Hallo-Live 让文本驱动音视频数字人迈入实时流式生成
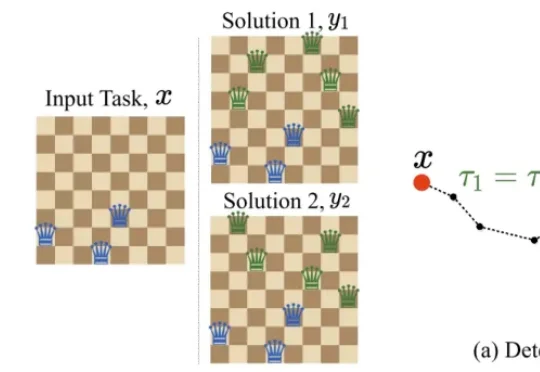
Hallo-Live 让文本驱动音视频数字人迈入实时流式生成最近,来自上海创智学院、复旦大学等机构的研究者提出了 Hallo-Live,试图正面解决这个矛盾。论文于 2026 年 4 月 26 日 发布在 arXiv。该方法将 异步双流扩散(Asynchronous Dual-Stream Diffusion) 与 人类偏好引导蒸馏(Human-Centric Preference-Guided DMD) 结合起来
来自主题: AI技术研报
8281 点击 2026-05-24 10:20