ICML25 | 让耳朵「看见」方向!仅依靠360°全景视频,就能生成3D空间音频
ICML25 | 让耳朵「看见」方向!仅依靠360°全景视频,就能生成3D空间音频空间音频,作为一种能够模拟真实听觉环境的技术,正逐渐成为提升沉浸式体验的关键。
来自主题: AI技术研报
10444 点击 2025-05-15 10:56
 搜索
搜索
空间音频,作为一种能够模拟真实听觉环境的技术,正逐渐成为提升沉浸式体验的关键。

六边形战士来了。
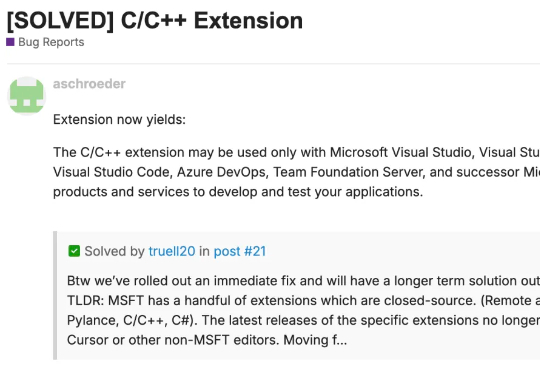
微软某个 VSCode 语言服务扩展中,位于 nativeStrings.json 文件第 485 行的一行代码,打破了它与 Cursor 的兼容性。该条款规定:“C/C++ 扩展仅可与 Microsoft Visual Studio、Visual Studio for Mac、Visual Studio Code、Azure DevOps、Team Foundation Server
Google 终于下场了。搞了一个完全平替 V0、Bolt.new、Lovable 的产品 Firebase Studio。用自然语言一键生成网站或者App,后续还能集成 firebase 的各种服务,构建全栈应用。
之前靠AI作弊神器横扫大厂offer的小哥,最近有新后续了:创业成功,月入22.85万美元,走上人生巅峰。与此同时,大厂的面试官们可是被折腾惨了,直言技术面试已被摧毁!

科技圈再掀波澜,一家名为Graphite的纽约人工智能初创公司,正式名称为Screenplay Studios Inc.,今日宣布成功斩获高达5200万美元的B轮融资,为这家专注于颠覆传统代码审查模式的新星注入了强劲动力。
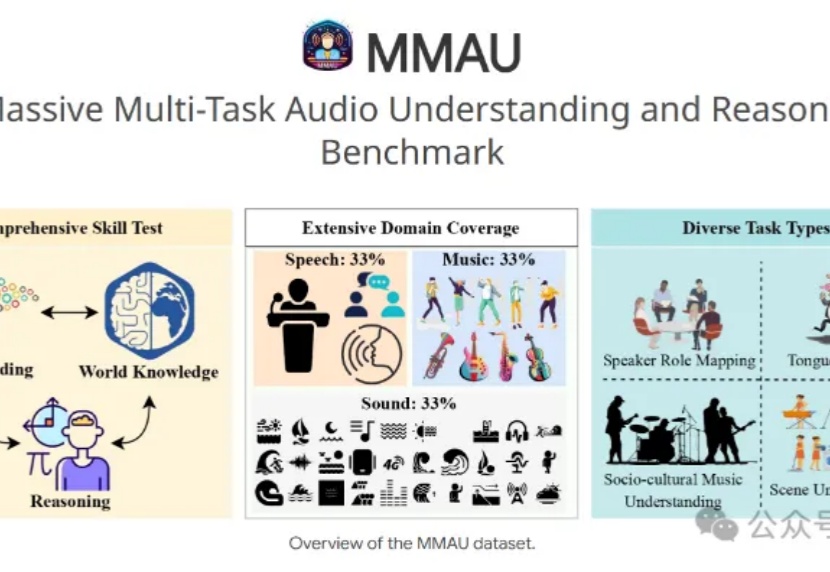
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?

StyleStudio能解决风格迁移中风格过拟合、文本对齐差和图像不稳定的问题,通过跨模态AdaIN技术融合文本和风格特征、用教师模型稳定布局、引入基于风格的无分类器引导,实现精准控制风格元素,提升生成图像的质量和稳定性,无需额外训练,使用门槛更低!

挤牙膏的新款 iPad Air 和 iPad 果然只是开胃小菜,今天苹果为我们带来了更有看点的 MacBook Air 和 Mac Studio 更新。

当传统音乐制作仍被繁复的乐理知识与高昂的录音成本筑起高墙,一群理想主义者正用AI重新书写规则。从乐队主唱到AI音乐创业者,郭靖(Joe)的十年探索,恰是音乐行业从“精英创作”向“全民表达”演进的时代缩影——他曾因工具掣肘埋没作品,却在自学编程的硅谷岁月里顿悟:技术不该是艺术的门槛,而应是创作者的翅膀。