CityDreamer4D: 下一个世界模型,何必是视频生成模型?
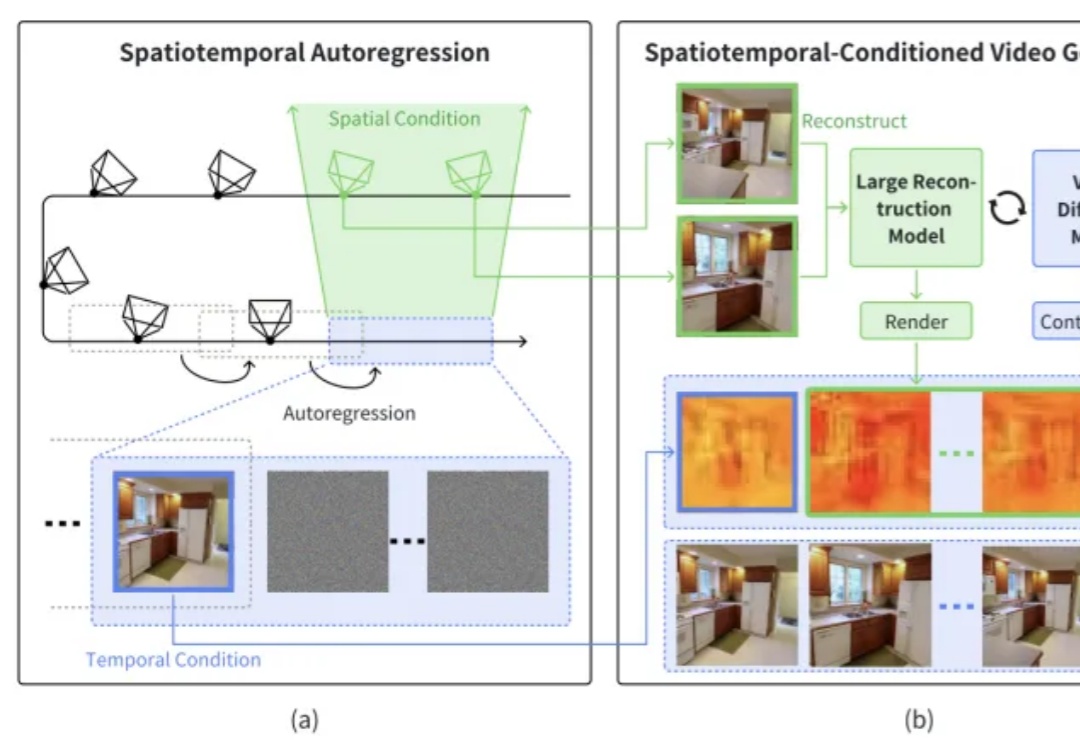
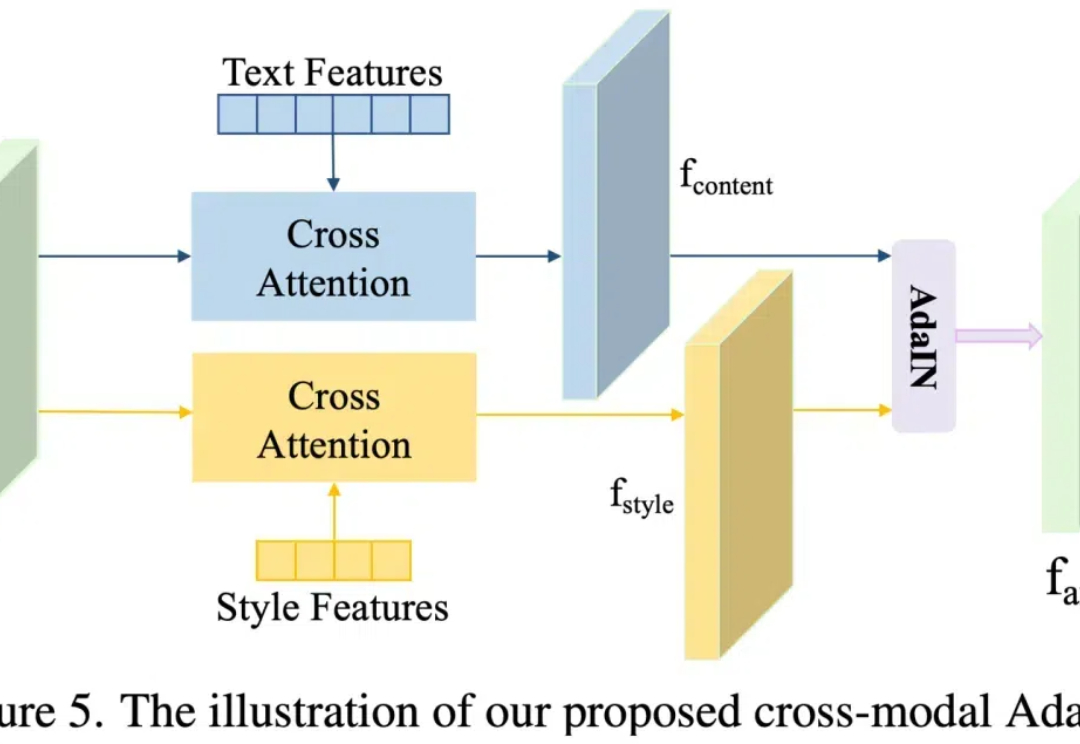
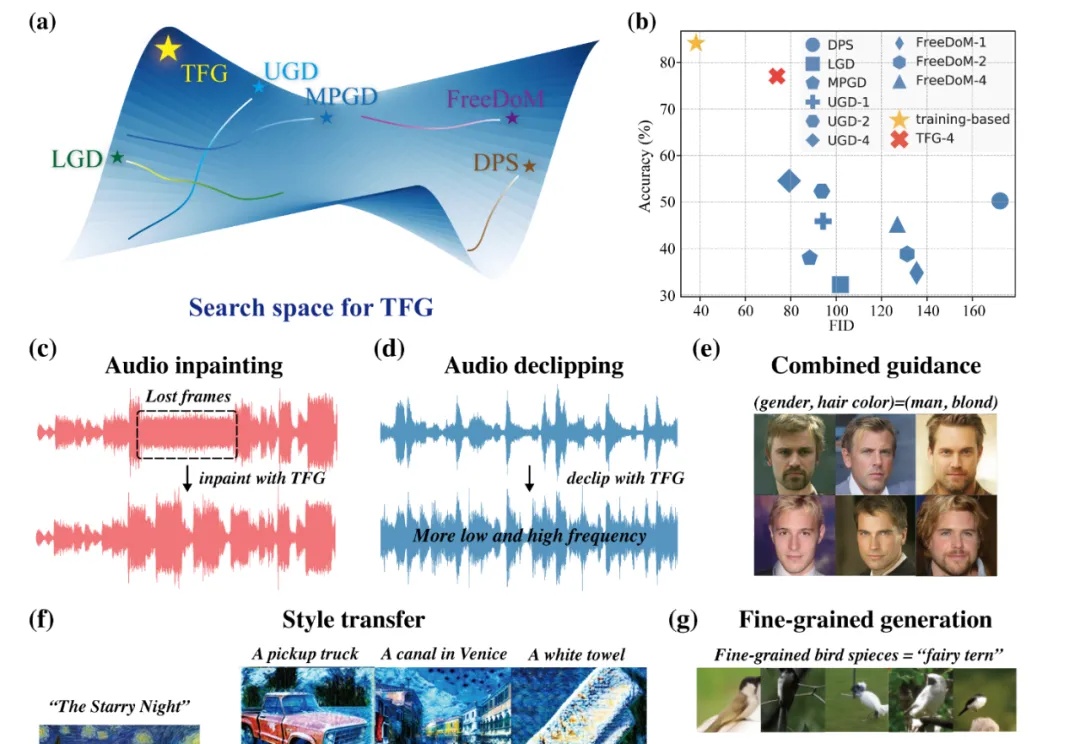
CityDreamer4D: 下一个世界模型,何必是视频生成模型?在过去的两年里,城市场景生成技术迎来了飞速发展,一个全新的概念 ——世界模型(World Model)也随之崛起。当前的世界模型大多依赖 Video Diffusion Models(视频扩散模型)强大的生成能力,在城市场景合成方面取得了令人瞩目的突破。然而,这些方法始终面临一个关键挑战:如何在视频生成过程中保持多视角一致性?
来自主题: AI技术研报
8068 点击 2025-01-28 11:53