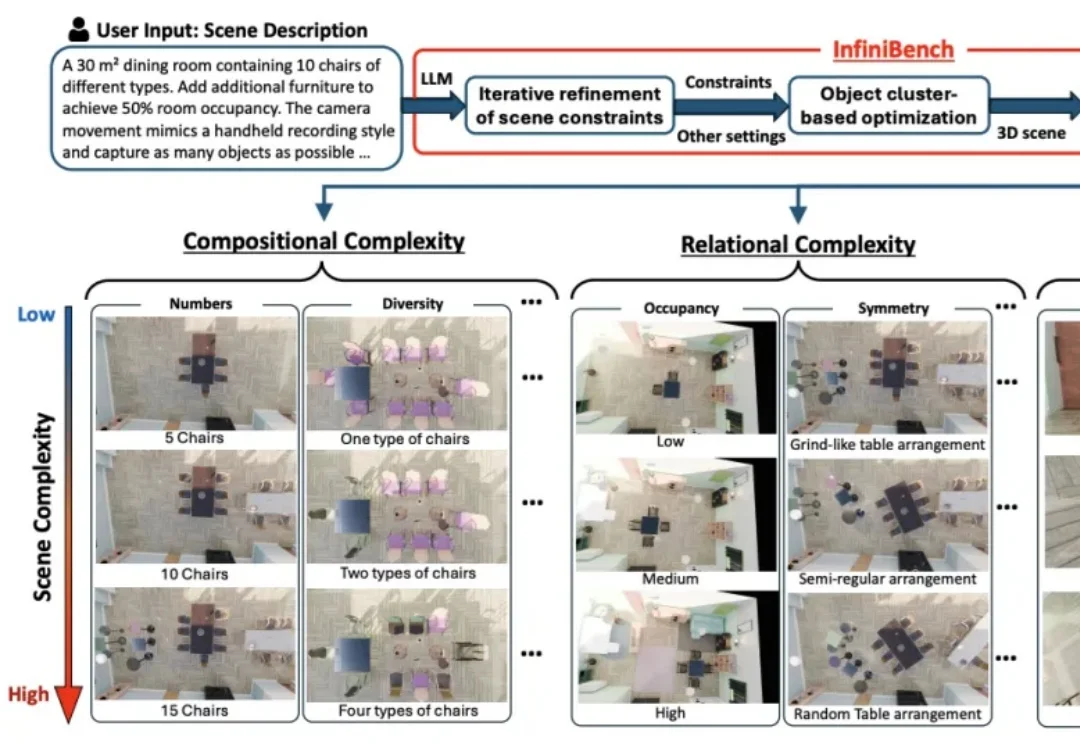
一句话生成无限逼真3D场景!匹兹堡大学新作直击VLM空间推理软肋丨CVPR'26
一句话生成无限逼真3D场景!匹兹堡大学新作直击VLM空间推理软肋丨CVPR'26VLM看图像描述头头是道,一遇到3D空间推理就“晕菜”。
来自主题: AI技术研报
6793 点击 2026-04-08 09:15
 搜索
搜索
VLM看图像描述头头是道,一遇到3D空间推理就“晕菜”。

EigenLayer 创始人 Sreeram Kannan 在纽约 Digital Asset Summit 上扔出一个论点:智能体会变成公司。不是帮公司干活,不是给公司做助手——是直接变成公司本身。

今天,Anthropic又出了一条引爆AI圈的新闻:年化收入已经超过了OpenAI,达到了300亿美元!
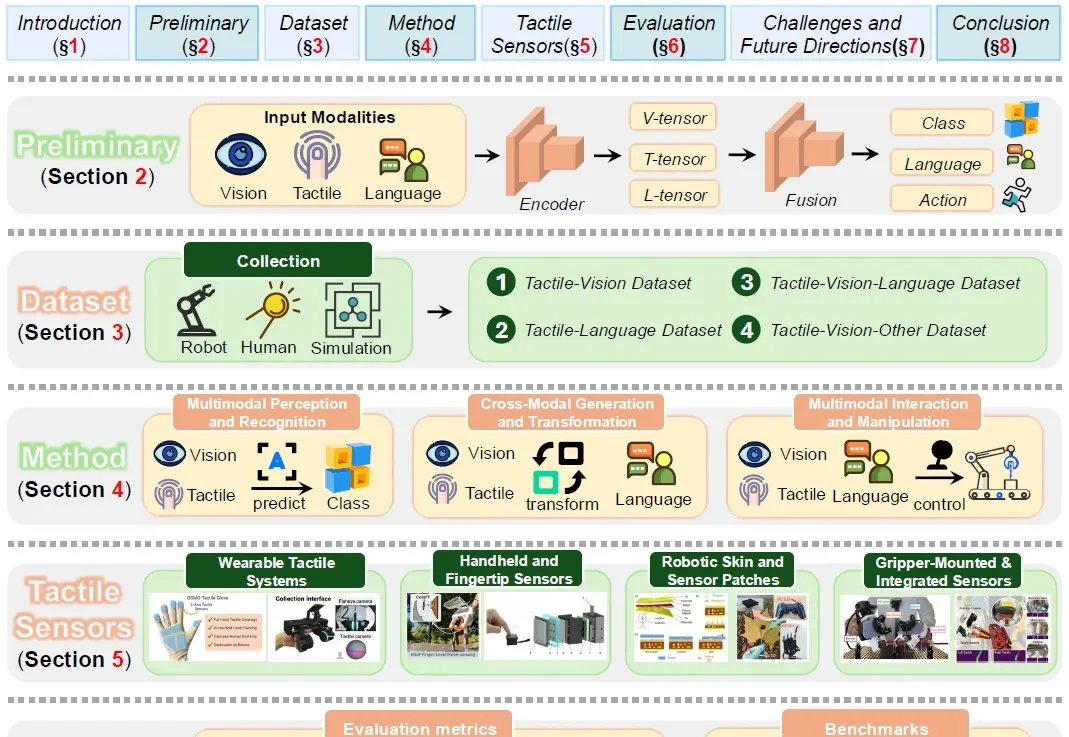
在具身智能的感知拼图中,触觉一直扮演着不可或缺却难以被完美量化的角色。它提供了视觉等远程传感器无法替代的关于接触几何、材料特性和交互动态的直接反馈。

