
字节最强多模态模型登陆火山引擎!Seed1.5-VL靠20B激活参数狂揽38项SOTA
字节最强多模态模型登陆火山引擎!Seed1.5-VL靠20B激活参数狂揽38项SOTA字节拿出了国际顶尖水平的视觉–语言多模态大模型。
来自主题: AI资讯
12388 点击 2025-05-14 16:23
 搜索
搜索
字节拿出了国际顶尖水平的视觉–语言多模态大模型。
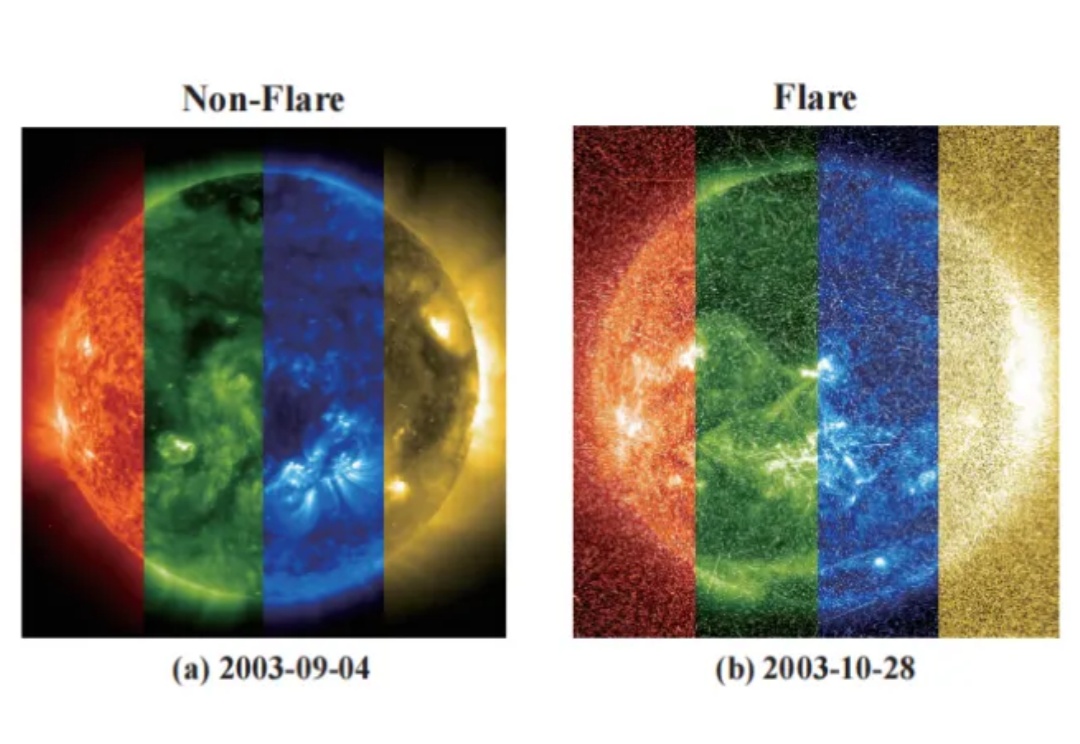
还记得刘慈欣在《全频带阻塞干扰》中描绘的耀斑爆发吗?

「矩阵」不再是科幻!Matrix-Game震撼来袭,突破边界带来交互式引擎。只需一句话,沙漠森林等任意场景可控生成,动作丝滑操控,360°视角自由切换,沉浸感爆棚。
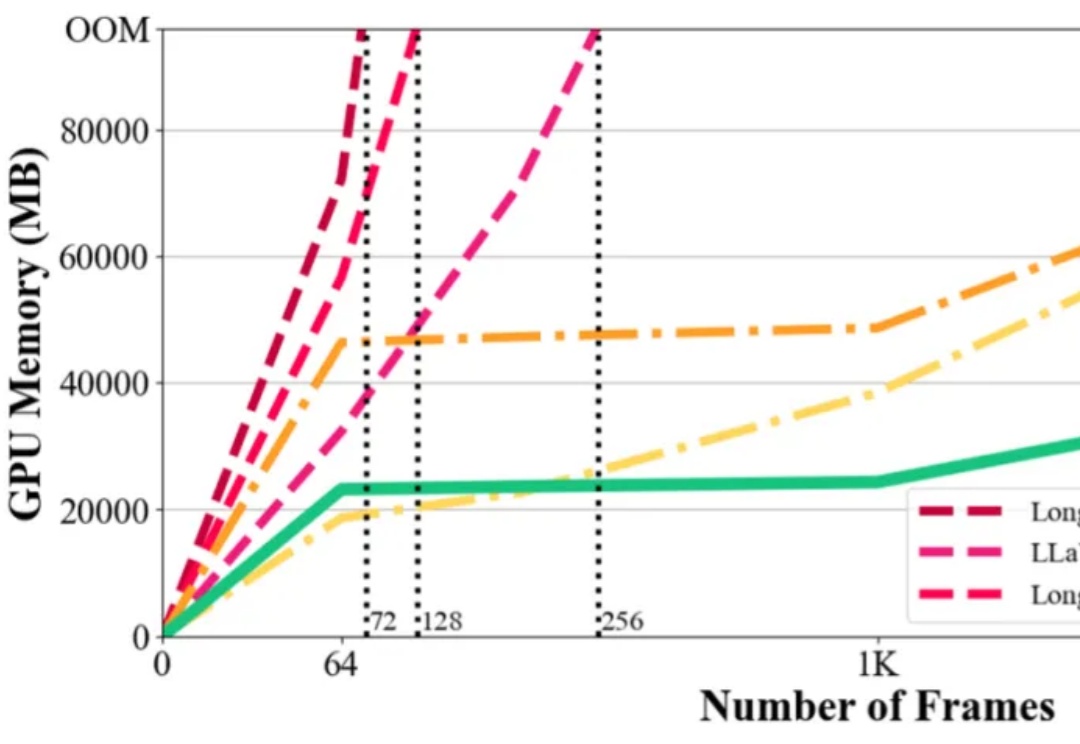
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。

