
Claude Mythos核心架构开源!22岁天才一人破解,融合DeepSeek思路
Claude Mythos核心架构开源!22岁天才一人破解,融合DeepSeek思路Claude Mythos核心架构,竟被一个22岁天才扒了个精光!OpenMythos现已全开源,不靠堆参数,原地「循环思考」16次就能推理。闭源实验室的护城河,真的还在吗?
来自主题: AI资讯
7729 点击 2026-04-21 10:25
 搜索
搜索
Claude Mythos核心架构,竟被一个22岁天才扒了个精光!OpenMythos现已全开源,不靠堆参数,原地「循环思考」16次就能推理。闭源实验室的护城河,真的还在吗?
英伟达良心福利!免费领一年顶级大模型订阅,MiniMax / Kimi / DeepSeek 全都能用!NVIDIA 官方平台build.nvidia.com开放了一批"Free Endpoint"模型,注册账号、验证手机号后就能生成一把最长有效期12 个月的 API Key,免费调用几十个当下最火的大模型——不计 Token、无余额限制、无需信用卡。
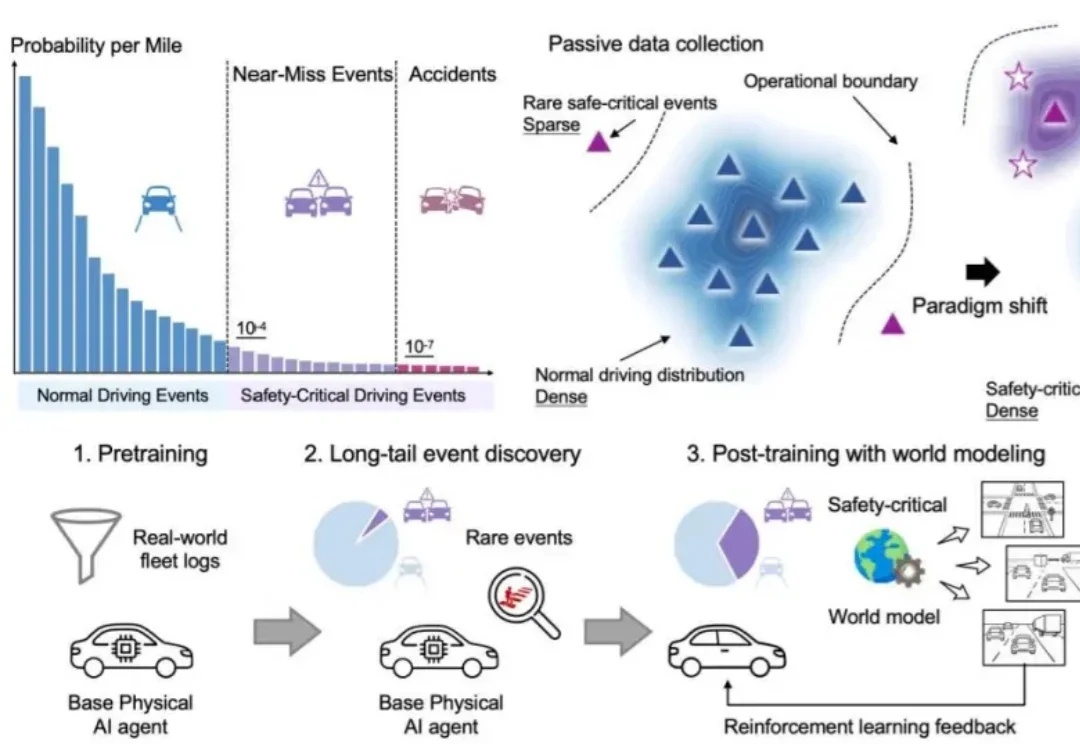
一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。

今日,据外媒The Information报道,DeepSeek正首次寻求外部融资,目标估值超过100亿美元(约合人民币681.8亿元)。据多位知情人士透露,DeepSeek已开始与投资人接触,计划融资至少3亿美元(约合人民币20.5亿元),以补充资金储备,应对AI大模型研发日益高昂的成本竞争。
上周 Anthropic 发布 Mythos Preview 的时候,安全圈的反应可以用一个词概括:震惊。
刚刚,图灵联合创始人刘江在海外社交媒体X上透露,DeepSeek核心研究院——郭达雅已加入字节跳动。 郭达雅2023年博士毕业后加入DeepSeek,title是AI Researcher。公开论文显示,从 DeepSeek-Coder、DeepSeek-Math、DeepSeek-Prover、DeepSeek-V3到 DeepSeek-R1,他都出现在核心作者名单中。
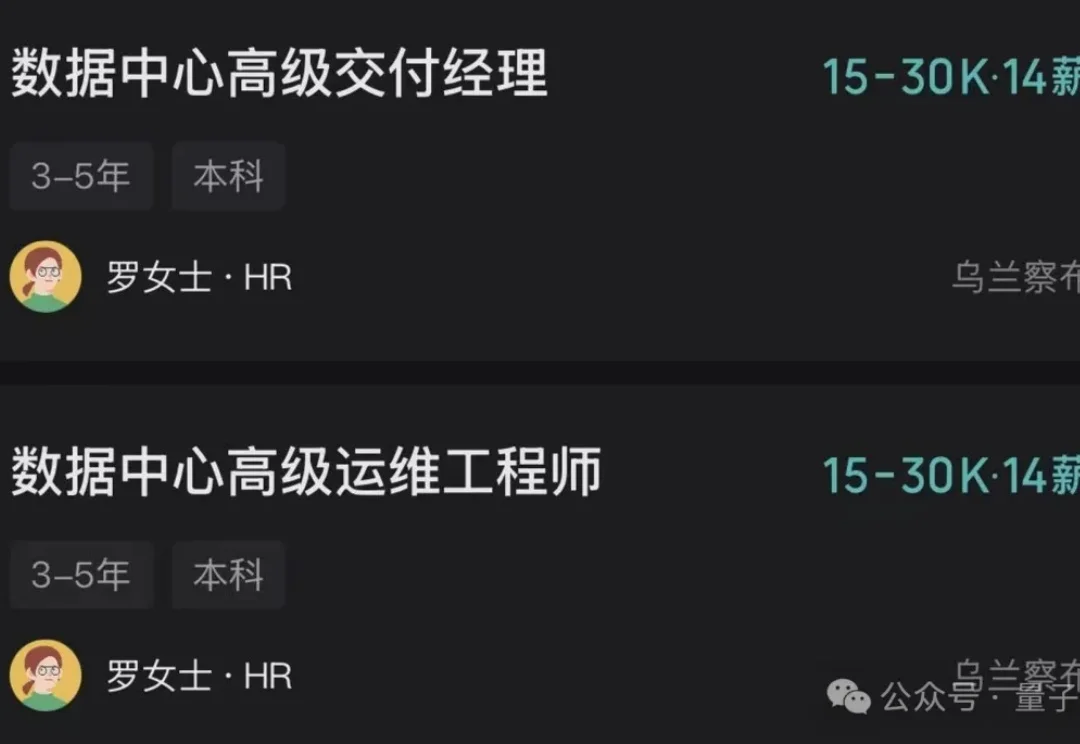
月薪30K,去草原给DeepSeek运维机房。

我每次翻《天龙八部》,翻到少林寺藏经阁那一段,都要停下来。
不更是不更,一更就是个大动作,DeepSeek V4可能真的要来了!

就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意—— 提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。