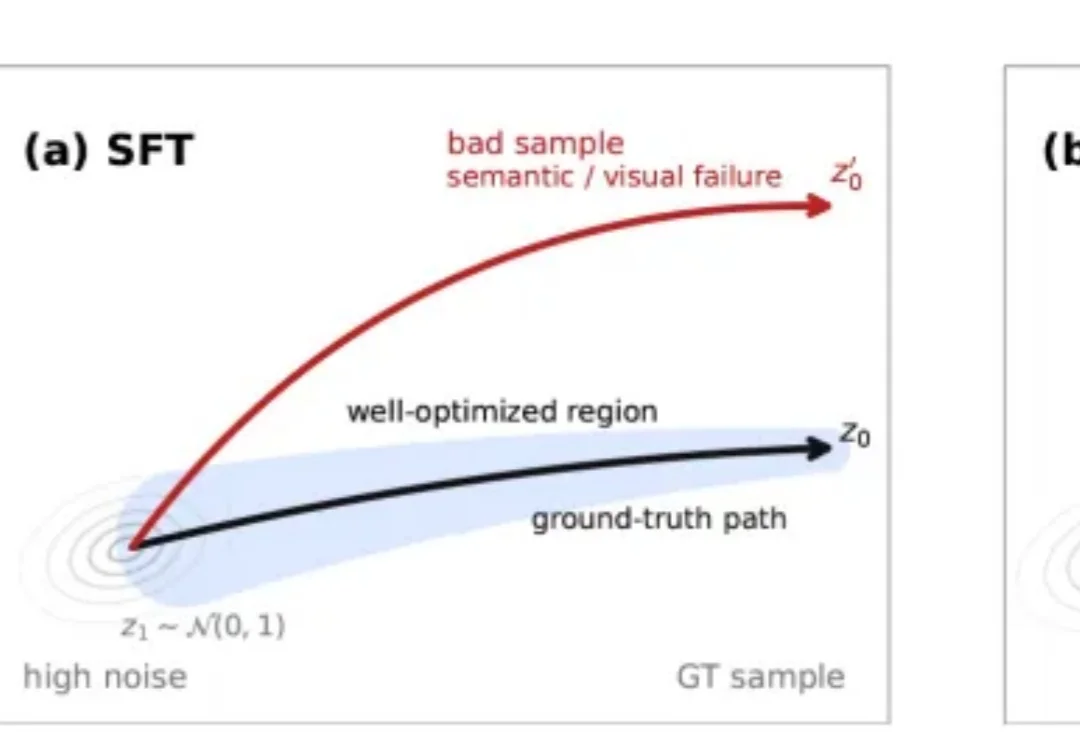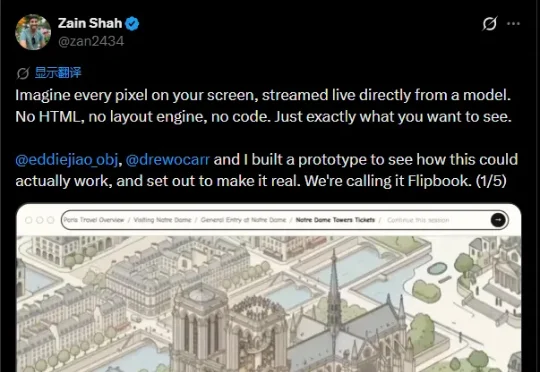
前OpenAI工程师团队推出 AI 原生无限视觉浏览器原型Flipbook,颠覆HTML!
前OpenAI工程师团队推出 AI 原生无限视觉浏览器原型Flipbook,颠覆HTML!想象一下:你打开浏览器,没有代码、没有 HTML、没有 CSS 布局引擎。屏幕上每一帧画面,都是 AI 模型实时生成的像素视频流。满满的科幻降临既视感!这就是 Zain Shah(前 OpenAI、YC 校友)和团队刚刚发布的 Flipbook 原型。
来自主题: AI资讯
11364 点击 2026-04-24 10:46