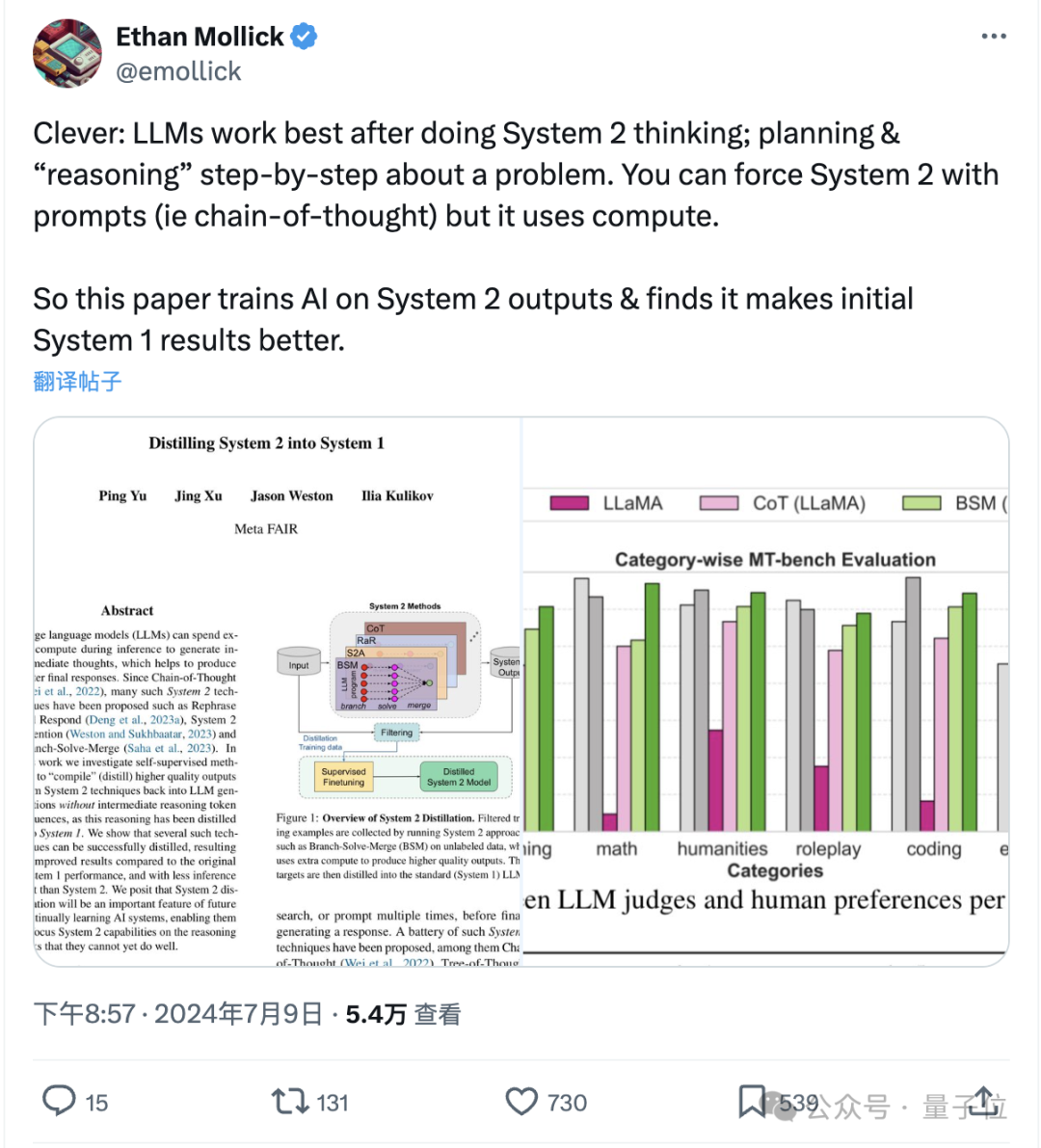
AI慢思考蒸馏进快思考,Llama2跃升至GPT-4水平,不写过程也能做对题
AI慢思考蒸馏进快思考,Llama2跃升至GPT-4水平,不写过程也能做对题《思考快与慢》中人类的两种思考方式,属实是被Meta给玩明白了。
来自主题: AI资讯
11645 点击 2024-07-12 15:44
 搜索
搜索
《思考快与慢》中人类的两种思考方式,属实是被Meta给玩明白了。

评估大模型是否诚实的基准来了!

大模型权威测试,翻车了?! HuggingFace都在用的MMLU-PRO,被扒出评测方法更偏向闭源模型,被网友直接在GitHub Issue提出质疑。

已经与OpenAI合作多年的微软,以及刚刚透露要加入董事会的苹果,这两天突然毫无征兆地宣布放弃董事会观察员席位。难道OpenAI真的要终止合作、决定单飞了?

四大 VLM,竟都在盲人摸象?

全球首个芯片设计开源大模型SemiKong正式发布,基于Llama 3微调而来,性能超越通用大模型。未来5年,SemiKong或将重塑价值5000亿美元的半导体行业。

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。

WHO 表示,1/3 的癌症可以通过早发现、早治疗得以治愈。

Anthropic首席执行官表示,当前AI模型训练成本是10亿美元,未来三年,这个数字可能会上升到100亿美元甚至1000亿美元。要知道,GPT-4o这个曾经最大的模型也只用了1亿美元。千亿美刀,究竟花在了哪里?

6月,IEEE刊登了一篇对ChatGPT代码生成任务进行系统评估的论文,数据集就是程序员们最爱的LeetCode题库。研究揭示了LLM在代码任务中出现的潜在问题和能力局限,让我们能够对模型做出进一步改进,并逐渐了解使用ChatGPT写代码的最佳姿势。