
1个Token测出模型降级调包!成本砍到千分之一,API供应商的小伎俩全曝光了
1个Token测出模型降级调包!成本砍到千分之一,API供应商的小伎俩全曝光了版本号没变,API供应商却悄悄偷换模型?现在这种小伎俩可以轻松被戳穿了。
来自主题: AI资讯
9304 点击 2026-03-23 14:13
 搜索
搜索
版本号没变,API供应商却悄悄偷换模型?现在这种小伎俩可以轻松被戳穿了。
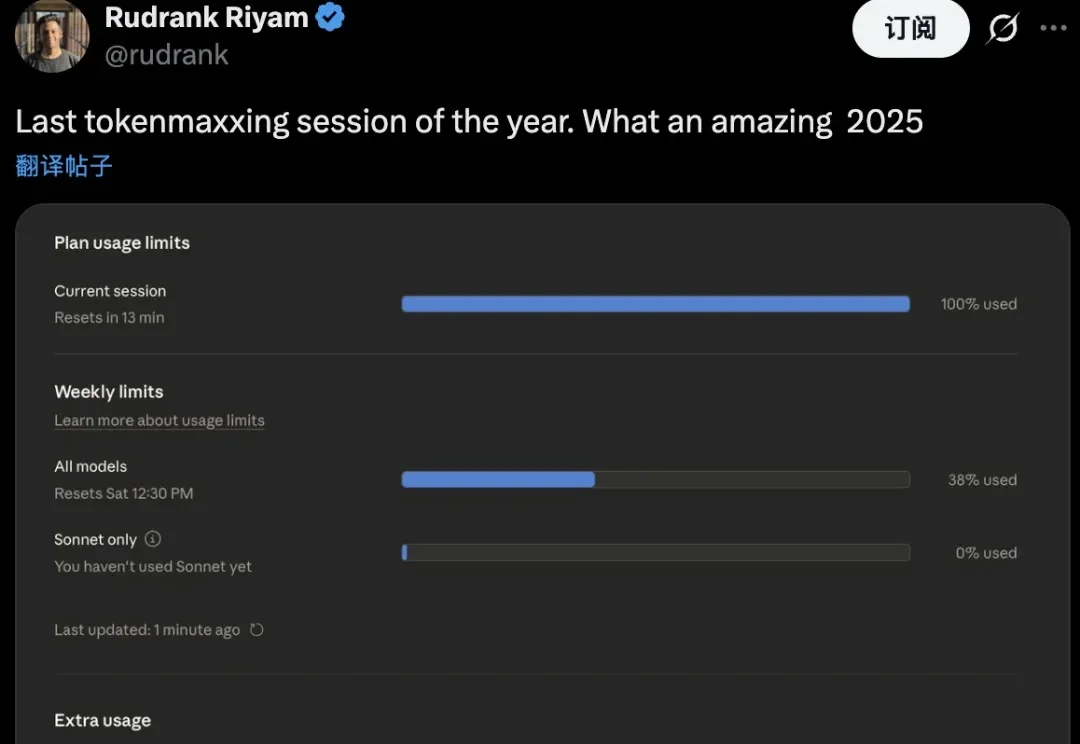
OpenAI最烧Token的人有多狠?

