE-Bench Pro中,GLM-5.1刷新全球最佳成绩,得分达到58.4,超过了GPT-5.4、Claude Opus 4.6等已经正式发布的闭源模型,和MiniMax M2.7、Kimi K2.5等开源模型。