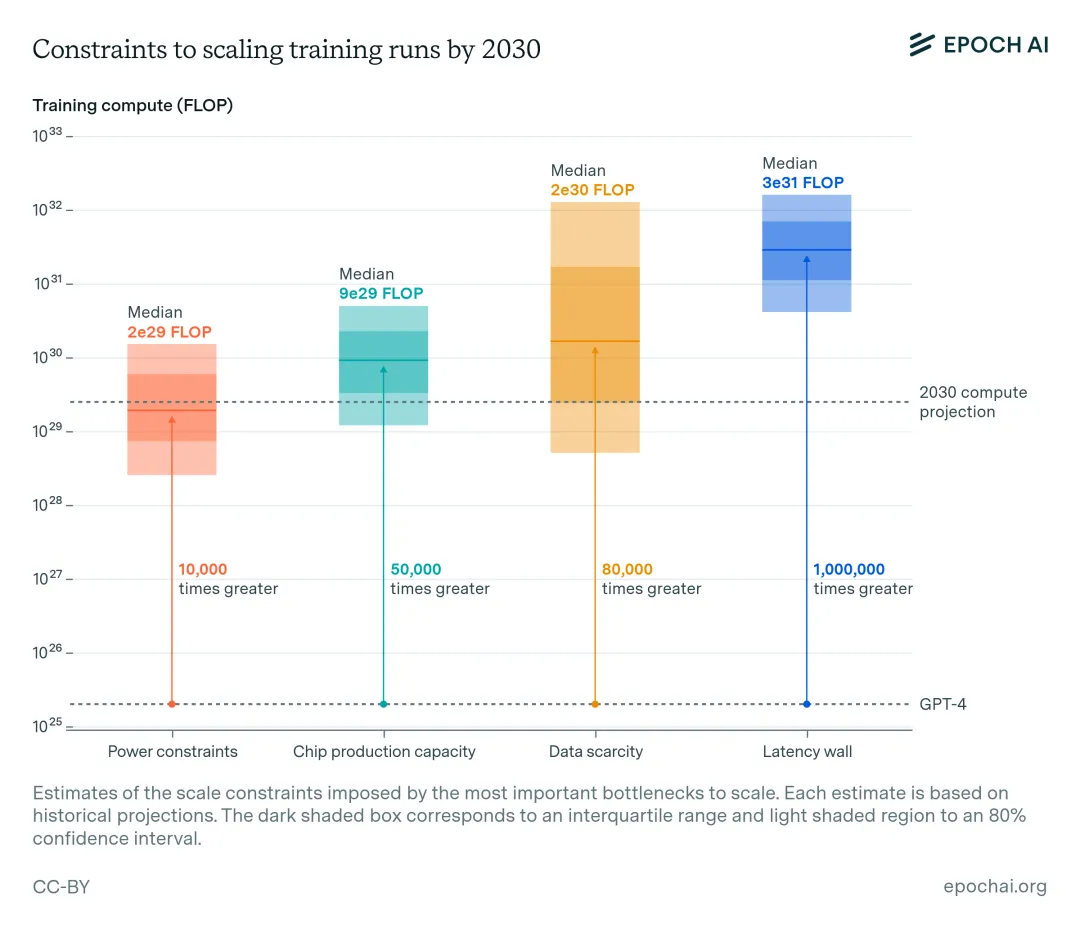
2030年,Scaling Law会到达极限吗?GPT-6能出来吗?
2030年,Scaling Law会到达极限吗?GPT-6能出来吗?9 月 2 日,马斯克发文称,其人工智能公司 xAI 的团队上线了一台被称为「Colossus」的训练集群,总共有 100000 个英伟达的 H100 GPU。
来自主题: AI资讯
6649 点击 2024-09-08 10:50
 搜索
搜索
9 月 2 日,马斯克发文称,其人工智能公司 xAI 的团队上线了一台被称为「Colossus」的训练集群,总共有 100000 个英伟达的 H100 GPU。

这并不代表行业增长不会强劲,下一波受益者可能来自,基于AI基础模型创建的新产品和服务。高盛报告称,科技行业基本面强劲,但集中度风险很高,建议寻求多元化投资,不错过其他行业由AI技术驱动的增长机会。

免训练多模态分割领域有了新突破!