我最近感到最难受的事情是,若干人炒作自己一天能花几十亿token,几天拿AI写出几十万行代码。

近日,由光合组织发起的全国线下OpenClaw体验活动“龙虾局”正在各地掀起热潮。从成都到昆山到天津再到杭州,上千名开发者与AI技术爱好者携带电脑到场,享受免费安装服务并领取免费Token算力资源。
Karpathy自曝:我得AI精神病了!这些天,他已经处于精神错乱边缘,16小时不吃不睡就是搞Agent,而且很焦虑自己有没有把智元(token)用到极限,根本停不下来……

我们十分认可:将 Token 翻译成「智元」。这个译名比「词元」更能反映如今 Token 的含义。
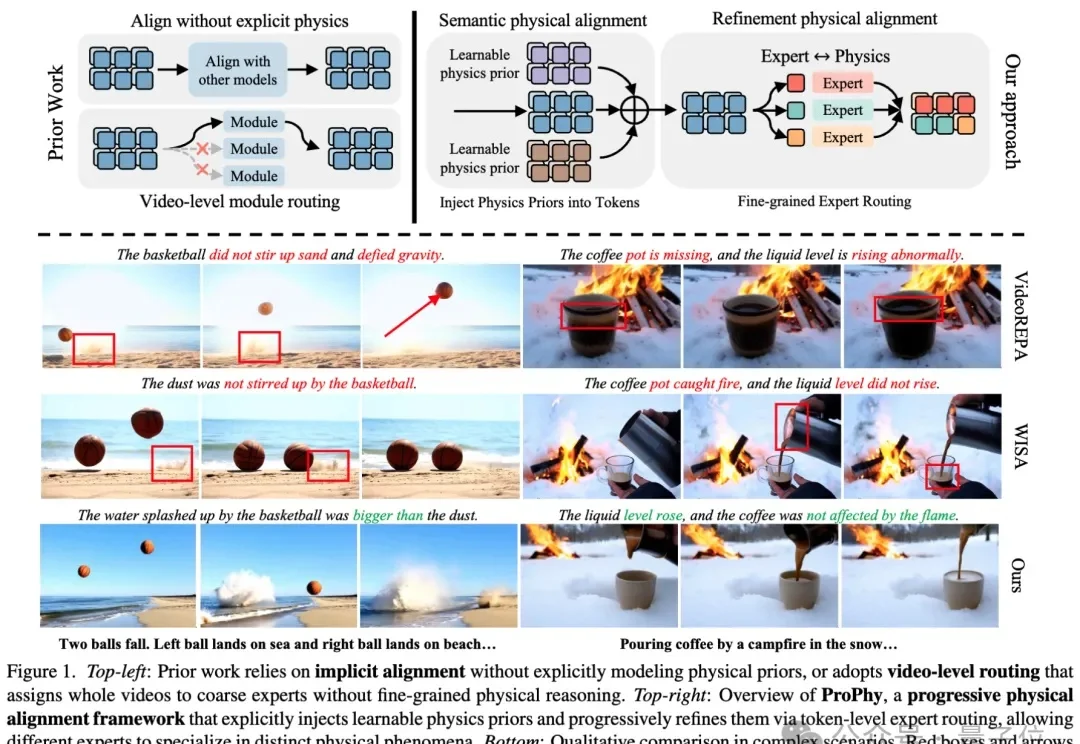
当人们谈到“世界模型”(World Models)时,很多人会首先想到近年来迅速发展的生成式视频模型。
