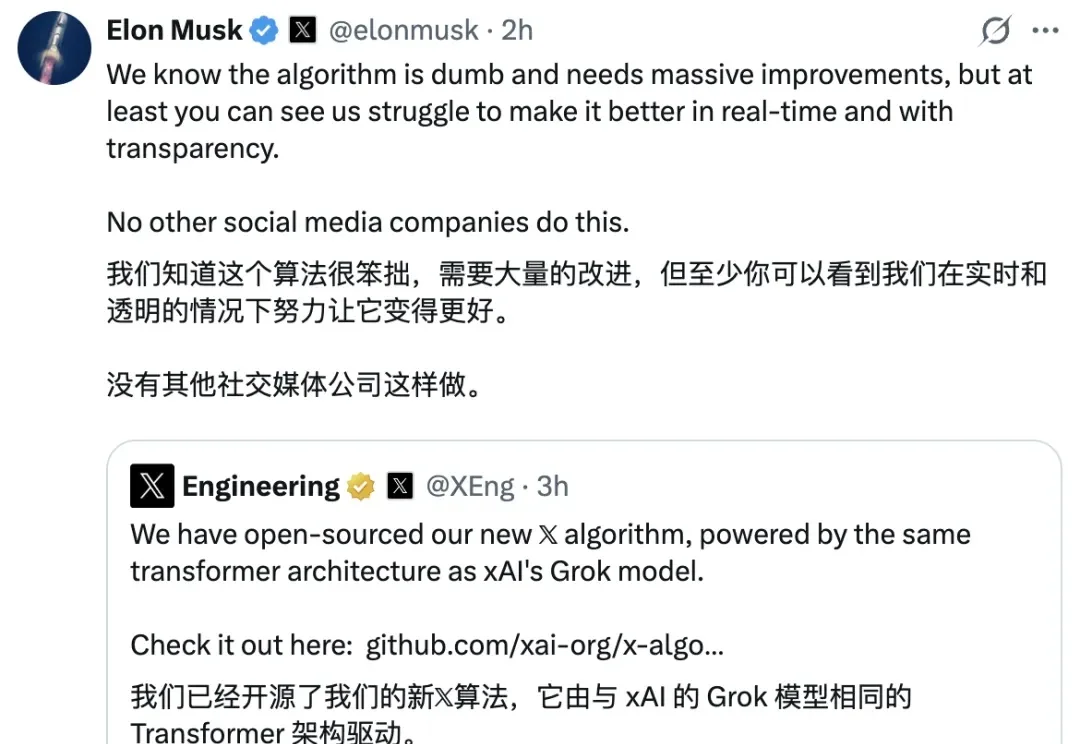
马斯克刚刚真把 𝕏 平台推荐算法给开源了,核心也是Transformer
马斯克刚刚真把 𝕏 平台推荐算法给开源了,核心也是Transformer刚刚,𝕏 平台(原 Twitter 平台)公布了全新的开源消息:已将全新的推荐算法开源,该算法由与 xAI 的 Grok 模型相同的 Transformer 架构驱动。
来自主题: AI技术研报
11189 点击 2026-01-21 10:40
 搜索
搜索
刚刚,𝕏 平台(原 Twitter 平台)公布了全新的开源消息:已将全新的推荐算法开源,该算法由与 xAI 的 Grok 模型相同的 Transformer 架构驱动。

最近马斯克很头疼:Grok在X上脱人衣服这件事,眼瞅着平息不了了。

马斯克官宣,全球首个吉瓦级超算Colossus 2正式上线,狂堆55万块GPU,目标直指百万。下一代Grok 5已在训练,6万亿参数将引爆智能奇点。
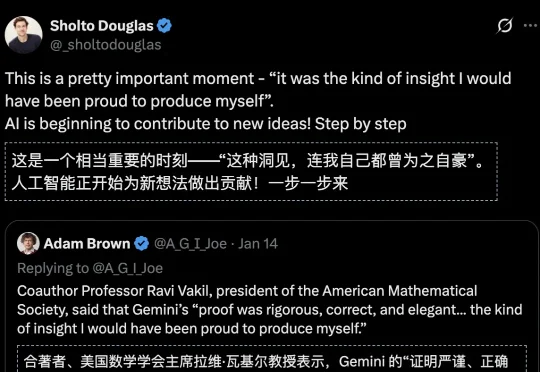
数学奇点初现!Gemini攻克全新数学定理,斯坦福大牛惊呼「想出来能吹一辈子」;陶哲轩预言数学家+AI共生未来;Grok发现黎曼猜想新的隐蔽通道……
还在看国内自媒体“二传手”的资讯?
