

李飞飞空间智能独角兽开源底层技术!AI生成3D世界在所有设备流畅运行空间智能的“着色器”来了
李飞飞空间智能独角兽开源底层技术!AI生成3D世界在所有设备流畅运行空间智能的“着色器”来了李飞飞空间智能创业公司World Labs,开源一项核心技术!
来自主题: AI资讯
9021 点击 2025-06-03 18:34
李飞飞空间智能创业公司World Labs,开源一项核心技术!
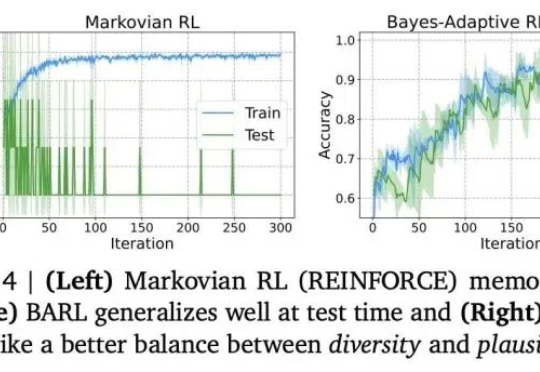
推理模型常常表现出类似自我反思的行为,但问题是——这些行为是否真的能有效探索新策略呢?
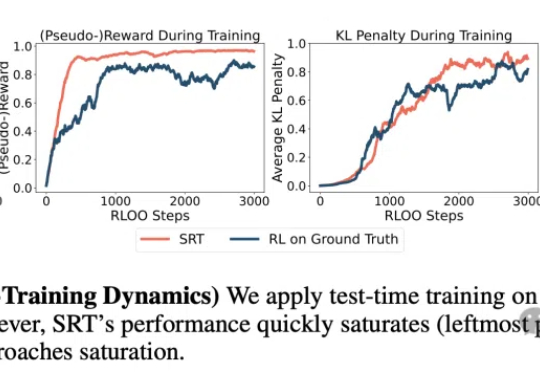
数据枯竭正成为AI发展的新瓶颈!CMU团队提出革命性方案SRT:让LLM实现无需人类标注的自我进化!SRT初期就能迭代提升数学与推理能力,甚至性能逼近传统强化学习的效果,揭示了其颠覆性潜力。

复刻DeepSeek-R1的长思维链推理,大模型强化学习新范式RLIF成热门话题。
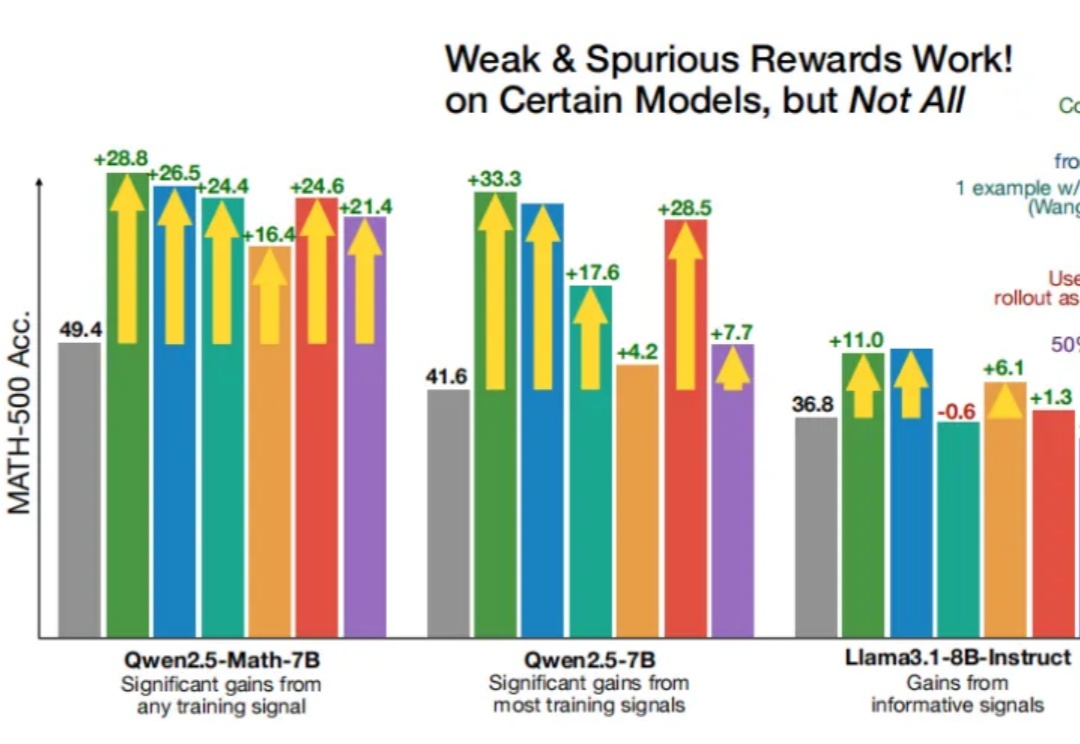
即使RLVR(可验证奖励强化学习)使用错误的奖励信号,Qwen性能也能得到显著提升?
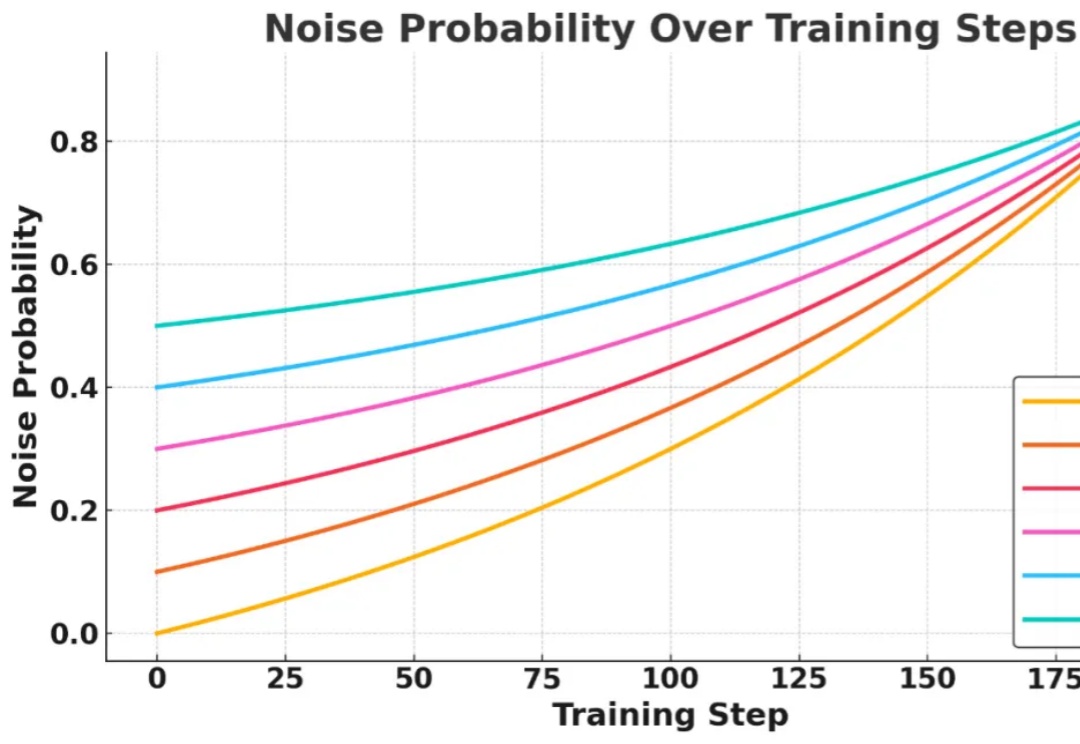
信息检索能力对提升大语言模型 (LLMs) 的推理表现至关重要,近期研究尝试引入强化学习 (RL) 框架激活 LLMs 主动搜集信息的能力,但现有方法在训练过程中面临两大核心挑战:

来自华盛顿大学、AI2、UC伯克利研究团队证实,「伪奖励」(Spurious Rewards)也能带来LLM推理能力提升的惊喜。

你有没有遇到过这样的算力困境:买了 GPU,用不了几次就闲置烧钱,偶尔想用的时候却一卡难求?
仅需一个强化学习(RL)框架,就能实现视觉任务大统一?
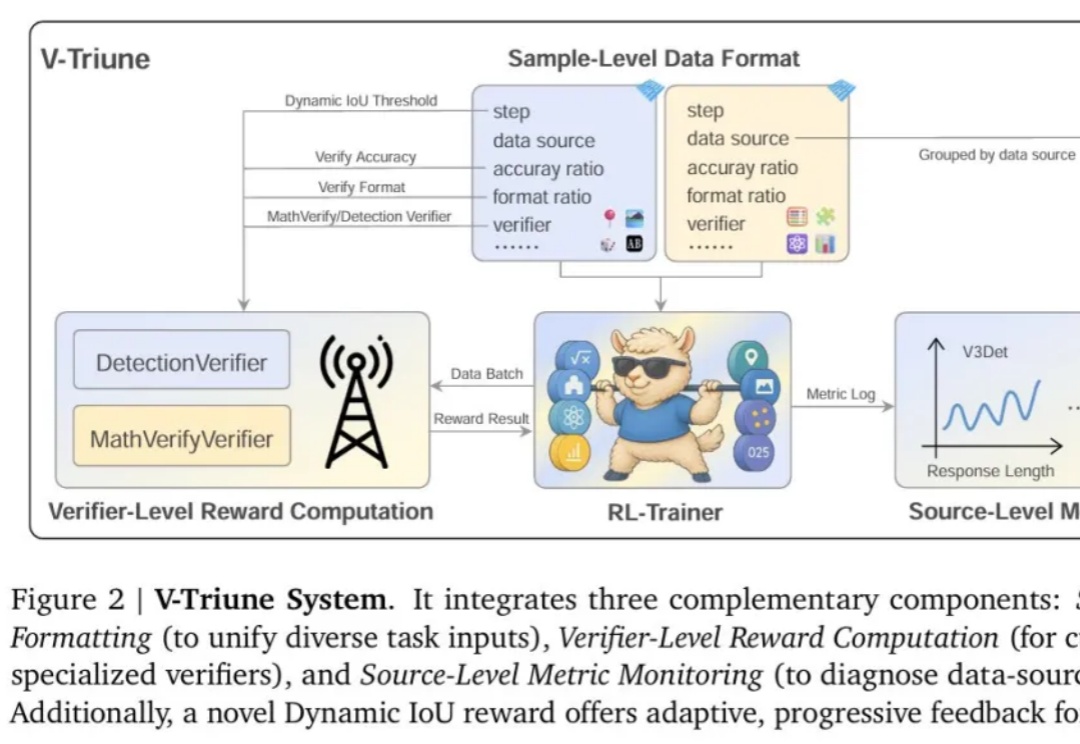
强化学习 (RL) 显著提升了视觉-语言模型 (VLM) 的推理能力。然而,RL 在推理任务之外的应用,尤其是在目标检测 和目标定位等感知密集型任务中的应用,仍有待深入探索。