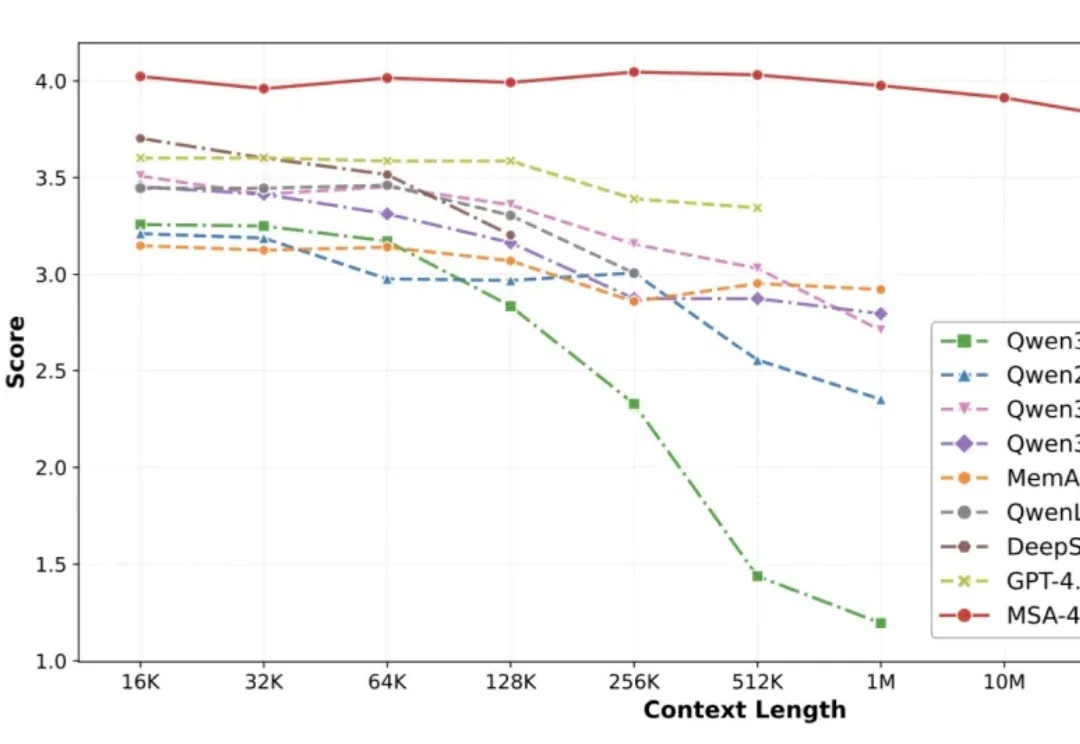
人的智能能力主要由推理能力和长期记忆能力构成。近年来,大模型的推理能力一直处于快速发展过程,但大模型的长期记忆能力一直受限于上下文长度,无法取得突破。在历史上,曾经有多种路线进行尝试,但都无法突破扩展性(Scalability)、精度(Precision)和效率(Efficiency)的不可能三角。

MLRA通过拆分KV缓存为四个并行分支,显著降低显存占用并实现4路张量并行。推理速度比MLA最高快2.8倍,支持百万级上下文,且模型质量更优。无需牺牲性能,即可高效扩展长文本处理能力。
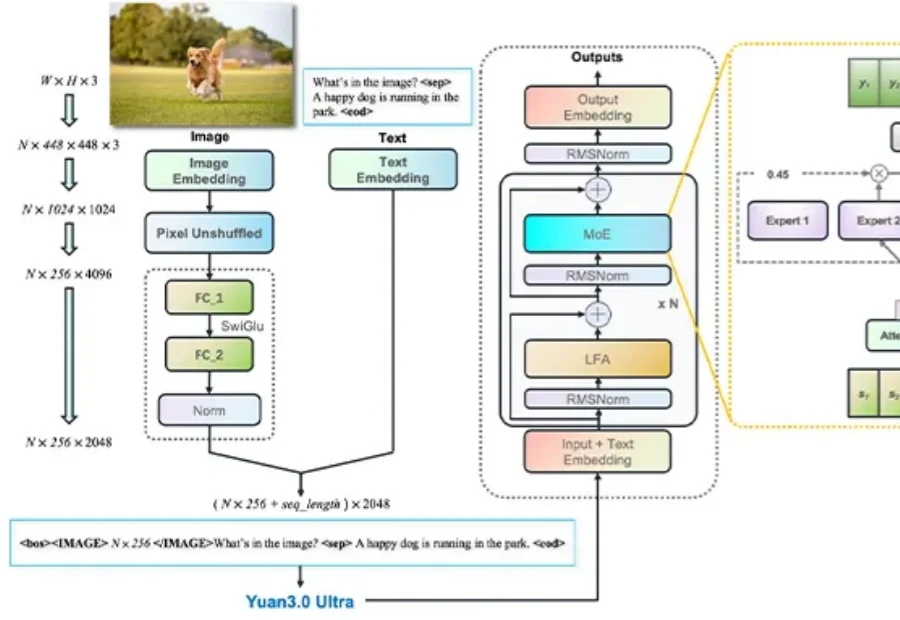
告别Token老虎,给大模型来了个“减脂增肌”。