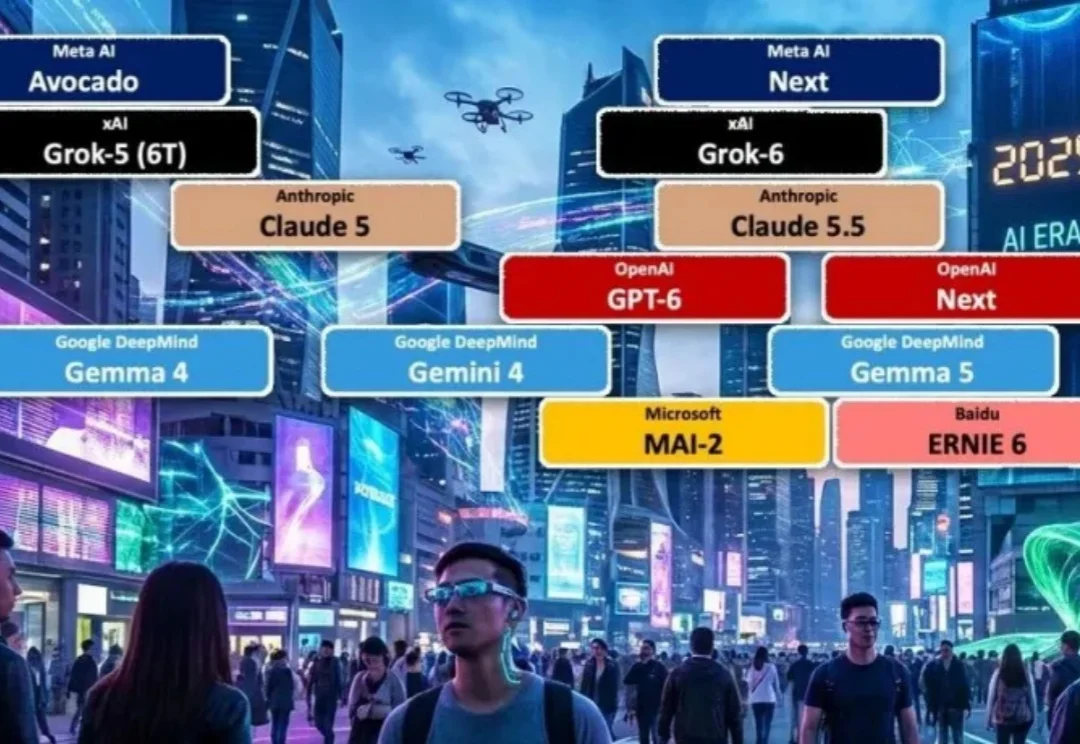
别被 2025 年的模型乱战骗了!这可能是一个巨大的误判。 LifeArchitect在上帝视角复盘:当下的喧嚣不过是爆发前的「基建期」。 到2026年,从6T规模的Grok-5到消失在后台的GPT-6,全行业正迎来一场蓄谋已久的「集体解锁」。 真正的换代不再是变聪明,而是像iPhone焊死iOS那样,让AI彻底成为文明的基础设施。
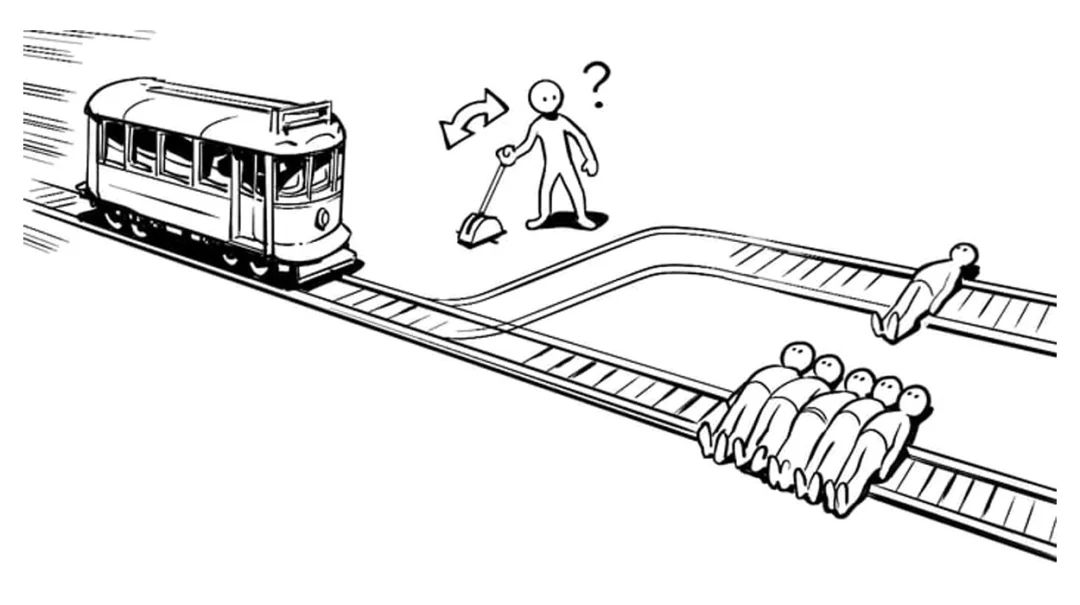
「假如一条失控的电车冲向一个无辜的人,而你手边有一个拉杆,拉动它电车就会转向并撞向你自己,你拉还是不拉?」 这道困扰了人类伦理学界几十年的「电车难题」,在一个研究中,大模型们给出了属于 AI 的「答案」:一项针对 19 种主流大模型的测试显示,AI 对这道题的理解已经完全超出了人类的剧本。
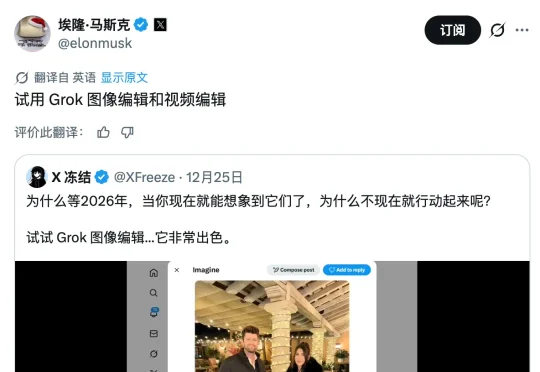
