
Anthropic史上最大训练曝光,Ilya错了?CEO哀嚎:创业公司将被毁灭
Anthropic史上最大训练曝光,Ilya错了?CEO哀嚎:创业公司将被毁灭三周前那个疯狂传言,如今被Mythos彻底印证?Anthropic或已完成史上最大规模训练,新模型性能或将达到预期的2倍,翻倍碾压Scaling Law!一场颠覆性变革正在降临,算力、能源成为终极筹码,创业公司恐遭毁灭性降维打击!
来自主题: AI资讯
9446 点击 2026-03-30 16:09
 搜索
搜索
三周前那个疯狂传言,如今被Mythos彻底印证?Anthropic或已完成史上最大规模训练,新模型性能或将达到预期的2倍,翻倍碾压Scaling Law!一场颠覆性变革正在降临,算力、能源成为终极筹码,创业公司恐遭毁灭性降维打击!

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大
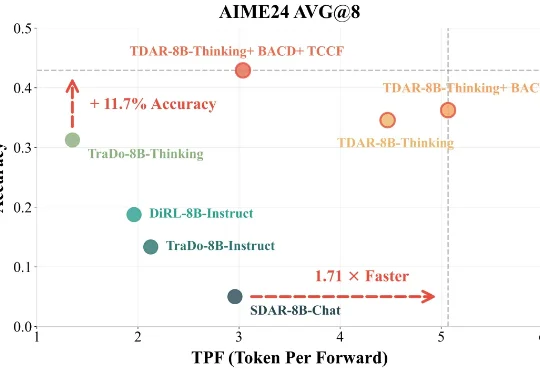
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码
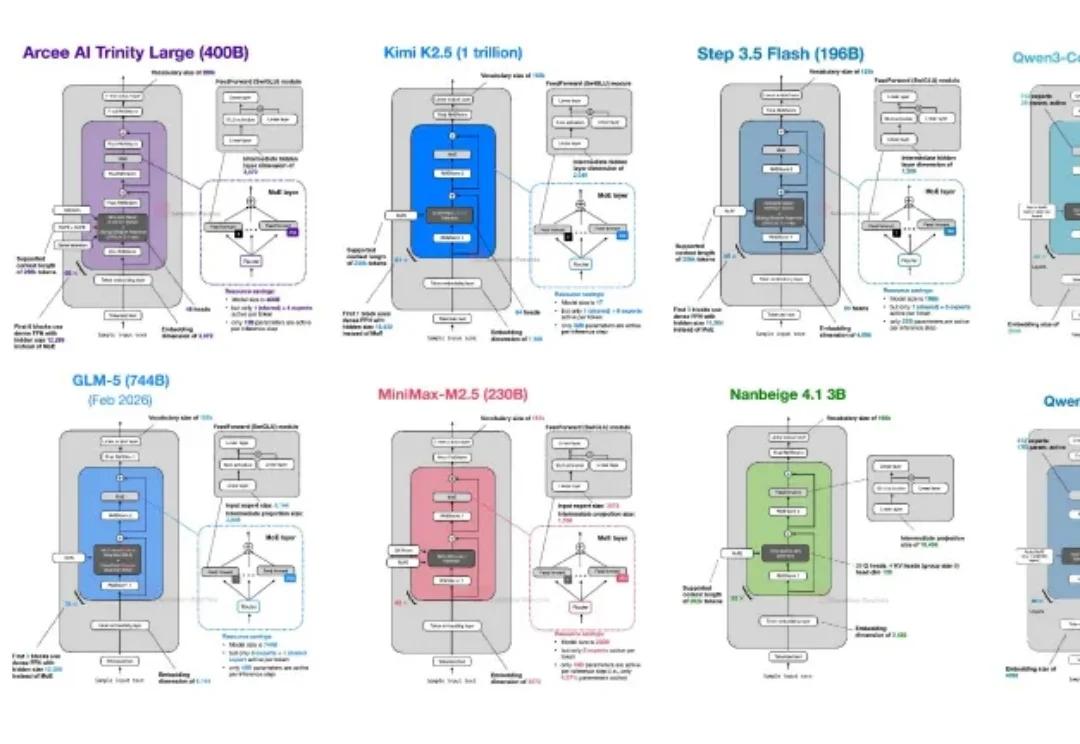
这两年,大模型大厂之间堪比军备竞赛。不论开源还是闭源阵营,为了在指标上领先对手,都在疯狂地卷 Scaling Law,卷算力,卷参数量,已经达到了近乎离谱的程度。
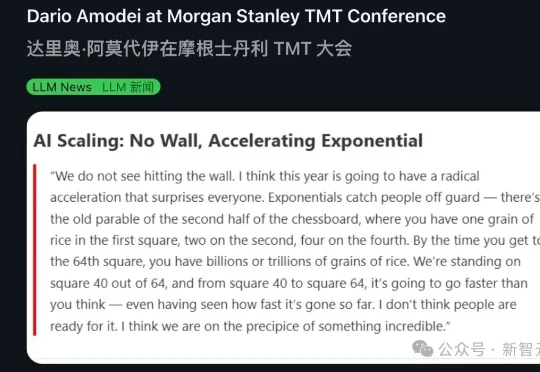
