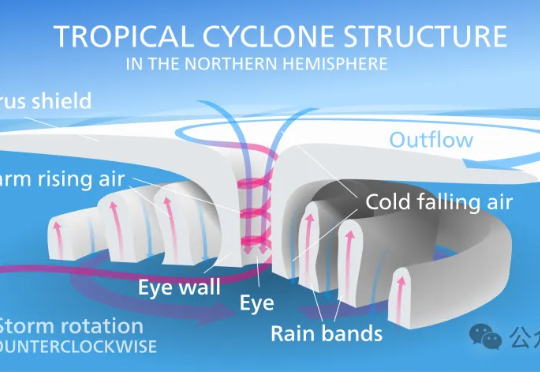
5000次风暴,谷歌训出AI预言家Weather Lab!天气预报ChatGPT时刻?
5000次风暴,谷歌训出AI预言家Weather Lab!天气预报ChatGPT时刻?昨天,谷歌DeepMind与谷歌研究团队正式推出交互式气象平台Weather Lab,用于共享人工智能天气模型。在热带气旋路径预测方面,谷歌这次的新模型刷新SOTA,是首个在性能上明确超越主流物理模型的AI预测模型。
来自主题: AI资讯
12349 点击 2025-06-13 15:24
 搜索
搜索
昨天,谷歌DeepMind与谷歌研究团队正式推出交互式气象平台Weather Lab,用于共享人工智能天气模型。在热带气旋路径预测方面,谷歌这次的新模型刷新SOTA,是首个在性能上明确超越主流物理模型的AI预测模型。

想象一下,你是一位游戏设计师,正在为一个奇幻 RPG 游戏搭建场景。你需要创建一个 "精灵族树屋村落"—— 参天古木和树屋、发光的蘑菇路灯、半透明的纱幔帐篷... 传统工作流程中,这可能需要数周时间:先手工建模每个 3D 资产,再逐个调整位置和材质,最后反复测试光照效果…… 总之就是一个字,难。

豆包大模型1.6惊艳亮相,成为国内首款多模态SOTA模型,256k对话窗口,深度思考最长上下文。它不仅能看会想,还能动手操作GUI,国内最有潜力考清北。
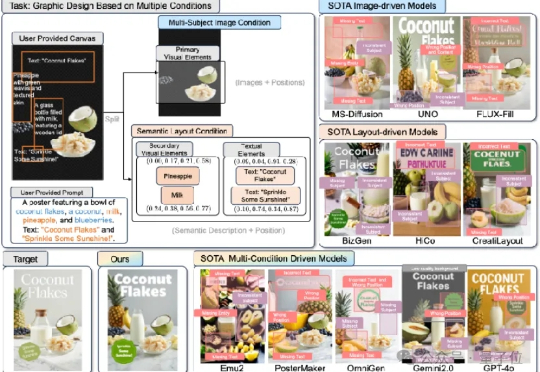
平面设计师有救了! 复旦大学和字节跳动团队联合提出CreatiDesign新模型,可实现高精度、多模态、可编辑的AI图形设计生成。
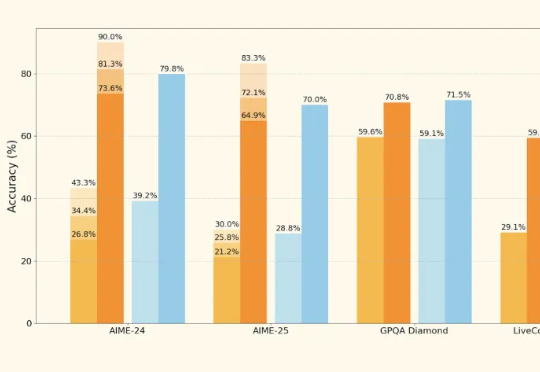
“欧洲的OpenAI”Mistral AI终于发布了首款推理模型——Magistral。 然而再一次遭到网友质疑:怎么又不跟最新版Qwen和DeepSeek R1 0528对比?

传统的视频编辑工作流,正在被AI彻底重塑。

AI模型用于工业异常检测,再次取得新SOTA!

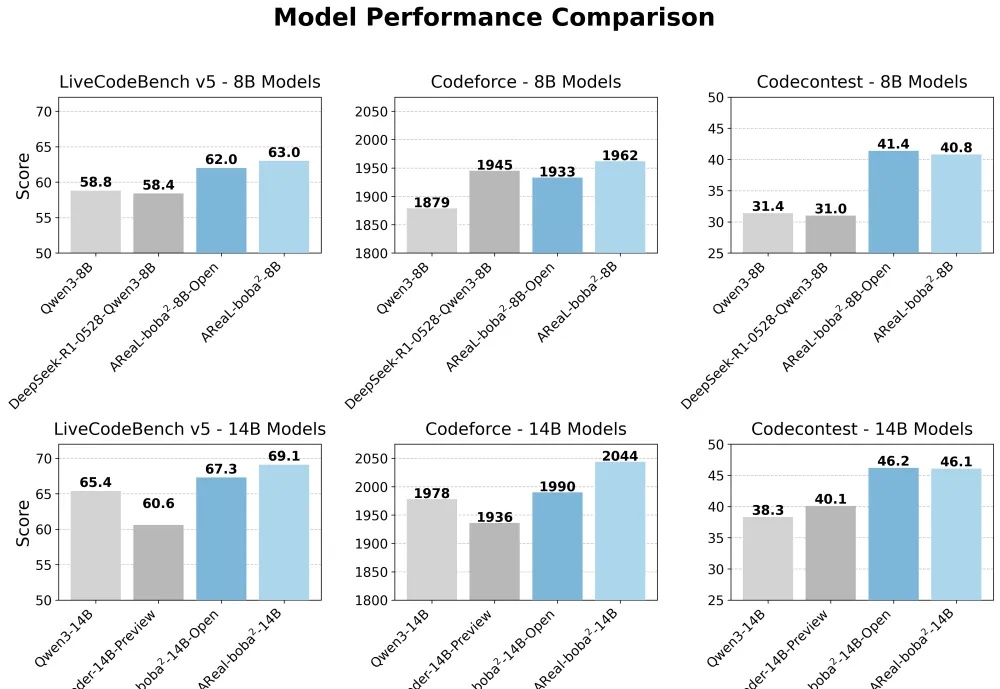
清华与蚂蚁联合开源AReaL-boba²,实现全异步强化学习训练系统,有效解耦模型生成与训练流程,GPU利用率大幅提升。14B模型在多个代码基准测试中达到SOTA,性能接近235B模型。异步RL训练上大分!
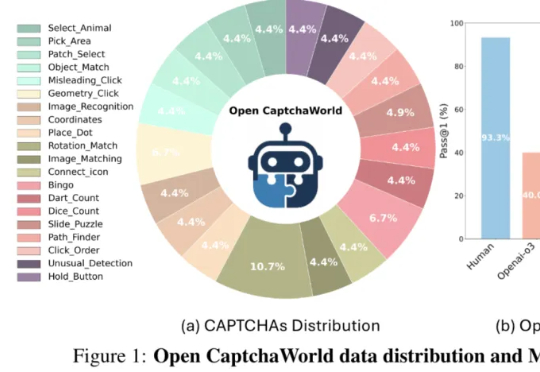
当前最强多模态Agent连验证码都解不了?
想训练属于自己的高性能推理模型,却被同步强化学习(RL)框架的低效率和高门槛劝退?AReaL 全面升级,更快,更强,更好用!