
从卖token到卖结果,这些公司开始让AI背KPI了
从卖token到卖结果,这些公司开始让AI背KPI了自从黄仁勋在 GTC 上大手一挥,鼓励企业把 token 消耗量算进工程师的 KPI,魔幻的事情就一天比一天多了。
来自主题: AI资讯
8811 点击 2026-05-19 15:32
 搜索
搜索
自从黄仁勋在 GTC 上大手一挥,鼓励企业把 token 消耗量算进工程师的 KPI,魔幻的事情就一天比一天多了。
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。

大语言模型真的只能走“预测下一个token”的路子吗?

近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。
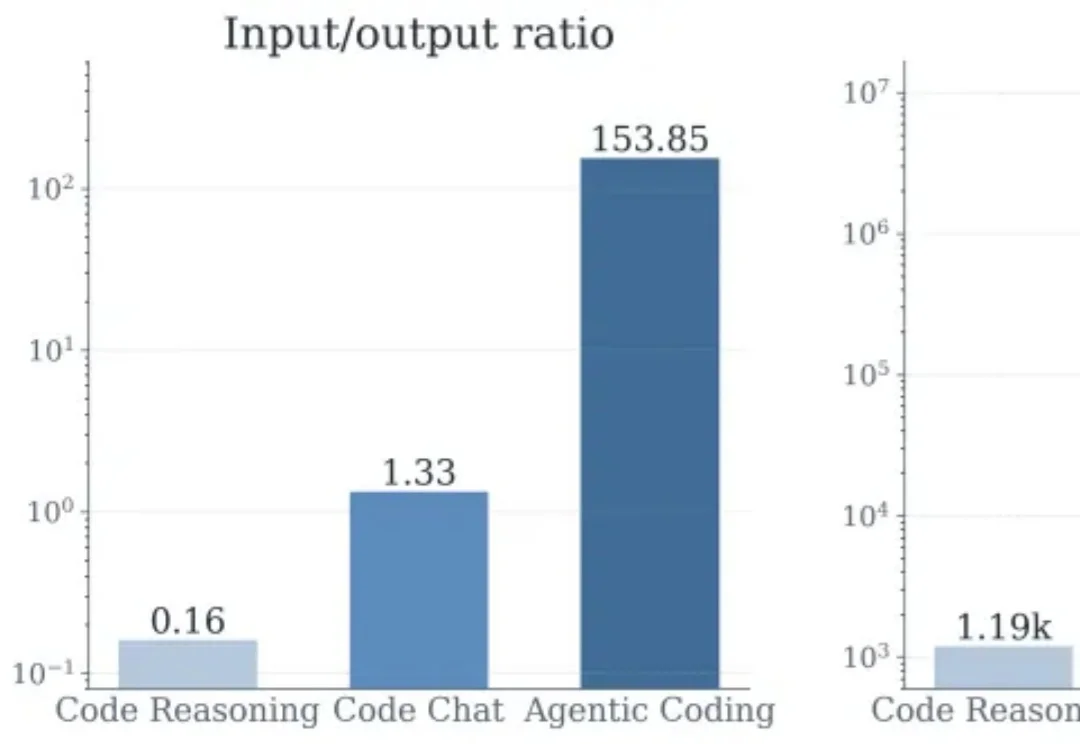
如今的 AI Agent 正在大规模落地,其中应用最广且最受关注的当数 Claude Code,Codex,Cursor 这类 coding agent。过去的一年里,这类 coding agent 产品迭代迅速,在一年内将在 swe-bench- verified 的准确率提高到了 78%+。

最近几天,中国电信、中国移动、中国联通接连推出Token套餐及相关AI服务,面向个人、家庭、开发者、中小微企业等用户销售大模型调用量。这是三大运营商首次正式入局Token生意,而此前相关业务由大模型厂商、互联网大厂和云服务商主导。

20美元Token费,2小时运行,AI智能体没问任何人,自主翻遍互联网,选中麦肯锡,把它的「数字大脑」Lilli彻底攻破。4650万条战略聊天记录、72万份核心文件、95条系统提示词……全部明文读写权限到手。AI震惊地说出了「WOW!」

新一轮 AI 比赛才刚刚开始,而 token 生成数量不能作为唯一的指标。

太有意思了,刚看到河南郑州西亚斯学院的消息。有几位 00 后创业者回母校干了件事,给学校捐了 20 亿 Token,希望带动学弟学妹做一人公司创业。郑州西亚斯学院是泡泡玛特老板王宁的母校,看来这学校真挺能出人才的。
每次想让AI读个外部网站的信息,看到这句话头都要炸了。不过,GitHub有个开源项目OpenCLI把这事儿解决了:网站变命令行。Reddit讨论、B站热门、Arxiv论文,以前开浏览器一个个翻的东西,现在终端一行命令直接出结构化数据。