基于骨架的AI连笔书法生成的一些启发
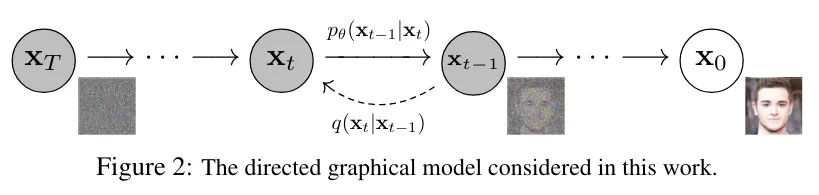
基于骨架的AI连笔书法生成的一些启发这篇文章是笔者之前AI手写连笔书法生成的一个工作,是联合中央美院几位非常知名的老师完成的。当时提出的思路相对简单,主要结构是基于对抗生成网络(GAN)。虽然方法在大模型横行今天可能已经不算太新颖,但近期一些基于diffusion的AIGC工作还是关注到了这篇文章,并产生了一些启发。笔者认为这些灵感仍具有一定价值,因此在这里做个分享。由于一些公式和指标不太友好,为了不影响阅读故省略。
来自主题: AI资讯
12063 点击 2024-09-05 16:20