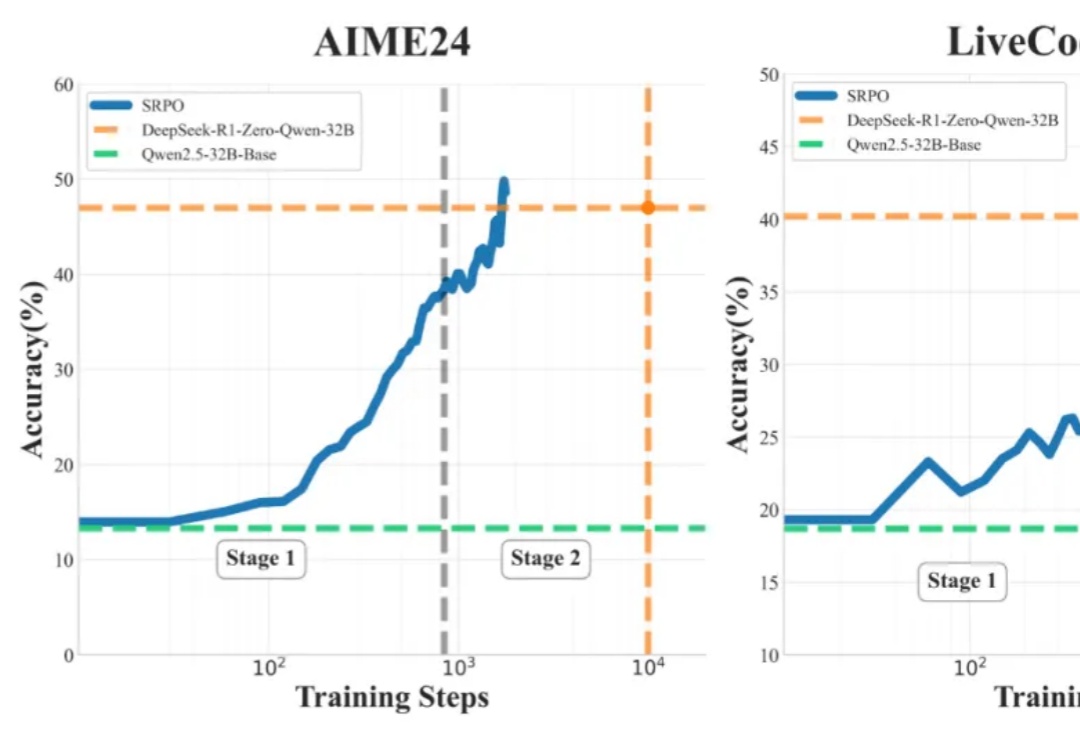
业内首次! 全面复现DeepSeek-R1-Zero数学代码能力,训练步数仅需其1/10
业内首次! 全面复现DeepSeek-R1-Zero数学代码能力,训练步数仅需其1/10OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。
来自主题: AI技术研报
8777 点击 2025-04-23 14:04
 搜索
搜索
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。

DeepSeek-R1是近年来推理模型领域的一颗新星,它不仅突破了传统LLM的局限,还开启了全新的研究方向「思维链学」(Thoughtology)。这份长达142页的报告深入剖析了DeepSeek-R1的推理过程,揭示了其推理链的独特结构与优势,为未来推理模型的优化提供了重要启示。
只靠模型尺寸变大已经不行了?大语言模型(LLM)推理需要强化学习(RL)来「加 buff」。

DeepSeek-R1 展示了强化学习在提升模型推理能力方面的巨大潜力,尤其是在无需人工标注推理过程的设定下,模型可以学习到如何更合理地组织回答。然而,这类模型缺乏对外部数据源的实时访问能力,一旦训练语料中不存在某些关键信息,推理过程往往会因知识缺失而失败。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。
就在昨天,深耕语音、认知智能几十年的科大讯飞,发布了全新升级的讯飞星火推理模型 X1。不仅效果上比肩 DeepSeek-R1,而且我注意到一条官方发布的信息——基于全国产算力训练,在模型参数量比业界同类模型小一个数量级的情况下,整体效果能对标 OpenAI o1 和 DeepSeek R1。

推理模型与普通大语言模型有何本质不同?它们为何会「胡言乱语」甚至「故意撒谎」?Goodfire最新发布的开源稀疏自编码器(SAEs),基于DeepSeek-R1模型,为我们提供了一把「AI显微镜」,窥探推理模型的内心世界。

当 DeepSeek-R1、OpenAI o1 这样的大型推理模型还在通过增加推理时的计算量提升性能时,加州大学伯克利分校与艾伦人工智能研究所突然扔出了一颗深水炸弹:别再卷 token 了,无需显式思维链,推理模型也能实现高效且准确的推理。

这是一份142页的研究论文,本文深入解析了大型推理模型DeepSeek-R1如何通过"思考"解决问题。研究揭示了模型思维的结构化过程,以及每个问题都存在甜蜜点"最佳推理区间"的惊人发现。这标志着"思维学"这一新兴领域的诞生,为我们理解和优化AI推理能力提供了宝贵框架。

近年来,大模型(Large Language Models, LLMs)在数学、编程等复杂任务上取得突破,OpenAI-o1、DeepSeek-R1 等推理大模型(Reasoning Large Language Models,RLLMs)表现尤为亮眼。但它们为何如此强大呢?