字节Seed首次开源代码模型!Seed-Coder,8B规模,超越Qwen3,拿下多个SOTA。它证明“只需极少人工参与,LLM就能自行管理代码训练数据”。通过自身生成和筛选高质量训练数据,可大幅提升模型代码生成能力。

字节开源图像编辑新方法,比当前SOTA方法提高9.19%的性能,只用了1/30的训练数据和1/13参数规模的模型。
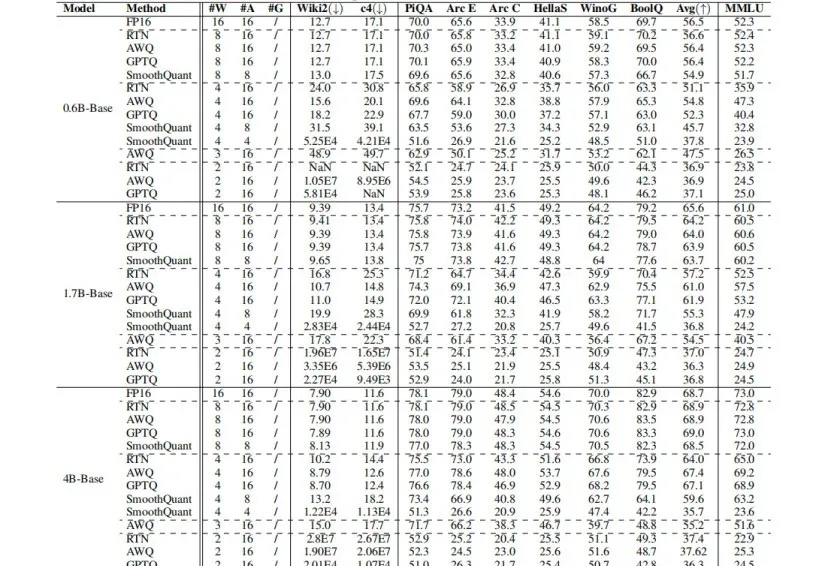
Qwen3强势刷新开源模型SOTA,但如何让其在资源受限场景中,既能实现低比特量化,又能保证模型“智商”不掉线?

昆仑自研的AI模型(SOTA)就像是“最好的锄头”,正在助力公司开采AIGC领域那片“最肥沃的金矿”。

来自英伟达和UIUC的华人团队提出一种高效训练方法,将LLM上下文长度从128K扩展至惊人的400万token SOTA纪录!基于Llama3.1-Instruct打造的UltraLong-8B模型,不仅在长上下文基准测试中表现卓越,还在标准任务中保持顶尖竞争力。
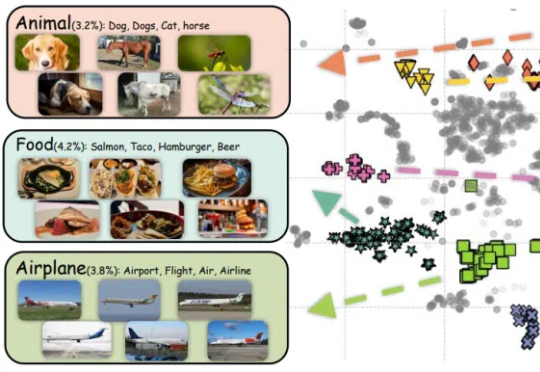
新的亿级大规模图文对数据集来了,CLIP达成新SOTA!