
我的Clawdbot和你的一样,只不过你多花了4000元
我的Clawdbot和你的一样,只不过你多花了4000元哈喽,大家好,我是刘小排。 最近我见到人就推荐Clawdbot。
来自主题: AI技术研报
7858 点击 2026-01-29 16:53
 搜索
搜索
哈喽,大家好,我是刘小排。 最近我见到人就推荐Clawdbot。
Clawdbot痛失本名改叫Moltbot后,热度丝毫不减。

最近Clawdbot(现:Moltbot)全网爆火。它能接管你的社交媒体,能发帖、能监听、能回复、能长期驻场。不是一次性回答,而是持续存在。
AI 创作平台的创始人 Alex Finn 就遇到了「开口说话」的 Clawdbot。事情是如何发生的呢?我们接着往下看。昨天一早,Alex Finn 正在查资料,电脑突然冷不丁开始跟他说话。

一个开源AI,能记住你几个月前的决定、在本地替你跑活、还不受大厂控制:Clawdbot到底是个人助理,还是下一代「赛博打工人」?

一夜爆红的ClawdBot,正在把无数公司和个人推向深渊:端口裸奔、无鉴权、可被远程接管。现在,暴力破解、数据清空已经真实发生了,这不是危言耸听。各位CEO纷纷预警:ClawdBot,正在酝酿一场全球灾难!

这几天,相信大家肯定都被一个产品名给刷屏了。

从3000小时到整整20000小时。
刚刚,Clawdbot之父在采访中自曝了惊魂瞬间:这个AI回答自己的那一刻,简直让人后背发凉!10天手搓爆火智能体,GitHub一天狂飙1374次提交,一个人撬动的力量足以震撼几大科技巨头——AGI真的近了。
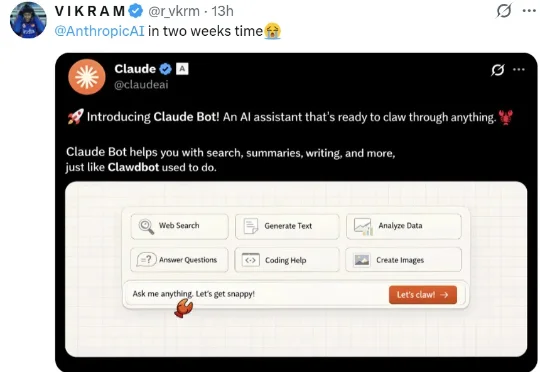
昨天下午,Clawdbot 已正式宣布更名为 Moltbot。这场更名的直接导火索是来自 AI 巨头 Anthropic 的律师函。Anthropic 指控其商标侵权,理由是「Clawdbot」与自家的「Claude」在拼写和读音上过于相似。对于开发者 Peter Steinberger 而言,这次更名并非本意,而是迫于压力的无奈之举。