提示工程师Riley Goodside小哥,依然在用「Strawberry里有几个r」折磨大模型们,GPT-4o在无限次PUA后,已经被原地逼疯!相比之下,Claude坚决拒绝PUA,是个大聪明。而谷歌最近的论文也揭示了本质原因:LLM没有足够空间,来存储计数向量。

沿着 Scaling Law、卷模型性能,可能会走到「死胡同」。

无论是OpenAI还是Canva,涨价背后的原因都让人猜测与融资相关。
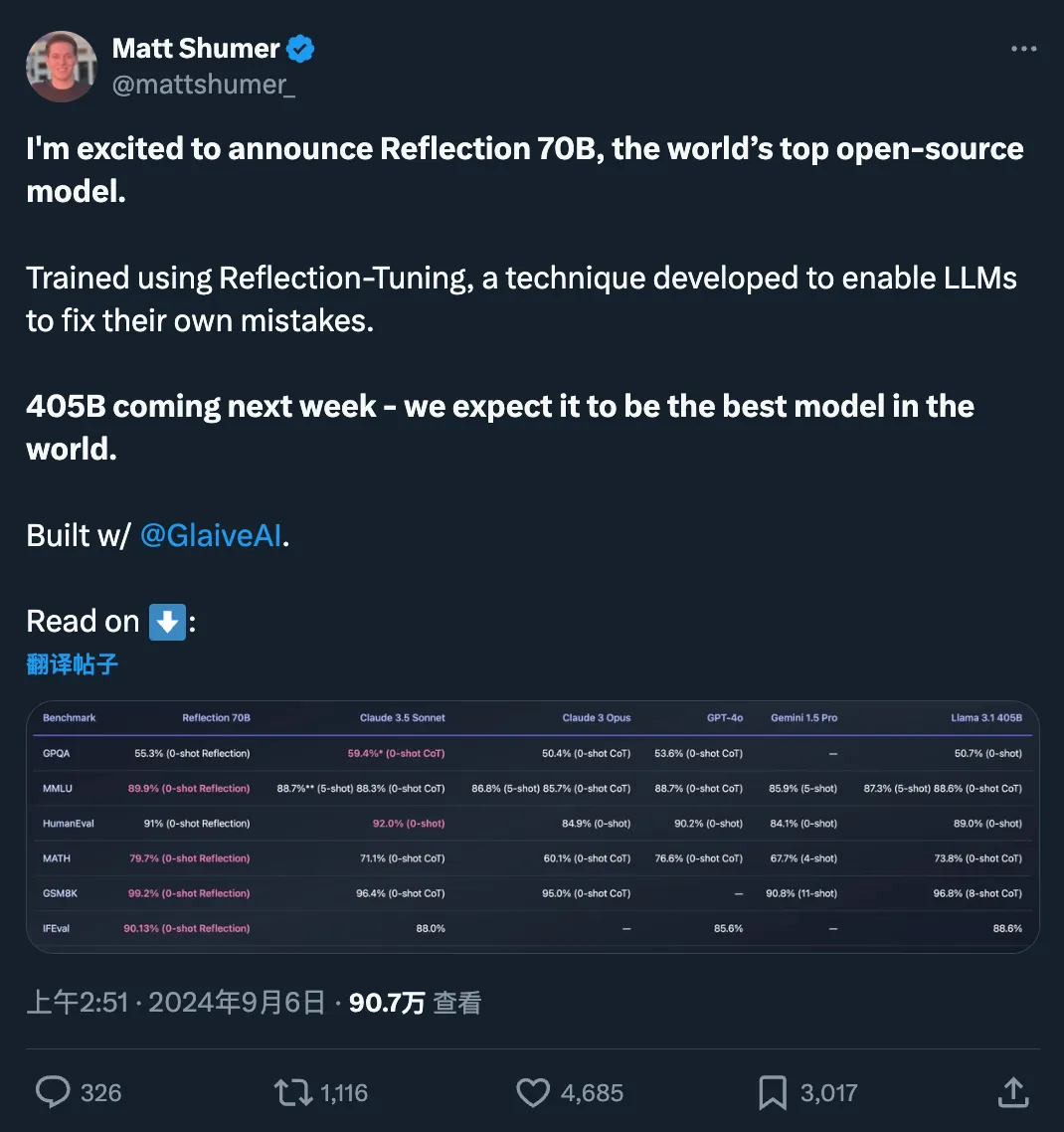
快速更迭的开源大模型领域,又出现了新王:Reflection 70B。 横扫 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。 这个新模型 Reflection 70B,来自 AI 写作初创公司 HyperWrite。
开源大模型王座突然易主,居然来自一家小创业团队,瞬间引爆业界。新模型名为Reflection 70B,使用一种全新训练技术,让AI学会在推理过程中纠正自己的错误和幻觉。

你敢相信 4B 参数小模型,性能却超越千亿量级的 GPT-3.5 !OpenAI、谷歌、微软、苹果等一众海内外巨头还没做到的事,被一家中国大模型公司抢先了!

继吴恩达在今年 4 月红杉 AI 峰会演讲过去之后,Agent > GPT5?吴恩达最新演讲:四种 Agent 设计范式(通俗易懂版)。