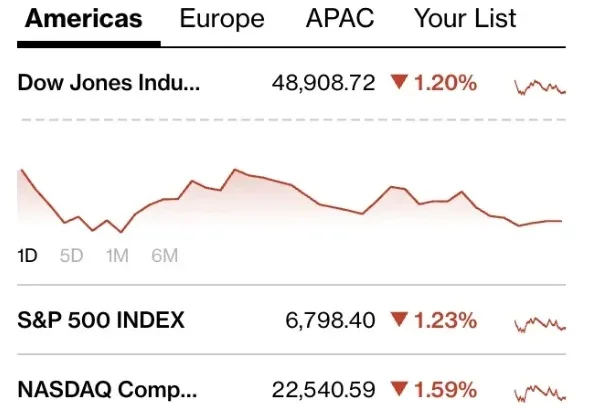
Anthropic CEO Dario Amodei在摩根士丹利会议上扔出一颗深水炸弹:Scaling Law根本没撞墙,2026年将迎来激进加速。他用棋盘稻米寓言做了个精准比喻——我们正站在第40格,前39格的所有震撼加在一起,不过是后24格的零头。这场指数级狂飙,没人准备好。
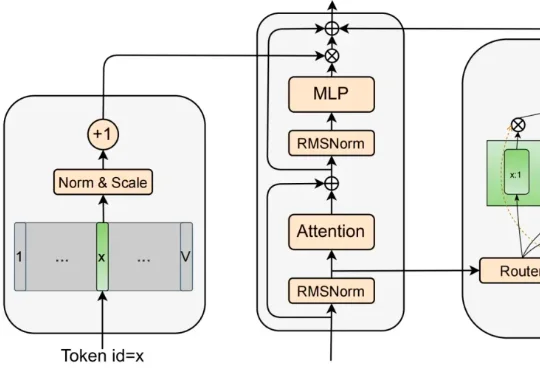
为了松绑参数与计算量,MoE 曾被寄予厚望 。它靠着稀疏激活的专家子网络,在一定程度上实现了模型容量与计算量的解耦 。然而,近期的研究表明,这并非没有代价的免费午餐 :稀疏模型通常具有更低的样本效率 ;随着稀疏度增大,路由负载均衡变得更加困难 ,且巨大的显存开销和通信压力导致其推理吞吐量往往远低于同等激活参数量的 dense 模型 。
最强的大模型,已经把scaling卷到了一个新维度:百万级上下文。

思考token在精不在多。Yuan 3.0 Flash用RAPO+RIRM双杀过度思考,推理token砍75%,网友们惊呼:这就是下一代AI模型的发展方向!
机器人领域是我们长期关注的赛道,而 Generalist 是当前机器人领域中极少数具备长期竞争潜力的公司,核心优势集中在数据规模、团队能力与清晰的 scaling 路径上。
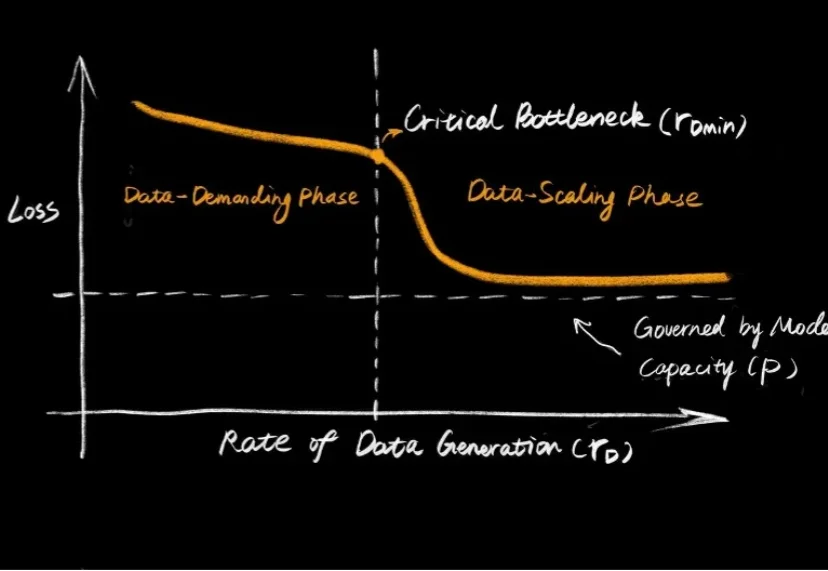
大语言模型的爆发,让大家见证了 Scaling Law 的威力:只要数据够多、算力够猛,智能似乎就会自动涌现。但在机器人领域,这个公式似乎失效了。