
GPT-4o成为全领域SOTA!基准测试远超Gemini和Claude,多模态功能远超GPT-4
GPT-4o成为全领域SOTA!基准测试远超Gemini和Claude,多模态功能远超GPT-4OpenAI半小时的发布会让很多人第一反应是直呼「失望」,但随着官网放出更多demo以及更多网友开始试用,大家才发现GPT-4o真的不可小觑,不仅在各种基准测试中稳拿第一,而且有很多发布会从未提及的惊艳功能。
来自主题: AI技术研报
9450 点击 2024-05-19 16:01
 搜索
搜索
OpenAI半小时的发布会让很多人第一反应是直呼「失望」,但随着官网放出更多demo以及更多网友开始试用,大家才发现GPT-4o真的不可小觑,不仅在各种基准测试中稳拿第一,而且有很多发布会从未提及的惊艳功能。

GPT-4o发布不到一周,首个敢于挑战王者的新模型诞生!最近,Meta团队发布了「混合模态」Chameleon,可以在单一神经网络无缝处理文本和图像。10万亿token训练的34B参数模型性能接近GPT-4V,刷新SOTA。

还有约165个大模型尚未获得“过审”机会。

是ChatGPT for Robotics最早适配的机器人品牌。

火热和洗牌并行,AI赛道到了残酷较量的阶段。

Ilya Sutskever离职内幕曝光,Sam Altman面临信任崩盘。

就在上周Google隆重举办I/O开发者大会的当天下午,消失在人们视野里半年之久的OpenAI联合创始人兼前首席科学家Ilya Sutskever忽然露面发声了。
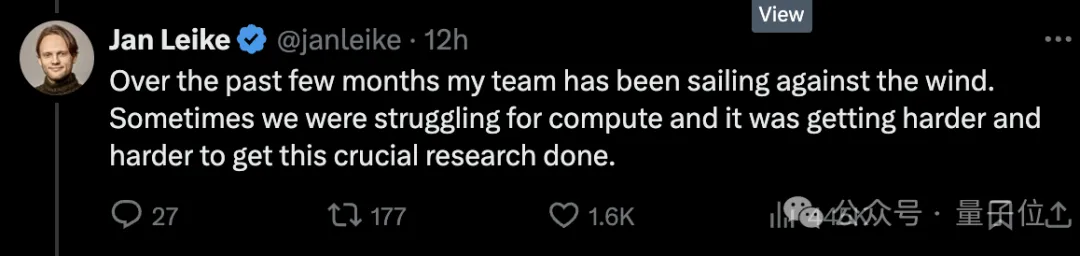
OpenAI超级对齐负责人Jan Leike,也就是刚刚追随Ilya离开公司的那位,自曝离职的真正原因,以及更多内幕。

谷歌表示,Gemini 1.5 相比 Claude 3.0 和 GPT-4 Turbo 实现了代际提升。

没有想到,OpenAI 在本周发布 GPT-4o,技术再次大幅度领先之后,随之迎来的却是一系列坏消息。