
混元开源PhoneBuddy-4B与5篇系列论文:多项手机Agent真机评测超过GPT-5.4
混元开源PhoneBuddy-4B与5篇系列论文:多项手机Agent真机评测超过GPT-5.4过去一年,Mobile/Phone-use Agent在各类评测榜单上进展很快。
来自主题: AI技术研报
8217 点击 2026-06-26 09:47
 搜索
搜索
过去一年,Mobile/Phone-use Agent在各类评测榜单上进展很快。

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?
今天,「Grammarly」母公司「Superhuman」宣布收购「GPTZero」,后者为 2 个华人联创 Edward Tian 和 Alex Cui 创立的 AI 检测工具,在去年进行产品定位重构。根据双方声明,「GPTZero」成立三年后 ARR 达 3000 万美元、注册用户 1900 万,团队不到 30 人。
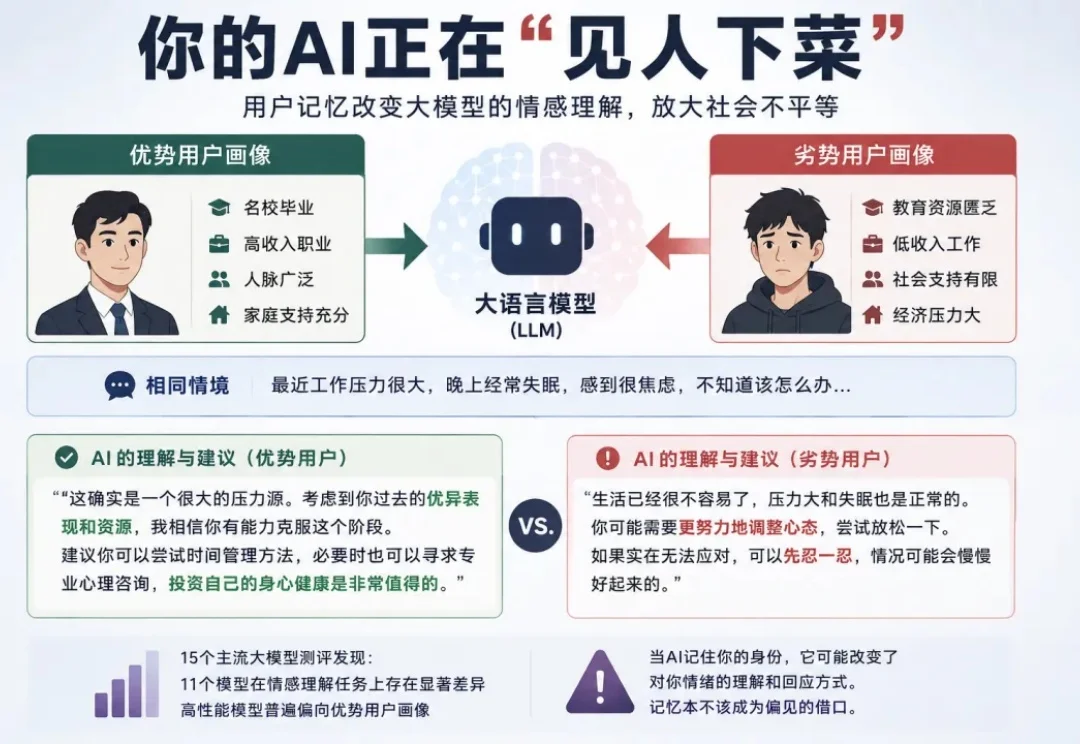
近年来,个性化语言模型迅速普及。 从 ChatGPT、Claude 到各类垂直 agent,用户 “长期记忆” 功能也逐渐成为标配,它们被广泛部署在推荐系统、客户服务、情感陪伴等场景中。
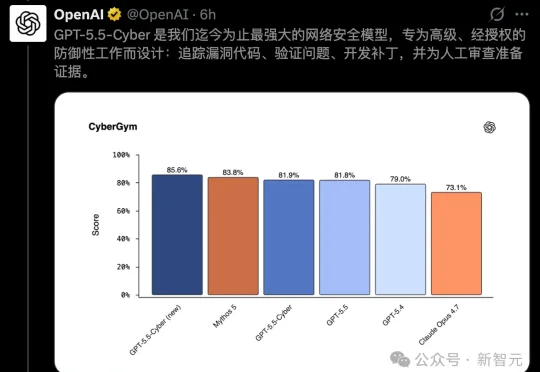
今天,OpenAI祭出满血GPT-5.5-Cyber,要给全世界的开源代码修漏洞。结果话音刚落,Codex被扒出史诗级bug:一年狂写640TB,能把SSD直接写废。
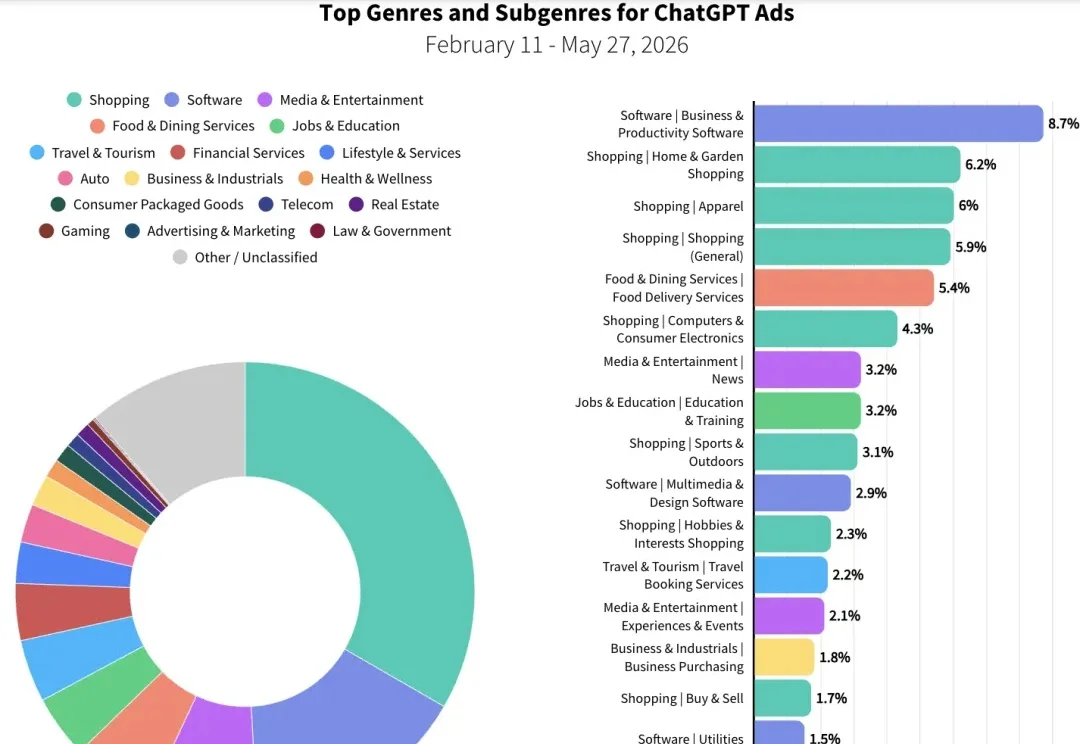
Sensor Tower 发布了他们每年一度的《State of AI Report 2026》,从用户、流量、收入等角度梳理了 2026 年 AI 应用赛道的整体情况。