中关村科学城国际创新服务集聚区的会议室,座无虚席。

Anthropic杀疯了!开年第一篇论文直接化身自爆卡车,实锤AI正在让程序员变傻。你以为效率提高了?其实只快了2分钟。

SLAM 在自动驾驶、机器人、AR/VR 乃至具身智能系统中都是至关重要的环节,它决定了算法能否在一个陌生环境中一边“看懂世界”,一边“知道自己在哪”。

上个月,Anthropic 最强模型 Claude Mythos 意外被曝光。 被泄露的内部文档里面写着,它比 Anthropic 的 Opus 模型更大、更智能,是迄今为止开发过的最强大的 AI 模

从OpenClaw刷屏开始,人人都能拥有专属的AI“个人助理”仿佛不再是科幻电影里的未来。在这场通往新世界的拥挤赛跑中,一家聚焦海外市场的初创公司Boxy刚刚获得红杉中国种子基金投资的数百万元美元融资。
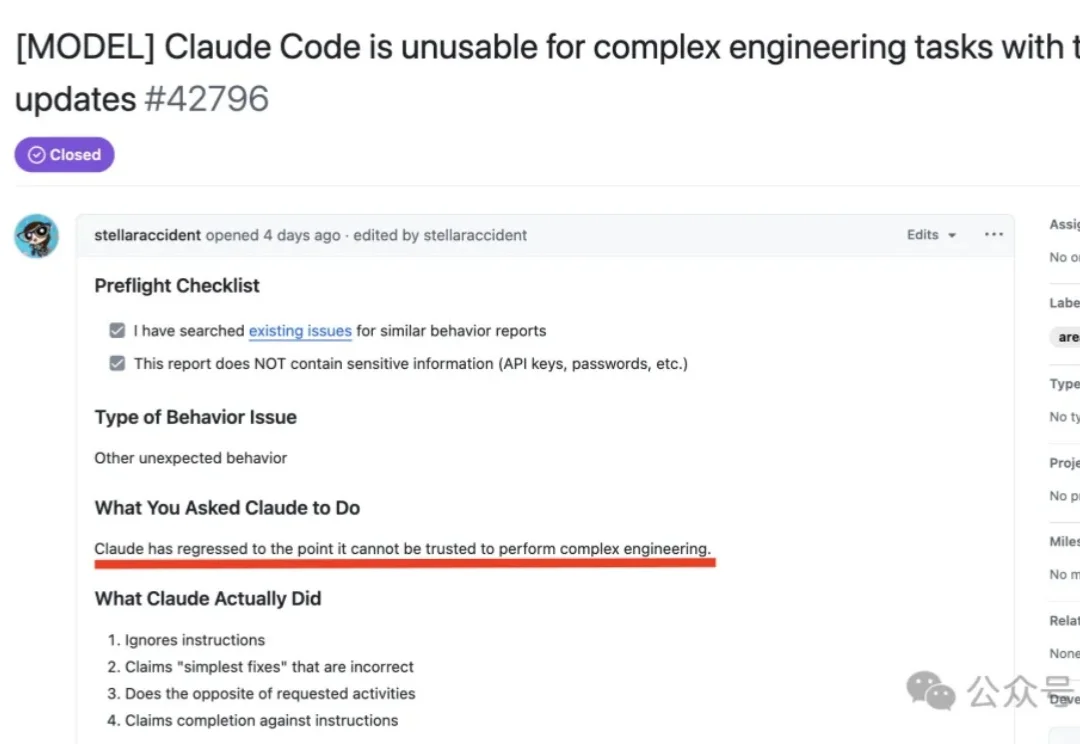
在官方仓库贴脸开大,热议Issue指出:Claude Code已经更新“废了”。某次更新让思考深度下降67%,当前版本已无法胜任复杂工程任务。“无视用户指令”“执行与用户要求完全相反的操作”“假装说任务已完成”……模型行为全面走样。