
又是中国团队!一条链接出片,电商AI视频迎来「DeepSeek时刻」
又是中国团队!一条链接出片,电商AI视频迎来「DeepSeek时刻」Sora画下的饼终于被做熟了!用DeepSeek式的慢思考逻辑,把AI视频从「看运气抽卡」变成了「确定性交付」,这才是电商人真正需要的工业革命。
来自主题: AI资讯
8879 点击 2026-01-27 10:19
 搜索
搜索
Sora画下的饼终于被做熟了!用DeepSeek式的慢思考逻辑,把AI视频从「看运气抽卡」变成了「确定性交付」,这才是电商人真正需要的工业革命。
“DeepSeek-V3是在Mistral提出的架构上构建的。”
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。
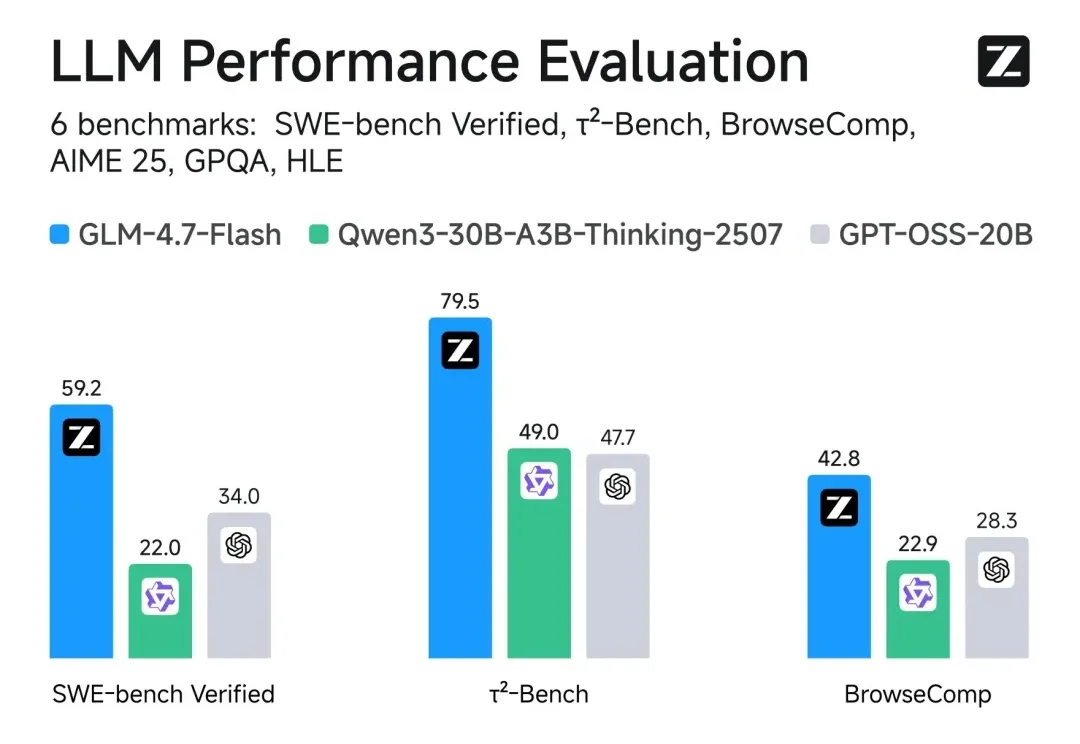
智谱AI上市后,再发新成果。

AI变聪明的真相居然是正在“脑内群聊”?!
2025 年 1 月 20 日,DeepSeek(深度求索)正式发布了 DeepSeek-R1 模型,并由此开启了新的开源 LLM 时代。在 Hugging Face 刚刚发布的《「DeepSeek 时刻」一周年记》博客中,DeepSeek-R1 也是该平台上获赞最多的模型。

当 DeepSeek 和 OpenAI 的核心突破者越来越年轻,传统的简历筛选正在失效。一位前阿里达摩院的研究员,试图用 Agent 编织一张能捕捉「下一个 Ilya」的网。

「服务器繁忙,请稍后再试。」

元旦期间,DeepSeek 发布的 mHC 震撼了整个 AI 社区。

面对《the Big Technology Podcast》抛出的问题,Mistral AI的 CEO Arthur Mensch 表示:大模型肯定会走向商品化,当模型表现越来越接近,那么竞争就不在于模型本身,而在于如何让客户用起来。