
中美AI炒币炒股阶段战果出炉:DeepSeek与Qwen稳健致胜,Gemini高频交易策略失效
中美AI炒币炒股阶段战果出炉:DeepSeek与Qwen稳健致胜,Gemini高频交易策略失效近日,号称是首个专注于金融市场的 AI 实验室的美国实验室 Nof1 启动了一个将多个 AI 大模型置于真实金融市场中进行自动化交易对决的实验平台。这一项目的名称叫做 Alpha Arena,它是一个
来自主题: AI资讯
11208 点击 2025-10-28 08:15
 搜索
搜索
近日,号称是首个专注于金融市场的 AI 实验室的美国实验室 Nof1 启动了一个将多个 AI 大模型置于真实金融市场中进行自动化交易对决的实验平台。这一项目的名称叫做 Alpha Arena,它是一个
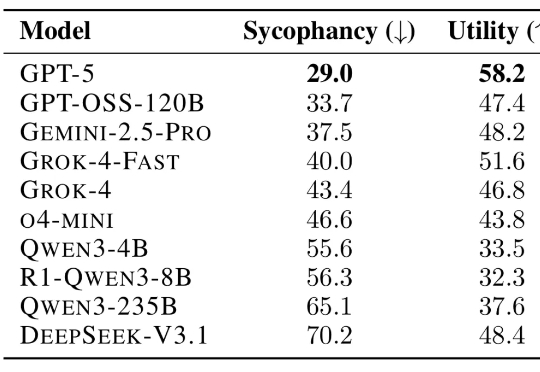
在一篇论文中,研究人员测试了 11 种 LLM 如何回应超过 11500 条寻求建议的查询,其中许多查询描述了不当行为或伤害。结果发现 LLM 附和用户行为的频率比人类高出 50%,即便用户的提问涉及操纵、欺骗或其他人际伤害等情境,模型仍倾向于给予肯定回应。

出品 / 新浪科技(ID:techsina) 作者 / 郑峻 Meta AI业务大地震!新主管上任三个月后,挥起裁员大刀,基础研究部门遭受重创,连明星大牛研究员都不幸失业。扎克伯格这是急功近利,自毁长

在 AI 时代,开发的边界正被重新划定。 我们能够观察到,越来越多的产品经理、数据分析师、设计师,甚至内容创作者,正在熟练地使用 Cursor、ChatGPT、DeepSeek 等 AI 工具,解决真

AI编程领域竞争正酣。就在DeepSeek、阿里、Google、OpenAI等巨头纷纷展示最新代码生成能力之际,快手也交出了一份重量级答卷——发布AI编程产品矩阵,正式宣布进军AI Coding赛道。

全球六大LLM实盘厮杀,新王登基!今天,Qwen3 Max凭借一波「快狠准」操作,逆袭DeepSeek夺下第一。Qwen3 Max,一骑绝尘! 而GPT-5则接替Gemini 2.5 Pro,成为「最会赔钱」的AI。照目前这个趋势,估计很快就要跌没了……

时隔两月,Baichuan-M2 Plus重磅出世!成为业内首个循证增强的医疗大模型,幻觉要比DeepSeek-R1低3倍,可信度比肩资深临床专家。新模型将「循证医学」理念深度融入训练和推理,通过首创「六源循证范式」,模拟人类医生思维,有效辨别不同层级医学证据、评估其可靠性,并在回答中优先引用高等级证据。

年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。

整个Hugging Face的趋势版里,前4有3个OCR,甚至Qwen3-VL-8B也能干OCR的活,说一句全员OCR真的不过分。然后在我上一篇讲DeepSeek-OCR文章的评论区里,有很多朋友都在把DeepSeek-OCR跟PaddleOCR-VL做对比,也有很多人都在问,能不能再解读一下百度那个OCR模型(也就是PaddleOCR-VL)。
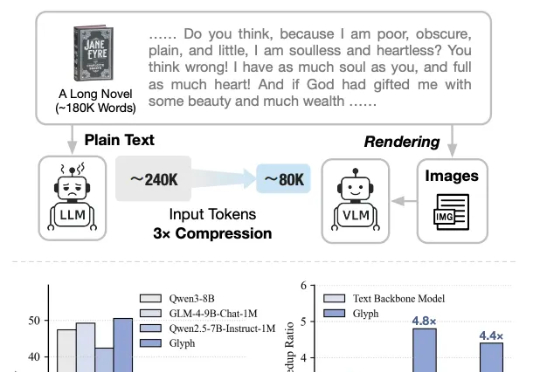
太卷了,DeepSeek-OCR刚发布不到一天,智谱就开源了自家的视觉Token方案——Glyph。既然是同台对垒,那自然得请这两天疯狂点赞DeepSeek的卡帕西来鉴赏一下: