
终于等到开源好用的修图大模型了!阶跃模型三连发,卷疯了多模态赛道
终于等到开源好用的修图大模型了!阶跃模型三连发,卷疯了多模态赛道最近在看 Agent 方向的论文和产品,已经被各种进展看花了眼。但我发现,真正能超越 demo,能在 B 端场景扎实落地的却寥寥无几。
来自主题: AI技术研报
10045 点击 2025-04-28 16:40
 搜索
搜索
最近在看 Agent 方向的论文和产品,已经被各种进展看花了眼。但我发现,真正能超越 demo,能在 B 端场景扎实落地的却寥寥无几。

港中文和清华团队推出Video-R1模型,首次将强化学习的R1范式应用于视频推理领域。通过升级的T-GRPO算法和混合图像视频数据集,Video-R1在视频空间推理测试中超越了GPT-4o,展现了强大的推理能力,并且全部代码和数据集均已开源。

虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。这个过程既耗时又耗计算资源。例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。

随着 VR/AR、游戏娱乐、自动驾驶等领域对 3D 场景生成的需求不断攀升,从稀疏视角重建 3D 场景已成为一大热点课题。

又一家新晋AI独角兽出现了。
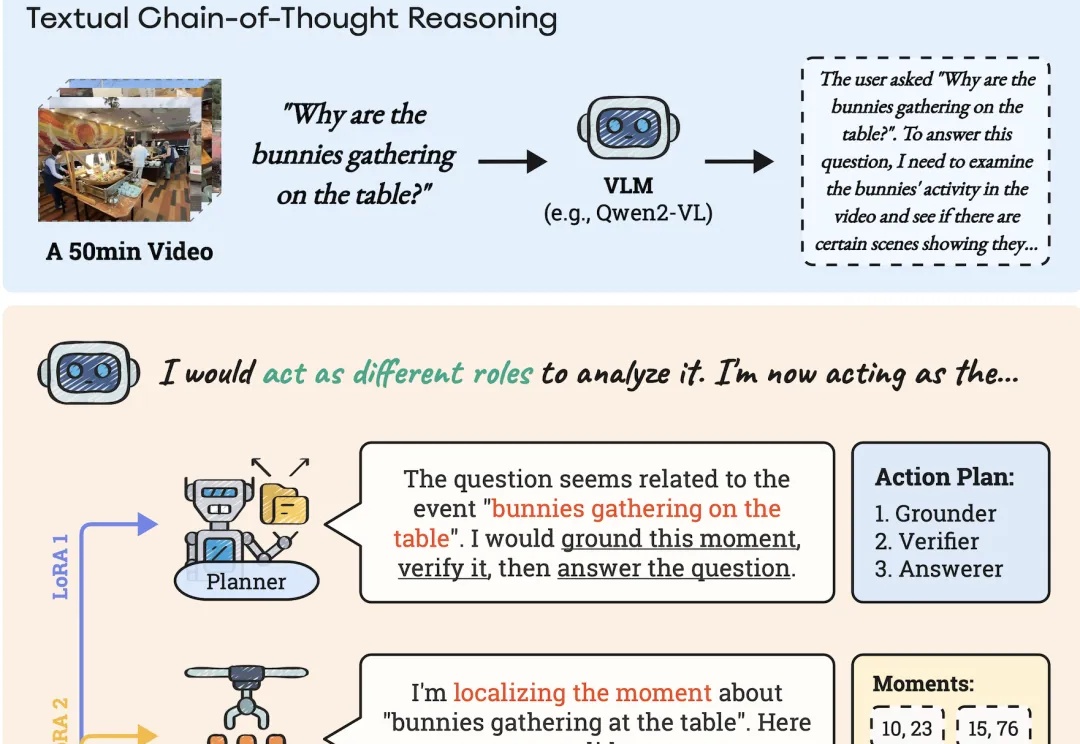
AI能像人类一样理解长视频。

AI 医疗公司 OpenEvidence 在 2 月份获得红杉资本新一轮的 7500 万美元融资,估值超过 10 亿美元,成为了新的 AI 独角兽。
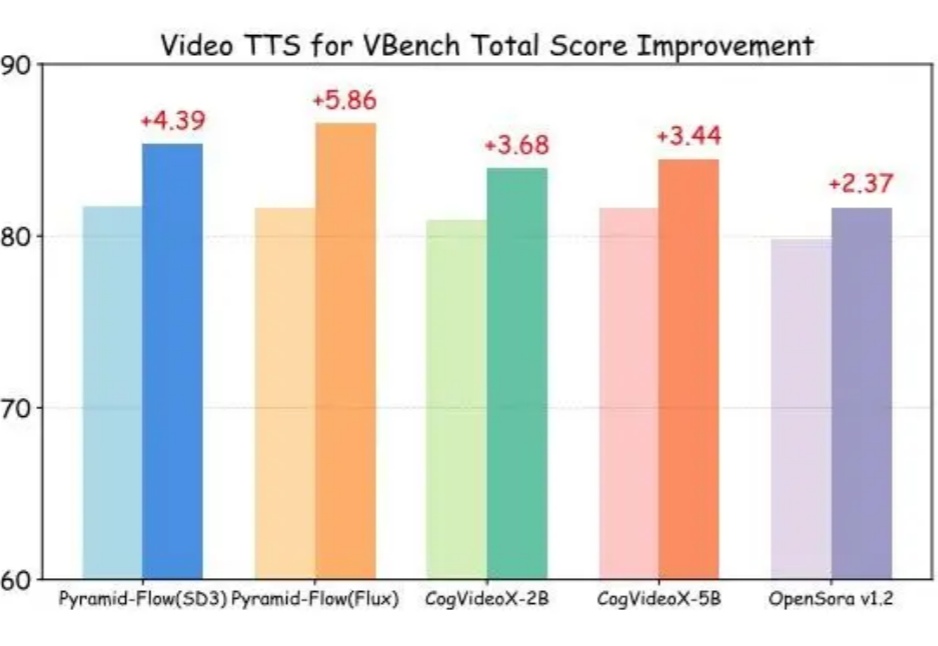
视频作为包含大量时空信息和语义的媒介,对于 AI 理解、模拟现实世界至关重要。视频生成作为生成式 AI 的一个重要方向,其性能目前主要通过增大基础模型的参数量和预训练数据实现提升,更大的模型是更好表现的基础,但同时也意味着更苛刻的计算资源需求。

如何让你的模型能感知到视频的粒度,随着你的心思想编辑哪就编辑哪呢?

如何用一小时完成3D游戏开发?「vibe coding」(氛围编程)让3D游戏制作变得轻松。无需编写代码,借助AI工具就能打造游戏,甚至还能盈利!从骑马大战飞龙的奇幻冒险,到水上摩托艇的惊险竞速,再到多人海盗船的探索之旅,Vide Coding的热潮正在席卷网络。