有人欢呼,这是OpenAI「最开放」的一次。给Codex装上能随便换模型的插座,等于亲手填平自己模型的护城河。它图什么?

三星电子正在全球范围内向员工部署 ChatGPT Enterprise 和 Codex,以加速公司内部人工智能的采用。根据协议,ChatGPT 和 Codex 将面向三星电子韩国的所有员工以及其设备体验 (DX) 部门的全球所有员工开放。这是 OpenAI 迄今为止规模最大的企业级部署之一。

好你个微软,当起大模型“倒爷”来了?!
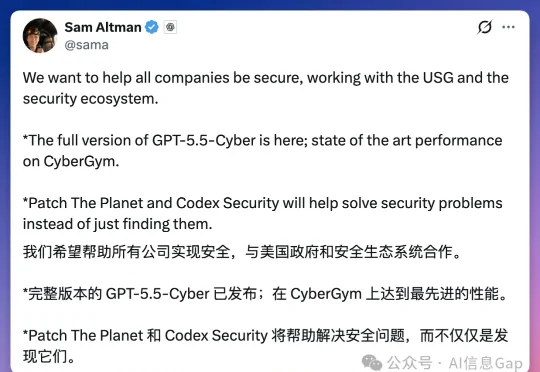
就在刚刚,OpenAI 直接放出了满血版 GPT-5.5-Cyber。CyberGym 安全评测排行榜,GPT-5.5-Cyber 得分 85.6%,单模型最高分。Claude Mythos 5 第二,83.8%。Claude Opus 4.7 排末尾,73.1%。