
最失败的AI硬件,被苹果 、OpenAI、 Meta抢着「复活」
最失败的AI硬件,被苹果 、OpenAI、 Meta抢着「复活」刚刚,The Information 曝光了 Meta 内部备忘录、说明年春天要推出一款 AI 吊坠,我的第一反应大概是,又来?但我发现,不只是 Meta,在之前苹果和 OpenAI 曝光的AI 硬件计划,你会发现那个两年前被判死刑的脖挂形态,正被行业巨头再次捡回来。
来自主题: AI资讯
9648 点击 2026-05-31 12:11
 搜索
搜索
刚刚,The Information 曝光了 Meta 内部备忘录、说明年春天要推出一款 AI 吊坠,我的第一反应大概是,又来?但我发现,不只是 Meta,在之前苹果和 OpenAI 曝光的AI 硬件计划,你会发现那个两年前被判死刑的脖挂形态,正被行业巨头再次捡回来。

Helio 做的是 AI Native Workforce——让 AI 同事成为团队的原住民。在 Helio 里,AI 不是侧边栏的助手按钮,不是输入框对面的服务员,而是坐你旁边工位的同事——拥有自己的名字、头像、邮箱,和真人一起出现在组织联系人列表里。
DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。

根据外媒 Axios 的最新报道,一位 AI 顾问告诉 Axios,他有个客户最近一个月在 Claude 上花了 5 亿美元。不是 500 万,不是 5000 万,是 500000000 美元,折合人民币三十三亿。
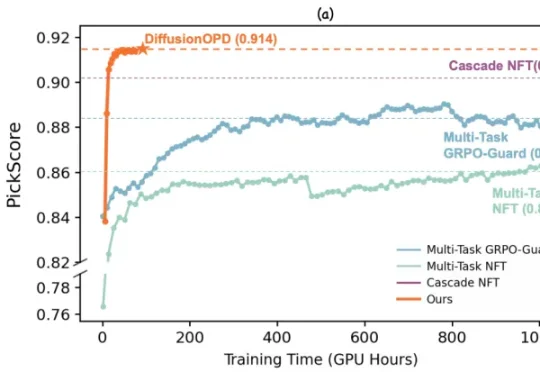
近期,来自复旦大学与阿里巴巴通义万相的研究团队对此提出了新的思考。他们认为,多任务强化学习不应被视为一个统一优化问题,而应该解耦为两个彼此独立的过程:单任务的在线策略探索 & 多任务能力整合。
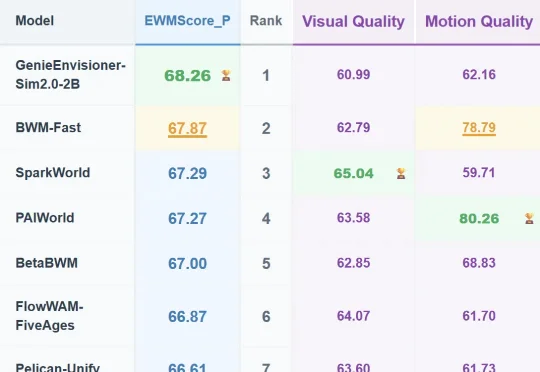
WorldArena 世界模型赛道从来都是竞争异常激烈,在经历了前几次比赛过程中的放榜之后,CVPR 2026 WorldArena 世界模型赛道锁定总成绩,智元自研的世界模型 Genie Envisioner-Sim 2.0(以下简称 GE 2.0)拿下了最终的冠军,成为了 “强者中的强者”。

近日,千寻智能高阳团队的研究成果 《Learning Native Continuation for Action Chunking Flow Policies》 被机器人顶会 RSS 2026 接收!这项工作从训练机制出发,让机器人动作天然具有连续性,实现了 "连音" 般的流畅执行,在五个真实世界操作任务上超越了现有方法,为具身智能领域的动作生成研究提供了新的思路。

扎尔伯格重金押注的AI蛋白质团队,拿出了最新成果。
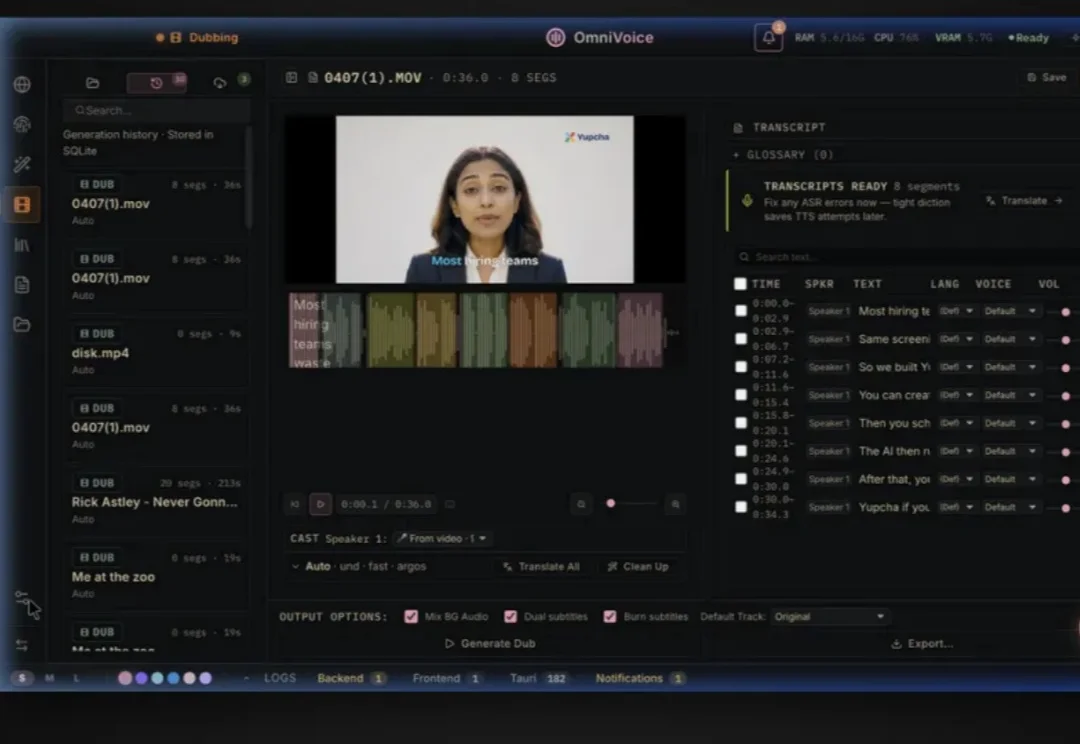
ElevenLabs的声音克隆和长文本音频生成质量确实很好,但也太贵了。
初创公司Axiom Math宣布,他们从2026年2月开始提交的8篇论文,到5月28日有5篇已经通过同行评审,登上学术期刊。创始人洪乐潼,2001年出生于广州,本科MIT三年拿下数学与物理双学位,还拿过北美数学本科生的最高荣誉罗德奖学金和摩根奖。