
突破短视频局限!MMBench 团队构建中长视频开放问答评测基准,全面评估多模态大模型视频理解能力
突破短视频局限!MMBench 团队构建中长视频开放问答评测基准,全面评估多模态大模型视频理解能力GPT-4o 四月发布会掀起了视频理解的热潮,而开源领军者Qwen2也对视频毫不手软,在各个视频评测基准上狠狠秀了一把肌肉。
来自主题: AI技术研报
4995 点击 2024-10-30 13:59
 搜索
搜索
GPT-4o 四月发布会掀起了视频理解的热潮,而开源领军者Qwen2也对视频毫不手软,在各个视频评测基准上狠狠秀了一把肌肉。

长视频理解迎来新纪元!智源联手国内多所顶尖高校,推出了超长视频理解大模型Video-XL。仅用一张80G显卡处理小时级视频,未来AI看懂电影再也不是难事。

仅需1块80G显卡,大模型理解小时级超长视频。 智源研究院联合上海交通大学、中国人民大学、北京大学和北京邮电大学等多所高校带来最新成果超长视频理解大模型Video-XL。

开源数字人实时对话Demo来了~

视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。

现在正是「文本生视频」赛道百花齐放的时代,而且其应用场景非常多,比如生成创意视频内容、创建游戏场景、制作动画和电影。

现在,人人皆导演,正在成为现实!

这是由潞晨 Video Ocean 生成的黑白电影片段,全新升级的模型现已正式上线,任意角色任意风格,并带来三大突破性功能 —— 文生视频、图生视频、角色生视频,解锁创意的无限可能。
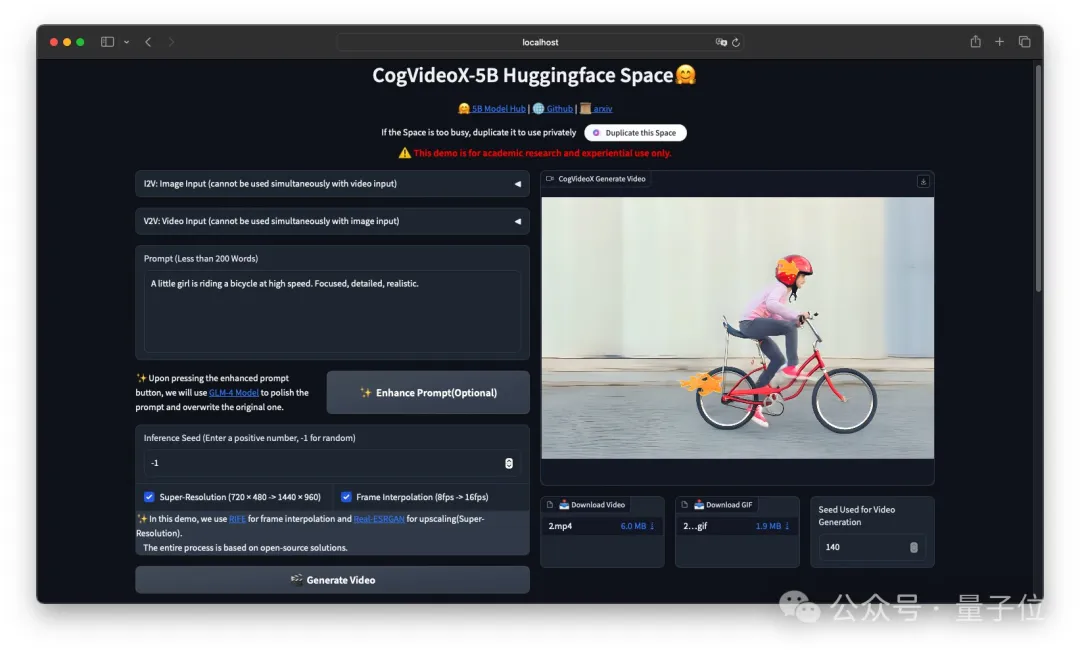
刚刚,智谱把清影背后的图生视频模型CogVideoX-5B-I2V给开源了!(在线可玩) 一起开源的还有它的标注模型cogvlm2-llama3-caption。

前几天 MiniMax 发布了海螺视频生成模型 abab-video-1,现场体验非常炸裂。很多朋友跑来问我,这个海螺视频模型和可灵的区别主要是什么?于是我做了一个短片,来从六个维度展现这两个视频模型的不同之处。一句话总结海螺视频就是:美学升级,运镜加分,表情丰富,文字突出。