
刚刚,Fable 5全球解禁!
刚刚,Fable 5全球解禁!18天后,AI圈终于迎来了一场狂欢!今天,Anthropic官宣:美国商务部正式撤销对Anthropic旗下神级模型Fable 5(以及Mythos 5)的出口管制,明天恢复访问。
来自主题: AI资讯
9937 点击 2026-07-01 10:46
 搜索
搜索
18天后,AI圈终于迎来了一场狂欢!今天,Anthropic官宣:美国商务部正式撤销对Anthropic旗下神级模型Fable 5(以及Mythos 5)的出口管制,明天恢复访问。
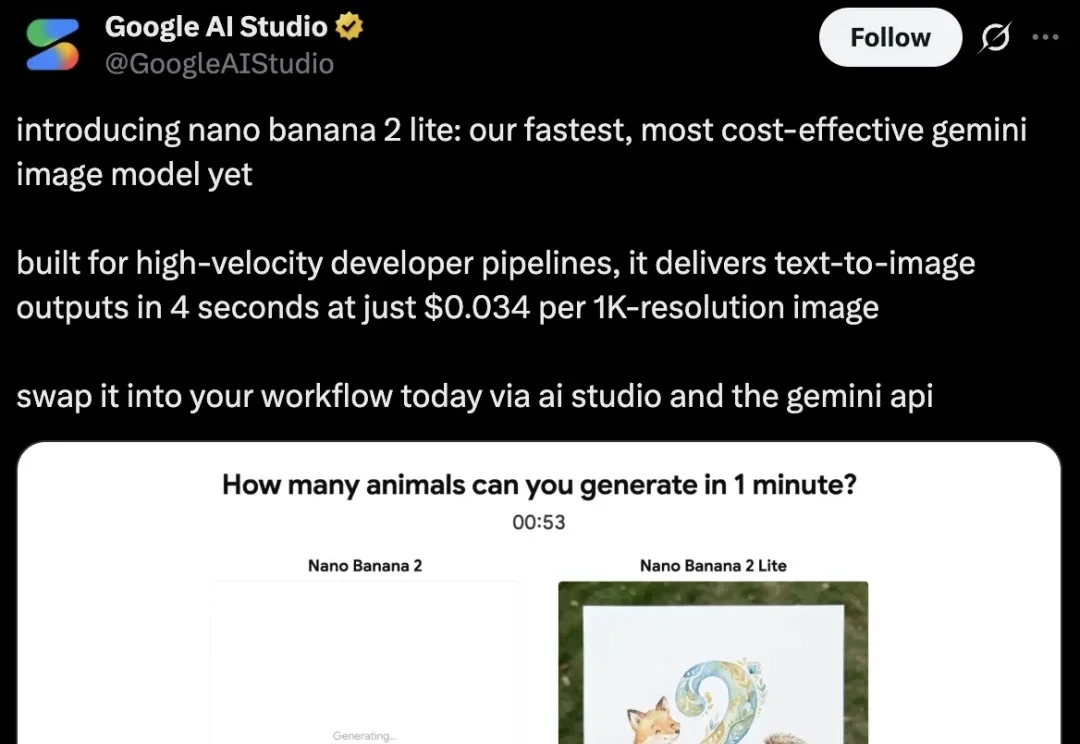
虽然Coding还是一坨,但谷歌搞「多模态」确实有两把刷子。

全尺寸、超仿生、成年人限定。
这两天,Claude大面积封号。

今天要分享的公司是:Sengine,生境科技,之前我也分享过一家国内做 3D 的 AI 公司,但 Sengine 和 VAST 完全不是一个产品路径,后面会分析。2026 年,Forbes 30 Under 30 Asia 的 AI 榜单里,有一家来自深圳的公司:Sengine Technology,生境科技。

2026年,具身智能赛道的融资热度仍在持续,但投资人的提问方式已经变了。

三位哈佛辍学生创办。

微信和企业微信的 Agent,同时出牌。

物理AI发展到现在,所有玩家都奔着同一个方向使劲: 让机器人「读懂」所处的物理环境。
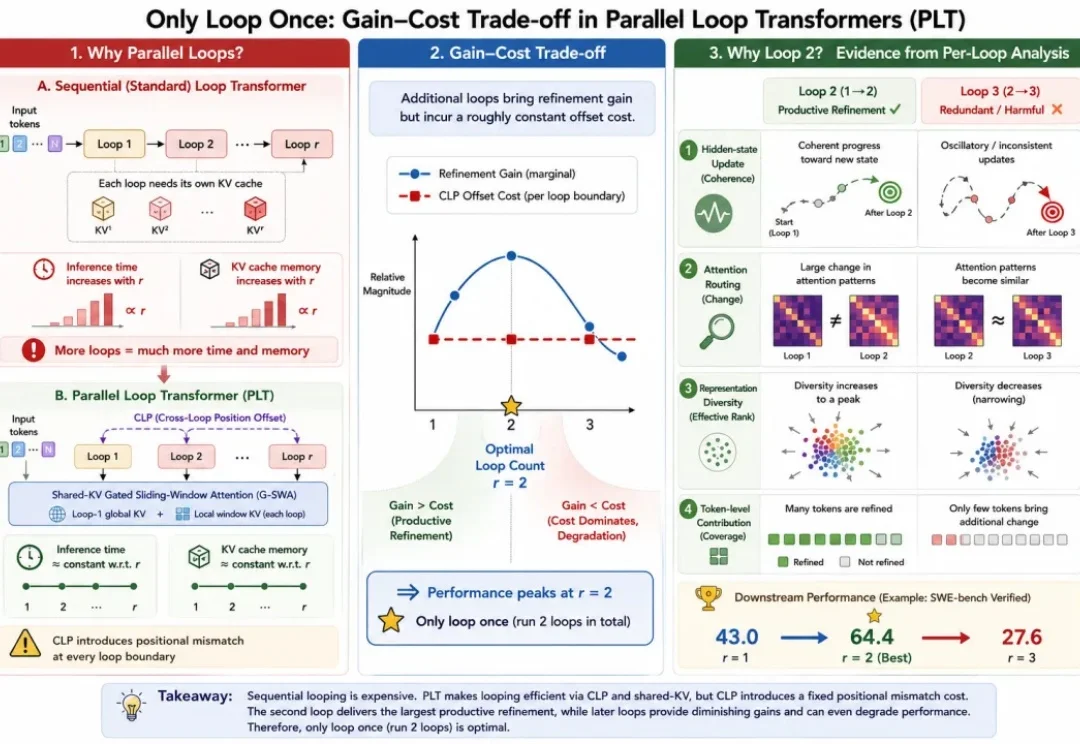
当所有人都在比谁「想得更久、算得更多」——推理模型动辄输出成千上万个思考 token,循环式架构恨不得在内部反复迭代十遍八遍——一项新研究反手泼了盆冷水: