
a16z全球AI产品Top100:中国14款产品上榜,DeepSeek第2,Monica第41
a16z全球AI产品Top100:中国14款产品上榜,DeepSeek第2,Monica第41短短六个月,面向消费者的生成式 AI 市场已发生翻天覆地的变化。一些产品迅速崭露头角,另一些却止步不前,还有意外的黑马一跃成为行业领跑者。
来自主题: AI资讯
8871 点击 2025-03-08 14:32
 搜索
搜索
短短六个月,面向消费者的生成式 AI 市场已发生翻天覆地的变化。一些产品迅速崭露头角,另一些却止步不前,还有意外的黑马一跃成为行业领跑者。

见识过32B的QwQ追平671的DeepSeek R1后——刚刚,7B的DeepSeek蒸馏Qwen模型超越o1又是怎么一回事?新方法LADDER,通过递归问题分解实现AI模型的自我改进,同时不需要人工标注数据。
仅仅过了一天,阿里开源的新一代推理模型便能在个人设备上跑起来了!昨天深夜,阿里重磅开源了参数量 320 亿的全新推理模型 QwQ-32B,其性能足以比肩 6710 亿参数的 DeepSeek-R1 满血版。
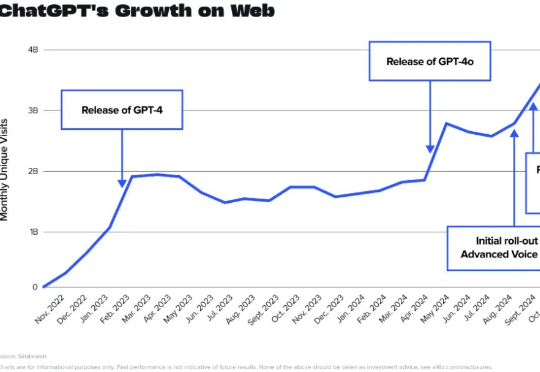
知名风险投资公司 Andreessen Horowitz (a16z) 周四刚刚发布了新报告。报告发现,ChatGPT 用了 9 个月的时间从 2023 年 11 月的每周 1 亿活跃用户增长到 2024 年 8 月的 2 亿,但现在该应用程序只用了不到六个月的时间就再次将这一数字翻了一番。

让人感到非常费解的是,在这些媒体口中如此“王炸”的 AI 突破,在海外几乎没有什么讨论,这与 DeepSeek 墙内开花墙外香,海外各路 AI 大神们甘当自来水疯狂吹爆的现象形成了巨大的反差

只有享不了的福,\x0d\x0a没有受不了的罪。

M3 Ultra终极引擎,可跑千亿模型
仅用32B,就击败o1-mini追平671B满血版DeepSeek-R1!阿里深夜重磅发布的QwQ-32B,再次让全球开发者陷入狂欢:消费级显卡就能跑,还一下子干到推理模型天花板!
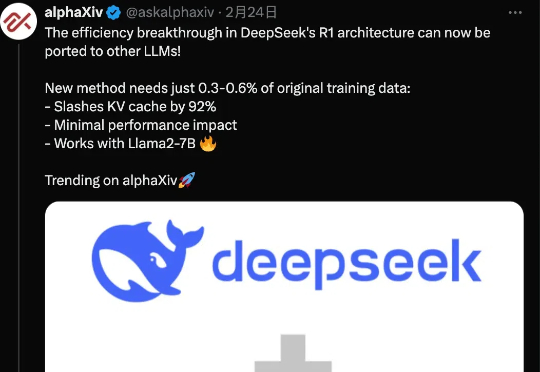
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。

Manus刷屏一天,从开始的一夜成名,到中间的一码难求,再到质疑它的宣发一掷千金,整个过程里,FOMO情绪和直觉警惕交缠不休,是很有意思的传播学样本。