轻量高效,即插即用:Video-RAG为长视频理解带来新范式
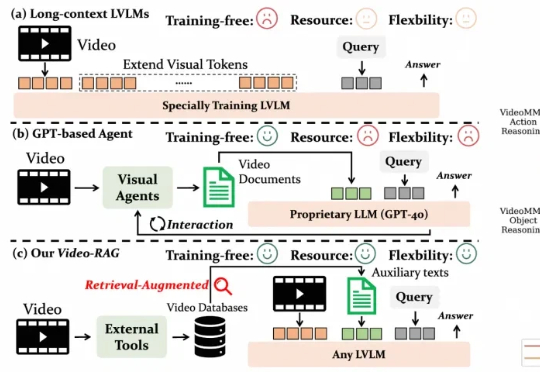
轻量高效,即插即用:Video-RAG为长视频理解带来新范式尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。
来自主题: AI技术研报
8161 点击 2025-10-22 14:57