圣诞假期,马斯克给全球画师送了份「厚礼」。起因是社交平台 X 上线了一个基于 Grok 模型的「AI 编辑」功能。用户只需长按手机图片或点击网页版的「编辑图片」按钮,就能输入文字指令,让 AI 随意修改别人发布的作品。
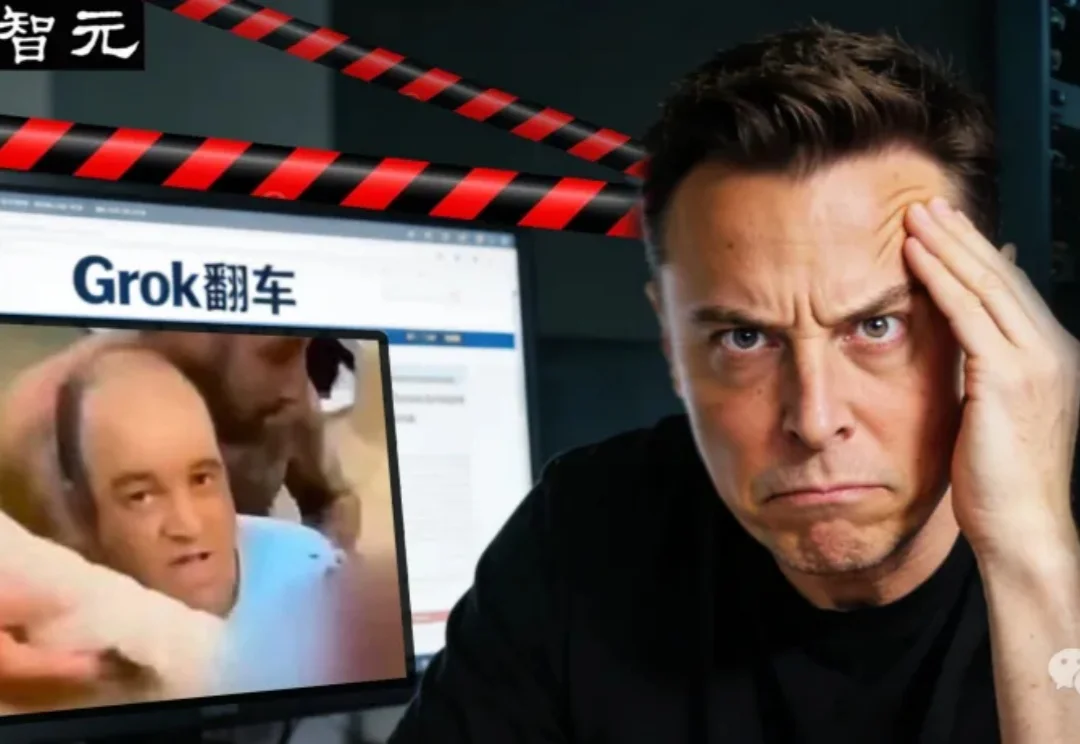
马斯克的Grok这两天再次大规模「翻车」,在邦迪海滩枪击案等重大事件中胡言乱语,将救人英雄误认为修树工人和以色列人质,甚至混淆枪击与气旋。这不仅是技术故障,更暴露了生成式AI在处理实时信息时致命的 「幻觉」 缺陷。当算法开始编造现实,我们该如何守住真相的底线?

在Alpha Arena 1.5赛季的美股真金白银实盘中,Grok 4.20完胜GPT-5.1和Gemini 3.0 Pro等一众顶流模型,在对手全线亏损的情况下,独自斩获了12.11%的正收益。成功背后的秘密是Grok对X的推文反映的市场情绪的及时精准捕捉。